
- definir o problema e escolher o tipo de IA adequado — classificação, geração de texto ou reconhecimento de imagem;
- preparar e validar o conjunto de dados de treinamento;
- selecionar a arquitetura de modelo e o framework de desenvolvimento — TensorFlow, PyTorch ou uma API de LLM;
- treinar, avaliar e ajustar o modelo com métricas como acurácia, F-score e ROC-AUC;
- realizar o deploy em produção via API REST, integração backend ou solução em nuvem.
O custo para criar uma IA varia de US$ 20.000 para soluções básicas até US$ 500.000 para sistemas especializados com 99,9% de precisão. Python é a linguagem dominante, com suporte às principais bibliotecas: TensorFlow, PyTorch, Scikit-learn, LangChain e FastAPI.
Neste guia, cobrimos cada uma dessas etapas com profundidade técnica — arquitetura de modelos, escolha de stack, estratégias de treinamento, deployment em Kubernetes e lições aprendidas em projetos reais de desenvolvimento de IA para clientes nos setores financeiro e de tecnologia.
O que é uma inteligência artificial e quais tipos existem
Inteligência artificial é um sistema computacional capaz de executar tarefas que normalmente exigiriam raciocínio humano: reconhecer padrões, gerar texto, tomar decisões com base em dados históricos e adaptar seu comportamento com base em novos inputs. Na prática de desenvolvimento, IA é um termo guarda-chuva que cobre três camadas técnicas distintas:
| Tipo | Como funciona | Casos de uso típicos | Frameworks principais |
|---|---|---|---|
| Machine Learning (ML) | Aprende padrões a partir de dados históricos sem regras explícitas | Previsão de churn, detecção de fraude, scoring de crédito | Scikit-learn, XGBoost, LightGBM |
| Deep Learning (DL) | Redes neurais com múltiplas camadas para extração automática de features | Reconhecimento de imagem, processamento de voz, NLP avançado | TensorFlow, PyTorch, Keras |
| Large Language Models (LLM) | Modelos pré-treinados em bilhões de tokens, ajustáveis por fine-tuning ou RAG | Chatbots, geração de conteúdo, agentes de IA, sumarização | OpenAI API, LangChain, Hugging Face |
| IA Generativa | Gera novos dados (texto, imagens, áudio) a partir de distribuições aprendidas | Geração de imagens, síntese de voz, criação de código | Diffusion models, GANs, GPT-based APIs |
A escolha entre essas camadas não é filosófica — é determinada pelo problema, pelo volume de dados disponíveis e pelo orçamento de infraestrutura. ML clássico com XGBoost pode superar um LLM em tarefas tabulares estruturadas, com 10x menos custo computacional. LLMs fazem sentido quando o problema envolve linguagem natural não estruturada ou quando o domínio muda rápido demais para manter um modelo supervisionado atualizado.
Passo 1: Definir o problema e escolher a arquitetura certa
O maior erro no desenvolvimento de IA não é técnico — é começar a implementar sem definir com precisão o que o modelo precisa fazer. Antes de escrever uma linha de código, responda a três perguntas:
1. Qual é o output esperado? Uma classe (classificação), um número (regressão), uma sequência de texto (geração), uma ação em um ambiente (reinforcement learning) ou uma detecção em uma imagem (visão computacional). Cada tipo mapeia diretamente para uma arquitetura de modelo.
2. Quais dados estão disponíveis e em que volume? Modelos supervisionados de ML clássico funcionam bem com milhares de exemplos rotulados. Redes neurais profundas exigem dezenas de milhares no mínimo. Fine-tuning de LLMs pode funcionar com centenas de exemplos curados — mas exige que o modelo base já conheça o domínio.
3. Qual é a latência aceitável em produção? Um modelo de inferência rodando em GPU pode responder em 50–200ms. Um modelo quantizado em CPU pode responder em 500ms–2s. Para IoT edge devices, latência é crítica e favorece modelos compactos como TinyML ou modelos destilados.
| Arquitetura | Tarefa principal | Característica técnica |
|---|---|---|
| CNN (Convolucional) | Imagens e vídeo | Extração hierárquica de features visuais; elimina ruído por pooling |
| RNN / LSTM | Sequências, séries temporais, linguagem | Memória de contexto anterior; útil para dados com dependência temporal |
| Transformer | NLP, geração de texto, código, imagens | Atenção paralela; base de todos os LLMs modernos (BERT, GPT, LLaMA) |
| GAN (Adversarial) | Geração de dados sintéticos, imagens | Dois modelos em competição: gerador vs. discriminador |
| Reinforcement Learning | Robótica, games, otimização de sistemas | Aprendizado por recompensa/punição em ambiente simulado ou real |
A estrutura de planejamento SMART aplicada ao desenvolvimento de IA funciona assim: Specific (qual exatamente a tarefa?), Measurable (qual métrica define sucesso — acurácia 95%, latência <200ms?), Achievable (os dados existem?), Relevant (o problema vale o custo?), Time-bound (qual o prazo para o MVP?). Projetos que pulam essa etapa chegam ao mês 3 com um modelo que tecnicamente funciona, mas não resolve o problema de negócio.
Passo 2: Dados — a fundação real do modelo
Um modelo de IA é tão bom quanto os dados com os quais foi treinado. Isso não é metáfora — é uma restrição matemática. Um dataset enviesado produz um modelo enviesado de forma sistemática e reproduzível, independente da sofisticação da arquitetura.
Fontes de dados e validação
Quando dados proprietários são insuficientes, plataformas como Kaggle, Common Crawl, Hugging Face Datasets e AWS Open Data Registry oferecem datasets verificados por domínio. Para validar a qualidade de um dataset próprio antes do treinamento, as ferramentas mais utilizadas na prática são:
- OpenRefine — limpeza e normalização de dados estruturados, detecção de duplicatas e inconsistências;
- Great Expectations — validação de contratos de dados em pipelines de ML; define expectativas programáticas sobre formato, distribuição e completude;
- Pandas Profiling / ydata-profiling — geração automática de relatório exploratório com distribuições, correlações e alertas de qualidade.
Os problemas mais comuns que encontramos em datasets de clientes antes de iniciar o treinamento: desbalanceamento de classes (uma categoria com 95% dos exemplos), vazamento de dados temporais (dados futuros no conjunto de treinamento), e anotações inconsistentes quando o rotulamento foi manual.
(1) distribuição de classes balanceada ou estratégia de balanceamento definida (SMOTE, undersampling, class weights);
(2) split temporal correto para dados sequenciais — nunca shuffle aleatório em séries históricas;
(3) ausência de features que "vazam" o target (ex: ID da transação correlacionado com fraude por coincidência histórica);
(4) tipos de dado corretos — datas como datetime, não strings;
(5) valores nulos tratados com estratégia explícita, não simplesmente removidos;
(6) escalonamento aplicado após o split, não antes — para evitar data leakage do conjunto de validação para o de treino.
Passo 3: Stack tecnológico — frameworks, linguagens e infraestrutura
Linguagens e bibliotecas principais
Python é a linguagem dominante no desenvolvimento de IA por razões práticas: ecossistema de bibliotecas maduro, integração nativa com frameworks de ML/DL, e suporte extensivo em cloud providers. As alternativas têm casos de uso específicos — Julia para computação científica de alta performance, R para análise estatística exploratória — mas não competem com Python em projetos de produção.
| Camada | Ferramenta | Quando usar |
|---|---|---|
| ML clássico | Scikit-learn, XGBoost 2.0, LightGBM | Dados tabulares, classificação, regressão, ranking |
| Deep Learning | PyTorch (preferível para pesquisa), TensorFlow/Keras (preferível para produção) | Visão computacional, NLP, modelos customizados |
| LLM / Agentes | LangChain, LlamaIndex, OpenAI API, Hugging Face Transformers | Chatbots, RAG pipelines, agentes autônomos |
| Feature Engineering | Featuretools, Pandas, NumPy, Dask | Geração automática de features, processamento de grandes volumes |
| API / Serving | FastAPI, BentoML, Triton Inference Server | Expor o modelo como endpoint REST/gRPC |
| Experimentos | MLflow, Weights & Biases, JupyterLab | Rastreamento de runs, comparação de hiperparâmetros, versionamento |
| Nuvem | AWS SageMaker, Google Vertex AI, Azure ML | Treinamento distribuído, deploy gerenciado, pipelines MLOps |
PyTorch vs TensorFlow: decisão prática
PyTorch domina em pesquisa e projetos com arquiteturas customizadas — o grafo dinâmico facilita debugging e experimentação. TensorFlow com TFX (TensorFlow Extended) é mais adequado quando o objetivo é um pipeline de produção padronizado: treinamento, validação, serving e monitoramento em uma única plataforma gerenciada. Para projetos que começam com um LLM base (LLaMA, Mistral, Falcon), Hugging Face Transformers abstrai ambos e reduz o tempo de setup para dias.
FastAPI como camada de serving
FastAPI é o padrão atual para expor modelos de ML como APIs REST assíncronas. Operações assíncronas nativas permitem processar múltiplas requisições de inferência em paralelo sem bloquear o event loop — crítico quando o modelo tem latência de 100–500ms por chamada. Pontos de atenção na integração: o modelo deve ser carregado uma vez no startup (não a cada requisição), o gerenciamento de memória GPU precisa ser explícito em ambientes multi-worker, e o atributo root_path exige configuração manual quando o serviço roda atrás de um proxy reverso com prefixo de URL.
Passo 4: Treinamento, avaliação e ajuste do modelo
O ciclo de treinamento de um modelo de IA segue o padrão iterações → predições → cálculo de loss → atualização de pesos → validação. A cadeia continua até que as métricas de avaliação estabilizem ou o orçamento computacional se esgote. Hiperparâmetros como learning rate, batch size e número de épocas são definidos antes do treinamento e ajustados via cross-validation ou ferramentas de hyperparameter search como Optuna.
Métricas de avaliação por tipo de problema
| Tipo de problema | Métricas principais | Quando usar cada uma |
|---|---|---|
| Classificação binária | ROC-AUC, F1-score, Precision, Recall | ROC-AUC para datasets desbalanceados (sem definir threshold); F1 quando custo de falso positivo ≠ falso negativo |
| Classificação multiclasse | Macro F1, Weighted F1, Confusion Matrix | Macro F1 quando todas as classes têm igual importância; Weighted F1 para classes com volumes diferentes |
| Regressão | MSE, RMSE, MAE, R² | RMSE penaliza outliers mais que MAE; R² indica proporção da variância explicada pelo modelo |
| NLP / Geração | BLEU, ROUGE, BERTScore, Perplexity | BERTScore captura similaridade semântica melhor que BLEU/ROUGE para avaliação de LLMs |
Um erro dentro de 5% (MSE relativo) é considerado aceitável para a maioria das aplicações comerciais. Precisão abaixo de 1% justifica infraestrutura dedicada de GPU e processos de validação mais rigorosos — como testes de invariância e testes de robustez contra inputs adversariais.
Tipos de treinamento: supervisionado, não-supervisionado e por reforço
O treinamento supervisionado — com dados rotulados — é o padrão para a maioria das aplicações comerciais: classificação de documentos, previsão de demanda, detecção de anomalias com exemplos históricos. O não-supervisionado (clustering, autoencoders) é usado quando não há labels disponíveis e o objetivo é descobrir estrutura nos dados. O treinamento por reforço — onde o modelo aprende por recompensa e punição em um ambiente — é aplicado em robótica, otimização de rotas e sistemas de recomendação adaptativos; exige mais tempo e infraestrutura de simulação, mas é a única abordagem viável quando não existe dataset histórico para o comportamento desejado.
Passo 5: RAG vs Fine-tuning — quando usar cada estratégia
Ao trabalhar com LLMs, a decisão entre RAG (Retrieval-Augmented Generation) e fine-tuning é uma das mais impactantes na arquitetura do sistema. Não é uma escolha técnica — é operacional.
RAG: quando faz sentido
RAG é a escolha certa quando os dados que fundamentam as respostas mudam com frequência: catálogos de produtos, bases de conhecimento corporativas, históricos de transações, feeds de notícias. A arquitetura básica funciona em três etapas: (1) os documentos são segmentados em chunks e transformados em embeddings vetoriais armazenados em um vector database (Pinecone, Weaviate, pgvector); (2) a query do usuário é também convertida em embedding e os chunks mais similares são recuperados; (3) o LLM gera a resposta com base nesses chunks como contexto adicional.
O método RAG aproxima vetores e semântica segmento por segmento com base em contexto e relevância — em vez de sobrecarregar o contexto do modelo com todo o corpus. Isso reduz custo de tokens, aumenta precisão e torna o sistema auditável.
Fine-tuning: quando é justificado
Fine-tuning faz sentido em dois cenários específicos: quando o modelo base não domina a terminologia de um domínio muito especializado (linguagem jurídica específica de um país, protocolos médicos proprietários, linguagem interna de uma organização) ou quando o estilo de resposta precisa ser radicalmente diferente do padrão do modelo base. O processo inclui normalização dos dados de treinamento, tokenização para o formato do modelo específico, e — para modelos grandes — técnicas de Parameter-Efficient Fine-Tuning como LoRA ou QLoRA que ajustam apenas uma fração dos pesos, reduzindo custo computacional em 60–80%.
Caso real: arquitetura de um agente de IA para plataforma financeira
Em um projeto de desenvolvimento de agente de IA integrado a uma plataforma de exchange de criptomoedas, estruturamos a arquitetura em seis módulos funcionais independentes — cada um com escopo de prompt separado e sua própria lógica de validação de intenção. O desafio central não era o modelo em si, mas a confiabilidade: o agente opera com dinheiro real, e alucinações têm custo financeiro direto.
Módulo de conversão (spot wallet): o agente verifica o saldo disponível antes de executar qualquer operação. Sem saldo confirmado na camada de intent, a operação é bloqueada antes de chegar ao backend de trading — isso elimina chamadas desnecessárias à API e previne ordens com saldo insuficiente geradas por ambiguidade de linguagem.
Módulo de ordens: suporte a limit orders (abertura e fechamento) e operações de mercado no spot. A separação entre "limit" e "market" no fluxo de NLP foi crítica — usuários usam linguagem ambígua ("compra isso agora" vs. "compra quando chegar a X"), e o classificador de intenção precisa resolver essa ambiguidade antes de chamar qualquer endpoint de execução.
Módulo de histórico com RAG: geração de resposta com transações detalhadas. O histórico de um usuário ativo pode ter centenas de entradas — carregar tudo no contexto do LLM é inviável por custo e latência. Implementamos RAG: o agente recupera por embedding search apenas as transações relevantes para a query específica do usuário.
Módulo de saque com whitelist: o modelo deve associar nomes em linguagem natural ("envie para João") a endereços de carteira armazenados. Isso exigiu uma camada de entidade de usuário separada do contexto conversacional — uma lookup table de nomes → endereços validados, consultada antes de qualquer chamada ao LLM.
O routing entre módulos é feito por um classificador leve (fine-tuned BERT ou modelo de classificação simples) antes de chegar ao LLM principal — isso reduz latência média em 40% e previne que o modelo tente executar operações financeiras quando o usuário está apenas fazendo uma pergunta sobre o mercado.
Passo 6: Containerização e deployment em produção
O processo de containerização começa quando todos os componentes da aplicação de IA estão prontos — código, dependências, frameworks e configurações de ambiente. Um container Docker abstrai o modelo do host e garante que o ambiente de produção seja idêntico ao de desenvolvimento: sem "funciona na minha máquina".
Docker e Kubernetes para modelos de IA
Docker Engine com imagens Linux é o padrão para packaging de modelos. Kubernetes (K8s) é a plataforma de orquestração para deployment em escala — mas exige atenção específica para componentes de IA que o deployment de aplicações web convencionais não tem.
Um modelo de inferência que carrega pesos de 2–7B parâmetros na memória GPU tem dependências de estado que tornam o escalonamento horizontal não trivial. O Horizontal Pod Autoscaler (HPA) do Kubernetes funciona bem para API Gateway e serviços de notificação — mas para o modelo de inferência, a política de scaling deve ser baseada em tamanho de fila de requisições (via KEDA + Redis), não em CPU/RAM. Pods duplicados durante warm-up introduzem inconsistências de resposta e desperdiçam recursos de GPU.
Configuração prática que implementamos:
- Serviço de inferência: custom metric scaling via KEDA + Redis queue depth;
- Separação explícita entre stateless services (API, logging, notificações) e stateful (model inference, wallet manager, matching engine);
- Helm charts com
minReplicas: 1garantido para o modelo em produção — nunca scale-to-zero para serviços com latência de cold start >10s; - HashiCorp Vault para secrets management integrado ao pipeline CI/CD (GitLab CI);
- Redpanda (compatível com Kafka) como message bus para comunicação assíncrona entre microsserviços.
Plataformas de deploy e ferramentas de teste
Para projetos sem infraestrutura Kubernetes própria, as opções gerenciadas reduzem significativamente a carga operacional: AWS Elastic Beanstalk e Google Cloud Run para APIs de inferência stateless; AWS SageMaker e Google Vertex AI para pipelines de treinamento e serving completos com monitoramento integrado; Heroku para MVPs e protótipos onde a simplicidade operacional supera o custo.
A pipeline de testes para modelos de IA em produção tem três camadas obrigatórias: testes unitários automatizados (PyTest) para validar componentes individuais do pipeline; testes de integração periódicos para avaliar o comportamento do modelo com dados reais do ambiente de staging; e testes de carga (Locust) para verificar latência e throughput sob volume de requisições representativo do pico esperado.
Passo 7: Segurança, privacidade e defesa cibernética
Aplicações de IA em produção têm vetores de ataque específicos que não existem em software convencional. Conhecê-los antes do deployment é obrigatório — corrigir vulnerabilidades de IA em produção é significativamente mais complexo do que em código.
Principais vetores de ataque em sistemas de IA
- Envenenamento de dados (data poisoning): introdução de exemplos maliciosos no dataset de treinamento para manipular o comportamento do modelo de forma sistemática e difícil de detectar;
- Ataques adversariais: inputs especialmente construídos para enganar o modelo com alta confiança — imagem de um stop sign com stickers que o modelo classifica como speed limit;
- Prompt injection: em sistemas baseados em LLMs, instruções maliciosas embutidas em dados do usuário que redefinem o comportamento do modelo;
- Model inversion: técnicas para reconstruir dados de treinamento a partir do modelo — risco crítico quando o dataset contém dados sensíveis de usuários.
Conformidade com LGPD, GDPR e CCPA
No contexto brasileiro, a LGPD (Lei Geral de Proteção de Dados) impõe requisitos específicos sobre o uso de dados pessoais em sistemas de IA: base legal explícita para o processamento, direito à explicabilidade das decisões automatizadas, e proibição de decisões automatizadas exclusivas em contextos de impacto significativo ao titular. As medidas técnicas necessárias incluem anonimização dos dados de treinamento antes do uso, diferenciação de campos sensíveis (CPF, e-mail, telefone) com criptografia específica, e — para modelos expostos a usuários — implementação de mecanismos de explicabilidade (SHAP, LIME) que permitam auditar as decisões do modelo.
(1) anonymização do dataset antes do treinamento, com verificação de re-identificação;
(2) differential privacy no treinamento quando o dataset contém dados pessoais sensíveis;
(3) input validation rigorosa antes de cada chamada ao modelo — comprimento máximo, filtros de conteúdo, detecção de prompt injection para LLMs;
(4) output validation para verificar que respostas geradas não expõem dados de treinamento;
(5) rate limiting e autenticação nas APIs de inferência — modelos expostos sem auth são atacados por web scrapers e replicados;
(6) monitoramento de drift — quando a distribuição dos inputs muda, o comportamento do modelo muda de formas inesperadas.
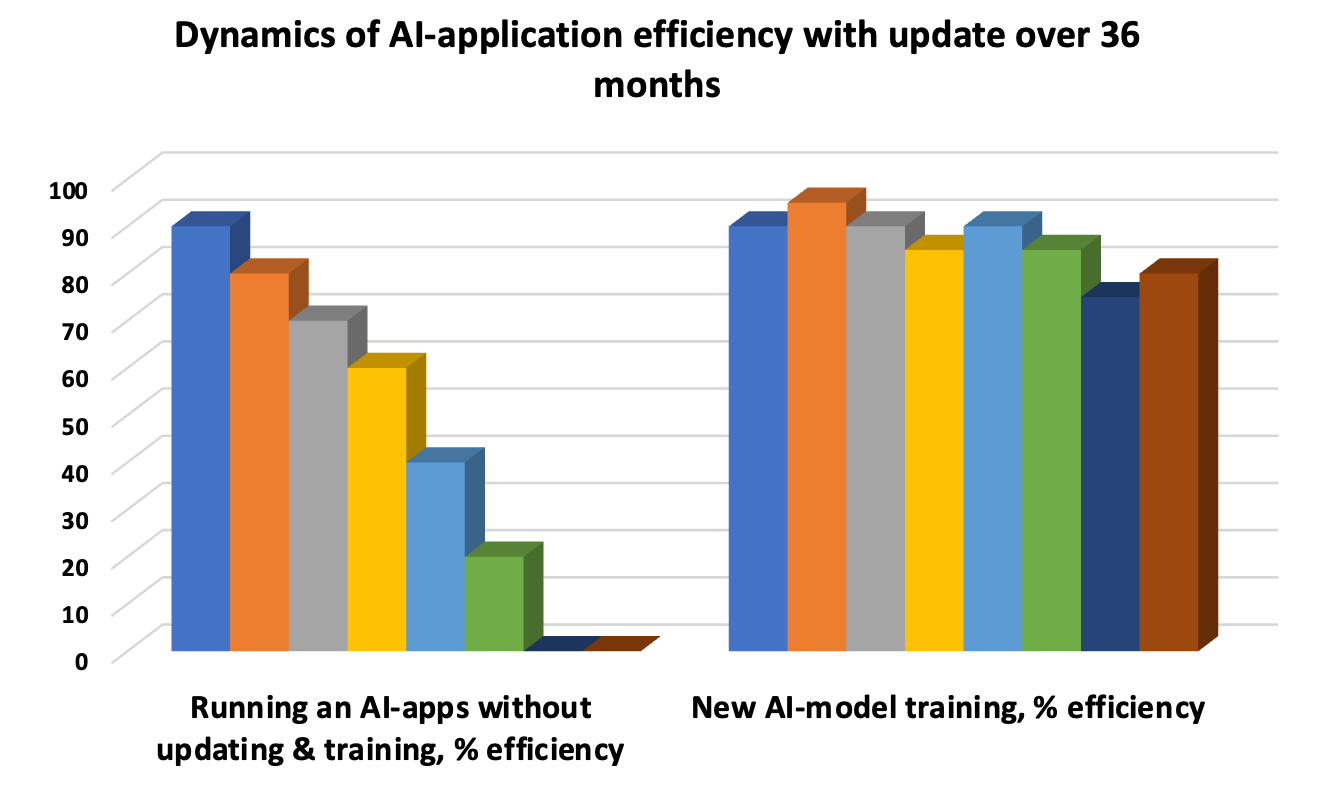
Passo 8: Monitoramento, atualização e ciclo de vida do modelo
Um modelo de IA em produção não é um artefato estático. Os padrões que ele aprendeu refletem a distribuição dos dados no momento do treinamento — quando o mundo muda, o modelo fica desatualizado e sua acurácia degrada silenciosamente. Esse fenômeno tem nome técnico: model drift (ou concept drift).
Existem dois tipos de drift que precisam ser monitorados separadamente: data drift, quando a distribuição dos inputs muda (ex: novos formatos de documento, novo vocabulário dos usuários); e concept drift, quando a relação entre inputs e outputs muda (ex: comportamentos de fraude evoluem para contornar o modelo treinado nos padrões anteriores).
A metodologia CRISP-DM (Cross-Industry Standard Process for Data Mining) define um ciclo de vida iterativo para modelos de ML em produção: entendimento do negócio → entendimento dos dados → preparação → modelagem → avaliação → deployment → monitoramento → volta ao início. Para aplicações de IA com vida útil de 3–5 anos, atualizações trimestrais dos datasets de treinamento e retreinamentos semestrais são o mínimo viável.
As três camadas de teste obrigatórias para manutenção contínua: testes unitários automatizados para regressões em componentes individuais do pipeline; testes de integração periódicos para avaliar o comportamento agregado do sistema; e testes de aceitação (UAT) com usuários reais ou dados de produção anonimizados antes de cada atualização de modelo.
Quanto custa criar uma IA: benchmarks reais por complexidade
O custo de desenvolvimento de uma aplicação de IA varia em função da complexidade do modelo, do volume de dados que precisam ser preparados, da arquitetura de infraestrutura e do nível de precisão exigido. Os benchmarks abaixo refletem projetos reais de desenvolvimento — não estimativas teóricas.
| Nível de complexidade | Descrição | Custo estimado | Prazo típico |
|---|---|---|---|
| Básico | Chatbot com NLP simples, classificador binário, integração de API de LLM existente (OpenAI, Anthropic) com RAG | US$ 20.000 – 40.000 | 6 – 10 semanas |
| Médio | Agente de IA com múltiplos módulos funcionais, pipeline de ML com feature engineering customizado, integração a sistemas legados | US$ 40.000 – 100.000 | 3 – 5 meses |
| Alto | Modelo treinado do zero ou fine-tuning de LLM em domínio especializado, infraestrutura de ML em produção com Kubernetes e MLOps | US$ 100.000 – 300.000 | 5 – 8 meses |
| Enterprise | Sistema de IA com 99,9% de precisão exigida, análise especializada, múltiplos modelos em pipeline, conformidade regulatória | US$ 300.000 – 500.000+ | 8 – 14 meses |
O primeiro entregável após o desenvolvimento deve ser sempre um MVP funcional com escopo reduzido — não uma plataforma completa. O MVP permite validar a premissa do modelo com dados reais de produção antes de investir na infraestrutura completa. O aprendizado do MVP frequentemente muda as prioridades do roadmap de forma significativa.
Como criar uma IA para negócios: aplicações por setor
A mesma infraestrutura técnica se manifesta de formas muito diferentes dependendo do domínio. Abaixo, os casos de uso com maior retorno sobre investimento que observamos em projetos de clientes.
IA no setor financeiro e de trading
Detecção de fraude em tempo real com modelos de classificação binária treinados em histórico de transações; scoring de crédito com modelos de regressão logística e XGBoost; agentes de IA para operações de exchange (conversão de ativos, ordens, histórico, saques) com NLP e intent classification; análise de sentimento de mercado a partir de feeds de notícias e redes sociais com Transformer-based models.
IA em logística e cadeia de suprimentos
Previsão de demanda com modelos de séries temporais (Prophet, LSTM, N-BEATS); otimização de rotas com algoritmos de reinforcement learning ou heurísticas combinatórias; detecção de anomalias em estoque com modelos de clustering e autoencoders; previsão de falhas em equipamentos com modelos treinados em dados de sensores IoT.
IA em atendimento e NLP
Chatbots com intenção de múltiplos níveis usando LLMs com RAG sobre base de conhecimento corporativa; classificação automática de tickets de suporte; análise de sentimento de feedback de clientes; extração de informações estruturadas de documentos não-estruturados (contratos, notas fiscais, formulários) com modelos de NER (Named Entity Recognition).
IA em recrutamento e RH
Triagem inicial de candidatos com modelos de NLP treinados em descrições de cargo e currículos; identificação de skills em perfis de LinkedIn e documentos não-estruturados; matching semântico entre vagas e candidatos com embedding-based similarity. A limitação técnica importante: modelos treinados em dados históricos de contratação reproduzem os vieses históricos — auditoria de fairness com ferramentas como IBM AI Fairness 360 é obrigatória antes do deploy.
FAQ
É possível criar uma IA sem saber programar?
Para soluções simples baseadas em APIs de LLM existentes (ChatGPT, Claude, Gemini), plataformas no-code como Voiceflow, Botpress ou Make (Integromat) permitem construir chatbots e automações sem código. Para qualquer sistema com modelo próprio — treinamento, fine-tuning, pipeline de dados, deployment — conhecimento de Python e conceitos de ML são necessários. A distinção prática: integrar uma API de IA existente não é criar uma IA; é usar uma IA criada por outros.
Qual a diferença entre machine learning e inteligência artificial?
IA é o conceito mais amplo — qualquer sistema que simula inteligência humana. Machine learning é um subconjunto de IA que aprende padrões a partir de dados sem regras explícitas programadas. Deep learning é um subconjunto de ML que usa redes neurais com múltiplas camadas. LLMs como GPT-4 são um tipo específico de deep learning baseado em arquitetura Transformer. Na prática: todo ML é IA, mas nem toda IA usa ML — sistemas baseados em regras explícitas (expert systems) também são IA, tecnicamente.
Quanto tempo leva para criar uma IA do zero?
Depende fundamentalmente da complexidade. Um chatbot baseado em API de LLM com RAG pode estar em produção em 4–8 semanas. Um modelo de classificação customizado com dataset próprio leva 2–4 meses incluindo coleta de dados, treinamento e validação. Um sistema de IA enterprise com fine-tuning, infraestrutura MLOps e conformidade regulatória leva 6–14 meses. O maior gargalo na maioria dos projetos não é o desenvolvimento do modelo — é a preparação e validação dos dados.
Python é obrigatório para desenvolver IA?
Python é a escolha dominante e pragmática — o ecossistema de bibliotecas (TensorFlow, PyTorch, Scikit-learn, LangChain, Hugging Face) foi construído primariamente para Python. Alternativas existem: R para análise estatística exploratória, Julia para computação científica de alta performance, JavaScript (TensorFlow.js) para inferência no browser. Em produção, o modelo treinado em Python pode ser servido via API e consumido por qualquer linguagem — Go, Java, C# — para integração com sistemas existentes.
Qual a diferença entre RAG e fine-tuning?
RAG (Retrieval-Augmented Generation) injeta conhecimento externo em tempo real no contexto do LLM antes de gerar a resposta — sem modificar os pesos do modelo. Fine-tuning modifica os pesos do modelo treinando-o em dados adicionais específicos do domínio. RAG é melhor quando os dados mudam com frequência ou quando você precisa citar fontes específicas. Fine-tuning é melhor quando o modelo precisa aprender um estilo de resposta específico ou terminologia que não existe nos dados de pré-treinamento. As duas abordagens podem ser combinadas.
Como garantir que minha IA não viola a LGPD?
Os requisitos técnicos mínimos para conformidade com a LGPD em sistemas de IA incluem: base legal documentada para cada categoria de dado pessoal usada no treinamento, anonimização ou pseudonimização do dataset antes do treinamento, mecanismos de explicabilidade para decisões automatizadas com impacto ao titular, e direito ao esquecimento implementado tecnicamente (capacidade de remover um indivíduo do dataset e retreinar ou usar técnicas de machine unlearning). Decisões automatizadas exclusivas com impacto significativo ao titular são proibidas sem revisão humana.
Vale a pena criar uma IA própria ou usar uma API existente?
A regra prática: use APIs existentes (OpenAI, Anthropic, Google Gemini) quando o problema pode ser resolvido por um LLM de propósito geral com customização via prompt ou RAG. Crie um modelo próprio quando: (1) os dados são altamente proprietários e não podem ser enviados a terceiros; (2) o domínio é tão específico que LLMs gerais falham consistentemente; (3) o volume de requisições torna o custo por token de APIs externas inviável economicamente — o breakeven com inferência própria em GPU geralmente ocorre em torno de 1–5 milhões de chamadas por mês.
O que é MLOps e por que é necessário?
MLOps é a disciplina que aplica práticas de DevOps ao ciclo de vida de modelos de ML: versionamento de dados e modelos (DVC, MLflow), pipelines de CI/CD para retreinamento automático, monitoramento de data drift e model drift em produção, e registro de experimentos para reprodutibilidade. Sem MLOps, projetos de IA em produção acumulam dívida técnica rapidamente: modelos sem versionamento, ambientes de treinamento não reproduzíveis, ausência de alertas quando o modelo degrada. MLOps transforma IA de experimento em produto sustentável.







