
- Desenvolvimento de inteligência artificial (IA) é o processo de criar sistemas de software capazes de executar tarefas que normalmente exigem inteligência humana: reconhecimento de padrões, tomada de decisão, processamento de linguagem natural e automação de processos complexos.
- Do ponto de vista técnico, um projeto de IA moderno envolve quatro camadas principais: (1) coleta e preparação de dados, (2) seleção e treinamento do modelo — com técnicas como machine learning, deep learning ou fine-tuning de LLMs, (3) construção da infraestrutura de deployment — geralmente em microserviços com orquestração via Kubernetes, (4) integração via API no produto final.
- Os principais casos de uso comercial incluem: agentes autônomos para fintech e crypto, sistemas de reconhecimento e verificação (KYC/KYT), chatbots com NLP avançado, plataformas de análise preditiva e modelos de decisão em tempo real.
- O custo de desenvolvimento varia conforme a abordagem: fine-tuning de um modelo open-source existente começa em US$ 500–1.000 para aplicações simples; sistemas com arquitetura de agentes autônomos e infraestrutura Kubernetes ficam na faixa de US$ 30.000–150.000+, dependendo da complexidade.
Aplicações e redes neurais: o que realmente está por trás de um sistema de IA
Modelos e algoritmos baseados em IA — aplicativos, chatbots e agentes autônomos — são desenvolvidos com machine learning e deep learning para analisar dados digitais e executar ações. Para projetos de maior complexidade, como plataformas financeiras ou sistemas de reconhecimento em tempo real, conectam-se redes neurais profundas com arquitetura especializada.
A visualização computacional usa redes convolucionais (CNN) para reconhecimento e visão 3D. O processamento de linguagem natural (NLP) depende de transformers — a arquitetura que está na base de todos os LLMs modernos, do GPT-4 ao LLaMA. Aplicativos bancários prospectivos, pré-seleção de candidatos, diagnóstico clínico inicial e geração de conteúdo multimídia — todos operam sobre variações desse mesmo stack técnico.
Agente de IA como produto: arquitetura além do chatbot
Desenvolvimento de um agente autônomo de IA para aplicações financeiras é fundamentalmente diferente de um chatbot de atendimento. O NLP é apenas um dos layers — o mais visível, mas não o mais crítico.
Em um de nossos projetos, desenvolvemos um agente autônomo integrado a uma exchange de criptomoedas. O agente precisava processar seis tipos de operações distintas: conversão de ativos (spot balance → API da exchange → confirmação), ordens limitadas e a mercado, histórico detalhado de transações, geração de endereço de depósito dinâmico, saque para endereços em whitelist e modo de análise de notícias e tendências de mercado.
Essa é a diferença fundamental entre um agente de produção e um protótipo de demonstração: segurança construída em nível de arquitetura, não de prompt. O stack técnico incluiu um LLM com fine-tuning para terminologia financeira, integração REST com a API da exchange, módulo de validação whitelist e fila assíncrona de transações com retry logic.
Reconhecimento, verificação e KYC: IA em compliance financeiro
Reconhecimento de documentos com redes neurais é treinado por análise de imagens com adaptação e verificação, formando uma resposta de API que pode ser integrada a qualquer CRM, chatbot ou painel de usuário. Para agências de viagens, o caso típico é reconhecimento de passaportes e documentos de viajantes com taxa de erro entre 1–5%.
Em plataformas financeiras, o nível de exigência é significativamente maior. Em nossos deployments, implementamos fluxos KYC com suporte a duas rotas paralelas de verificação: upload de documento padrão para usuários internacionais e verificação via aplicativo de identidade digital do governo para usuários locais. Cada provedor tem payloads de webhook e transições de status diferentes, o que exige manter duas state machines de verificação separadas no backend.
Um mecanismo mais sofisticado que desenvolvemos é a regeneração forçada de carteiras: quando um endereço de depósito é marcado como arriscado — pelo sistema de AML scoring ou manualmente — o sistema gera automaticamente novos endereços para todas as redes suportadas e aposenta o endereço sinalizado. Qualquer depósito futuro no endereço antigo é rejeitado ou colocado em quarentena. A implementação exige arquitetura event-driven com estado persistente por par wallet/network.
Modelagem de decisão com Data Science e ML
Construir bancos de dados e expô-los à IA não é suficiente: é preciso ensinar o sistema a reconhecer situações onde a resposta precisa ser rápida e determinística — casos onde bancos relacionais não conseguem encontrar a solução certa. Analistas de Data Science definem os algoritmos e as condições do modelo matemático:
- modelagem de processos com identificação de dependências causais;
- segmentação e personalização de clientes por vetores de comportamento;
- relevância de ofertas em tempo real com modelos de recomendação.
Para modelagem supervisionada, usam-se regressão linear e multivariada, support vector machines, decision trees com subcategorias e KNN. O aprendizado por reforço aplica-se a sistemas de controle e robótica. A comunicação de chatbots é resultado de Transformers após processamento de linguagem humana — a mesma arquitetura base do GPT, BERT e seus derivados.
Microserviços e Kubernetes: a infraestrutura real de uma plataforma de IA
Quando um cliente contrata "desenvolvimento de uma plataforma de IA", o que ele visualiza é a interface. O que está por baixo são tipicamente 15 a 20 microserviços, cada um com responsabilidade isolada.
Uma distinção crítica que equipes novas em Kubernetes costumam ignorar: nem todos os serviços devem ter autoscaling. Serviços com ordered state — order book, wallet manager, matching engine — têm dependências stateful que tornam o escalonamento horizontal não trivial. Serviços stateless (API gateway, notification service) escalam livremente. Definir essa fronteira antes de escrever os Helm charts economiza semanas de refatoração.
Fine-tuning de LLM com PEFT: quando treinar do zero não faz sentido
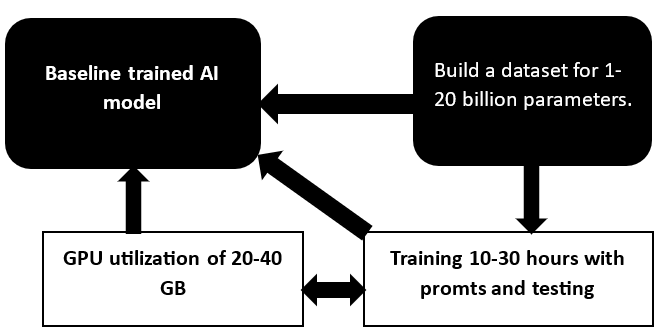
A versatilidade dos modelos GPT e seus equivalentes open-source depende de prompt engineering, customização para questões específicas e poder computacional. Uma empresa envolvida em treinamento de modelos de IA opera com dezenas ou centenas de GPUs, responsáveis por processar e computar informações por 10 a 30 dias, dependendo da complexidade.
PEFT (Parameter-Efficient Fine-Tuning) é a solução prática para 80% dos projetos comerciais de IA. O método "congela" a maior parte dos parâmetros do modelo base e treina apenas o subconjunto relevante. O resultado: custo computacional 5–10× menor que treinamento completo, com qualidade equivalente para tarefas especializadas.
Para domínios financeiros e cripto, um modelo 13B fine-tuned supera consistentemente o GPT-3.5-turbo em precisão em testes domain-specific, com custo de inference significativamente menor. O pipeline de produção que utilizamos: JupyterHub para experimentação → MLflow para versionamento de experimentos → MLflow Deploy para empacotamento e deployment.
A escolha entre PEFT e RAG (Retrieval-Augmented Generation) depende da natureza da tarefa. Se o objetivo é que o modelo "conheça" um estilo, terminologia ou lógica de domínio — fine-tuning. Se o objetivo é dar respostas precisas com base em documentos específicos que se atualizam frequentemente — RAG é mais eficiente e barato de manter. Sistemas de produção complexos frequentemente combinam as duas abordagens.
Modelos simplificados open-source com limites de input relativamente baixos apresentam resultados elevados em benchmarks. O preço de treinamento de aplicações simples baseadas em GPT-4 ou LLaMA começa em US$ 500–1.000. Cada base é relativamente fácil de customizar para obter uma aplicação proprietária melhor do que soluções pagas genéricas.
Autonomia e tomada de decisão: os limites reais da IA
Um computador não busca soluções ou realiza pesquisas sem uma tarefa. Mesmo quando programado condicionalmente como uma "personalidade", sem uma instrução o sistema não executa ações específicas. A lógica formal não é suficiente aqui — é necessário matemática e estatística.
As decisões tomadas autonomamente pela IA devem ser analisadas: se ultrapassam os limites dos algoritmos e scripts configurados, mas representam uma opção preferível dentro dos parâmetros de segurança, isso confirma que a "autonomia" está funcionando corretamente.
Três níveis de IA quanto à autonomia:
- ANI (Artificial Narrow Intelligence) — executor típico que não ultrapassa as tarefas escritas no programa;
- AGI (Artificial General Intelligence) — nível próximo ao pensamento humano médio; ainda é objetivo de pesquisa, não produto;
- ASI (Artificial Superintelligence) — nível teórico que se assemelha e potencialmente supera o pensamento humano.
Nos sistemas de produção atuais, trabalhamos exclusivamente com ANI — mas dentro dessa categoria, a sofisticação varia enormemente: desde um classificador binário até um agente com múltiplas ferramentas capaz de executar transações financeiras reais.
Treinamento de redes neurais: deep learning e infraestrutura GPU
Programadores e desenvolvedores treinam neurônios artificiais para resolver problemas usando métodos de deep learning. Isso inclui algoritmos de NLP para processamento de linguagem, significado e tom, e IA generativa cujos artefatos de áudio, vídeo e texto são indistinguíveis de produções humanas em qualidade média.
As plataformas de treinamento — "escolas" para IA — incluem TensorFlow, PyTorch e a biblioteca open-source Scikit-learn em Python. No nível de modelagem, define-se a capacidade da rede, depois segmentação por camadas e funções de ativação.
Desenvolvedores analisam como neurônios alteram os pesos de seus vizinhos durante a comunicação e estimam os bias nodes. Para minimizar a diferença entre previsão e dados reais, usa-se a função de perda (loss function), com otimizadores como gradiente descendente ou sequências de gradiente adaptativas (Adam, RMSprop) que consideram mínimos, máximos e velocidade de mudança.
Revolução multimodal e arquitetura de dados
Ter modelos de IA com informações base disponíveis simplifica o trabalho de treinamento e deployment de múltiplas unidades dentro de um mesmo circuito de serviço. A validação dos dados do dataset é crítica: precisão e validade determinam a integridade de todo o sistema.
O paradigma da multimodalidade conecta todos os tipos de informação — texto, imagem, áudio, vídeo — em uma única entidade de processamento. Desenvolvedores experientes frequentemente oferecem soluções combinadas onde diversas categorias de dados são analisadas, processadas e interpretadas em conjunto.
A IA está começando a atuar como base para treinamento em AR/VR por meio do princípio de simulação imersiva. Cenários de treinamento realistas proporcionam experiência prática em ambiente seguro — aplicação com crescimento acelerado em educação corporativa e treinamento técnico.
Plataformas e produtos de IA: Google, OpenAI e ecossistema open-source
O ecossistema de ferramentas de IA disponíveis para desenvolvimento de produtos inclui duas categorias principais: APIs de grandes provedores e modelos open-source customizáveis.
Do lado dos provedores comerciais: DALL-E para geração e edição de imagens; Whisper para transcrição universal e tradução de áudio; CLIP para análise semântica de imagens; Codex e Gym Library para desenvolvimento de software assistido por IA. Do ecossistema Google: Vertex AI para processamento de dados por cientistas, Dialogflow para criação de chatbots, Imagen para geração de imagens, Gemini para análise e geração multimodal avançada.
No ecossistema open-source: LLaMA (Meta) como base para fine-tuning customizado, Mistral para deployments leves em hardware limitado, e modelos da família Qwen e DeepSeek para casos de uso em domínios específicos. A vantagem do open-source não é custo zero — é controle total sobre o modelo, dados e infraestrutura de inference.
Modelos LLM em produção: estado atual e benchmarks reais
Os modelos GPT da OpenAI estabeleceram os benchmarks da indústria, mas o landscape mudou significativamente. A versão 3.5 operou com 175 bilhões de parâmetros e está sujeita a erros em raciocínio complexo. As versões posteriores expandiram capacidades de análise, geração de código e execução de tarefas em múltiplos passos.
Modelos open-source simplificados funcionam com limite de input relativamente baixo, mas apresentam resultados elevados em benchmarks especializados. O custo de treinamento de aplicações simples baseadas em GPT-4 com instrução ou LLaMA com Evol-Instruct começa em US$ 500–1.000. Para representar a capacidade de memória necessária: 10 a 15 bilhões de parâmetros cabem em uma GPU de 16–40 GB — essa é a regra prática para dimensionar infraestrutura de inference.
Sistemas generativos de IA também são desenvolvidos usando cloud computing baseada em serviços e datasets pré-configurados. O pipeline funciona bem na nuvem: processamento do dataset → coleta de informações → análise → modelo treinado → ajuste fino de parâmetros com adaptadores.
Aceleração do desenvolvimento de IA: o que esperar
A velocidade de evolução do ecossistema de IA mostra que chatbots fáceis de usar com aplicações para geração de conteúdo, reconhecimento de dados, geração de relatórios e documentação, busca de soluções e monitoramento de sistemas estão crescendo geometricamente em capacidade e adoção.
Aplicações de IA estão assumindo funções humanas simples e complexas. A tarefa central permanece a mesma: compor adequadamente um algoritmo de aprendizado, formar um dataset de qualidade, escrever prompts eficientes e realizar testes pós-treinamento rigorosos. Veja o guia técnico completo sobre como criar uma IA.
(1) Atrasos de acesso à produção: o desenvolvimento pode estar completo e os testes de staging passando, mas sem credenciais e acesso à infraestrutura de produção, o launch espera — isso pode adicionar 2 a 3 semanas a projetos tecnicamente finalizados;
(2) Sincronização de nós blockchain: nós Bitcoin full levam 5 a 10 dias para sincronizar em hardware dedicado — se não iniciado no dia 1 do projeto em paralelo ao desenvolvimento, vira o item de caminho crítico bloqueando o go-live;
(3) Falhas não determinísticas em testes: transações cripto dependem do estado da rede — casos de teste que passam de manhã podem falhar à tarde por mudança nas condições da mempool. Tratamos isso como normal e desenhamos suites de teste para distinguir falhas de infraestrutura de bugs da aplicação.
Quanto custa desenvolver um sistema de IA do zero?
O custo depende da abordagem. Fine-tuning de um modelo open-source existente para uma aplicação simples começa em US$ 500–1.000. Um agente autônomo com arquitetura de microserviços, integrações de terceiros e infraestrutura Kubernetes fica entre US$ 30.000 e US$ 150.000+. A variável mais relevante não é o modelo em si, mas a complexidade da infraestrutura de produção e das integrações.
Qual a diferença entre machine learning e deep learning no desenvolvimento de IA?
Machine learning é o campo amplo de algoritmos que aprendem com dados — inclui regressão linear, decision trees, SVM e redes neurais. Deep learning é um subconjunto de ML que usa redes neurais com múltiplas camadas (deep networks) para aprender representações hierárquicas de dados. Para tarefas com dados não estruturados — imagens, texto, áudio — deep learning é a abordagem dominante. Para dados tabulares estruturados, algoritmos clássicos de ML frequentemente superam redes neurais profundas em precisão e custo.
O que é fine-tuning de LLM e quando ele substitui o treinamento completo?
Fine-tuning é o processo de adaptar um modelo de linguagem pré-treinado para um domínio ou tarefa específica usando um dataset menor e especializado. Substitui o treinamento completo em 80% dos casos comerciais: o custo computacional é 5–10× menor, o tempo de desenvolvimento é medido em dias (não semanas), e a qualidade para tarefas especializadas é comparável. O treinamento do zero só faz sentido quando você precisa de controle total sobre os dados de pré-treinamento ou está construindo um modelo fundamentalmente novo.
Qual a diferença entre um agente de IA e um chatbot tradicional?
Um chatbot tradicional processa entradas e retorna respostas dentro de um fluxo de conversa. Um agente de IA tem a capacidade de executar ações no mundo real: chamar APIs, executar transações, manipular arquivos, tomar decisões sequenciais em múltiplos passos. A diferença arquitetural é o loop de raciocínio-ação: o agente planeja, executa, observa o resultado e ajusta a próxima ação. Isso exige design de sistema mais robusto — tratamento de erros, validação de segurança por camada e gestão de estado persistente.
Quanto tempo leva um projeto de desenvolvimento de IA?
Um chatbot simples com fine-tuning em modelo existente: 4 a 8 semanas. Uma plataforma com agente autônomo e integrações de API: 3 a 5 meses. Um sistema completo com microserviços, infraestrutura Kubernetes e compliance (KYC/AML): 4 a 8 meses. O fator que mais impacta o cronograma não é o desenvolvimento do modelo — é a infraestrutura de produção, especialmente sincronização de nós blockchain e ciclos de aprovação de compliance.







