
In 2026, the requirements for trading systems reached a new level: low latency, deterministic execution, scaling to 1M+ transactions per second (TPS), and full regulatory compliance. But these terms represent more than just code.
The foundation is a complex engineering ecosystem where every microsecond and every architectural decision matters. This is the matching engine.
What is an order-matching system? The "brain" of modern exchanges
The matching engine is the core of any crypto exchange, responsible for matching orders between buyers and sellers.It is here that liquidity is generated, the bid-ask spread is determined, and actual trade execution occurs.Beyond Definition: Why It's the Most Important Part of Your Infrastructure
In trading practice, the engine of comparison is the space where the following converge:- latency (micro- and nanoseconds determine the level of profit);
- deterministic execution (repeatability of results);
- Market Integrity (protection from manipulation);
- slippage control (the difference between the expected and actual price).
In high-frequency trading, a difference of even a few microseconds can mean a loss of profit. This is why the infrastructure surrounding the matching engine (network stack, memory management, cache locality) is often more important than the algorithm itself.
According to, up to 90% of all liquidity is generated by algorithmic orders, and the average order processing time on top US exchanges is less than 50 microseconds.
According to modern crypto exchanges, off-chain matching enables sub-millisecond latency and over 200,000 TPS — an approach we applied when building a DEX like dYdX. High-performance crypto exchanges are already demonstrating 100,000+ TPS and sub-10 millisecond latency.
Centralized vs. Decentralized Matching: Speed vs. Transparency
Today, most institutional traders in the US and Europe prefer centralized exchange engines due to low latency and execution control.
Below is a table of their comparison.
| Criterion | Centralized matching | Decentralized matching |
| Delay | < 100 µs | 100 ms - a few seconds |
| Throughput (TPS) | 100 thousand - 1 million+ TPS | 10-1000 TPS |
| Execution model | offline | online or hybrid |
| Transparency | Low | High |
| MEV (Maximum Extractable Value) | Controlled | High risk (relevant for DeFi platforms) |
| Regulatory compliance | Simple | Depends on consensus |
At the same time, the exchange trilemma remains relevant and requires the search for an effective compromise — which directly affects how much it costs to build a DEX.
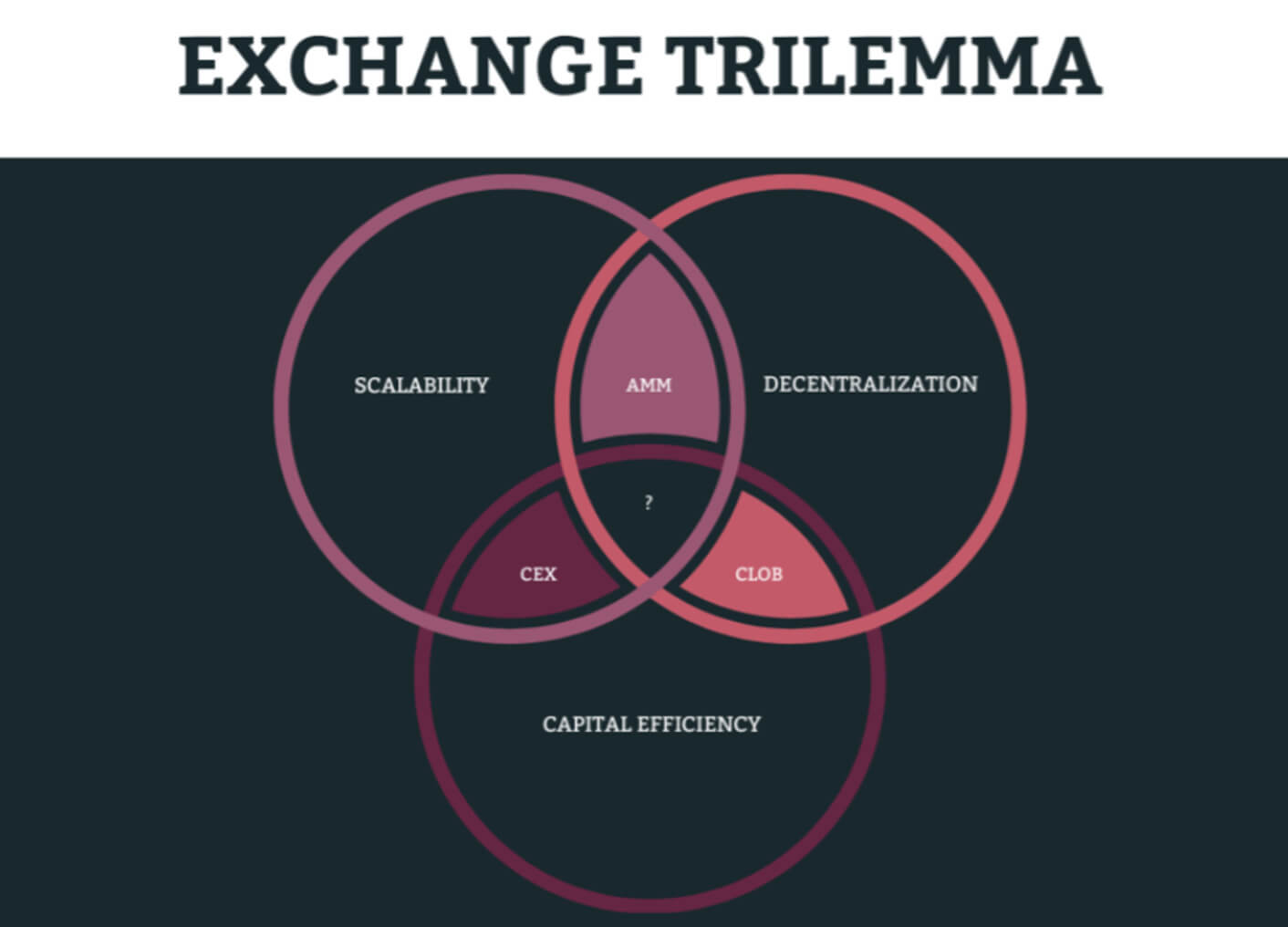
Unfortunately, it is impossible to simultaneously maximize speed, decentralization, and capital efficiency:
- If the focus is on high-frequency trading and low-latency arbitrage, then a centralized matching model is appropriate.
- If transparency and self-custody of funds are a priority, then the decentralized matching model wins.
The Anatomy of a Trade Deal: What Happens Behind the Scenes?
When a trader clicks the Buy or Sell button, the trade appears to be executed instantly. However, behind this action lies a complex sequence of components. They must operate in sync, ensure minimal latency, and guarantee deterministic execution.This mechanism is based on three elements: Order Gateway, Sequencer, Order Book.
It is their architecture that determines whether the system can scale to hundreds of thousands or even 1M+ TPS without losing stability — a topic we cover in depth in our guide on crypto exchange architecture.
Order processing gateway: checking and normalizing incoming traffic
The Order Gateway is the first entry point for all orders into the system.Here, raw traffic is converted into standardized and secure commands for the matching engine.
Main functions of the gateway:
- validation of order types (Limit Order, Market Order);
- checking user balance;
- control of price ranges (protection from "fat-finger" errors);
- Rate limiting and anti-DDoS mechanisms;
- normalization of data into internal format.
In high-performance systems, the order gateway operates through:
- TCP/UDP Multicast for delivering market data;
- FIX/FAST Protocol for institutional clients;
- binary encoding (SBE/Protobuf) to minimize latency.
Any delay or error at this stage is cascaded down the system. If the gateway isn't optimized, you lose liquidity before the order even hits the order book.
Sequencer: Ensuring deterministic execution of orders
The sequencer is often undervalued as an architectural component. But it is precisely this component that provides order amidst the chaos of thousands of parallel requests.Its key objectives are:
- assign Sequence IDs to each order;
- ensure strict order of execution;
- guarantee deterministic execution (Deterministic Execution).
Without a sequencer, chaotic behavior arises, auditing issues arise, and risks to market integrity increase. Consequently, effective regulatory verification is impossible.
Order Book: How Data Structures Affect Latency
The Order Book is the heart of the matching engine, where all active orders are stored: Bid (buy) and Ask (sell).It is in the book that the price difference (Bid-Ask Spread) is formed and matched.
The comparison of data structure is shown in the table below:
| Structure | Delay | Pros | Cons |
| Tree (RB-Tree) | Average | Flexibility | Cash misses |
| Pyramid (Heap) | Average | Simplicity | Not ideal for matching |
| Array + Price Levels | Low | Cache location | Less flexible |
| Lock-free queues | Very low | High speed | Difficulty of implementation |
Why cache locality is more important than Big-O:
- In theory, the tree may appear efficient (O(log n)), but in practice, cache misses lead to tens of nanoseconds of delay. Consequently, chasing numbers leads to unpredictable latency;
- The matching engine should use contiguous memory in the form of arrays to optimize for CPU cache and minimize allocations.
This approach allows you to avoid blocking I/O, maintain minimal latency, and scale without performance degradation.
Popular Matching Algorithms: Choosing the Right Logic for Your Market
The matching algorithm is more than just a technical architectural detail. It's an important mechanism that determines:- how liquidity is distributed — and which liquidity providers will find your platform attractive;
- What level of slippage do traders receive?
- How attractive is your market for market makers?
The same order book can behave completely differently depending on the chosen logic.
FIFO, Proportional Allocation, and Broker Price/Time Priorities
| Algorithm | Description | Advantages | Where is it used? |
| FIFO (Price-Time) | First in, first out: There are two limit orders. The one submitted first will be executed first. | simple and clear model; high market integrity; minimal possibilities for manipulation; |
Binance, Nasdaq |
| Proportion (Pro-Rata) | Proportional distribution: all orders at the same price receive a share of the execution (bigger order - bigger share) | stimulates the depth of liquidity; profitable for large market makers |
CME (derivatives) |
| Price-Broker-Time | Broker priority | gives preference to market makers; allows for the creation of stable liquidity |
Institutional markets and regulated trading platforms |
How to choose the right algorithm for your exchange: it all depends not on technology, but on your business model.
- If your goal is a spot exchange with retail traders and a simple UX, then
- The optimal solution would be FIFO.
- If you're building a derivatives platform or HFT ecosystem with deep liquidity, then Pro-Rata is a smart choice — see how we implemented this in our binary options and futures trading case study.
- If you are targeting institutional players, brokerage models and custom execution rules, then Price-Broker-Time is the way to go.
Developing Low-Latency Solutions: Technical Aspects from Merehead
In high-frequency trading systems, latency is more than just a metric. It's a factor that directly impacts profitability, liquidity, and competitiveness.Next, we explain our practical experience in building a matching engine that runs reliably in low-latency mode and scales to hundreds of thousands of TPS without degradation.
Trash trap
One of the most common mistakes is the use of Garbage Collection (GC) languages for the engine core.At first glance, everything looks simple and effective:
- Java/Node.js enables rapid development;
- large ecosystem;
- many ready-made solutions;
But in real-world practice, GC languages create unpredictable pauses, which are critical for high-frequency trading (HFT). Even short delays of 1-10 ms break deterministic execution and create latency spikes (P99, P999) — which is critical for algorithmic trading bots.
What are the benefits of using Rust:
- lack of GC;
- memory control without unplanned expenses;
- completely predictable performance;
- zero-cost abstractions.
Single-threaded event loops vs. multi-threaded event loops
The key problem is lock contention, context switching, and unpredictable latency.In our developments, we use a single-threaded event loop. It offers the following advantages:
- one thread per mapping engine;
- event-driven pipeline;
- non-blocking queues for data transfer.
The key feature of the single-threaded event loop is that it's similar to the LMAX Disruptor and Node.js event loop, but implemented at the system programming level (Rust/C++). It has the following features:
- no mutexes;
- without context switching;
- stable delay.
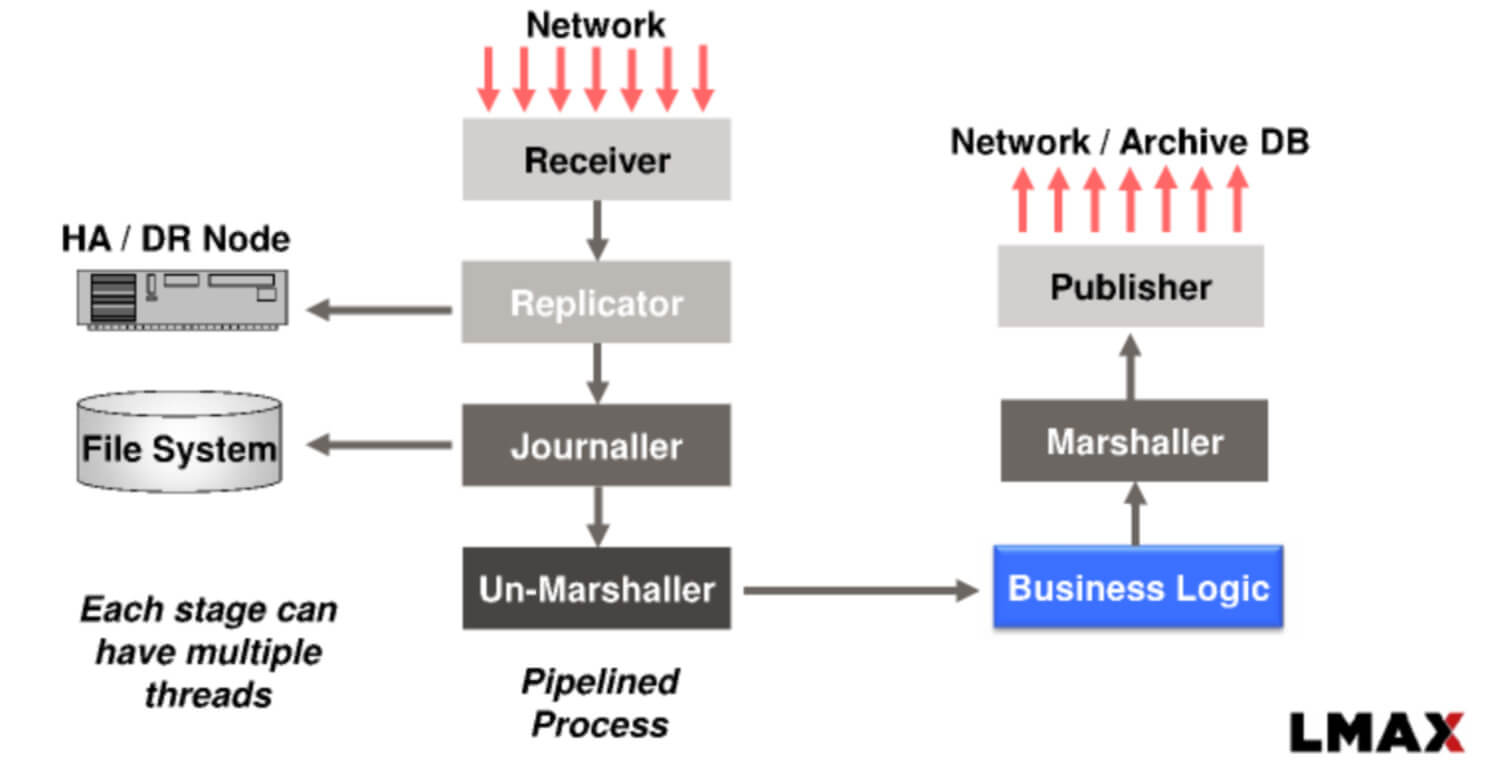
Thus, scaling is achieved not through threads, but through partitioning and horizontal scaling.
Binary protocols versus JSON
And right away we can provide a comparative table of key parameters:
| Protocol | Delay | Payload size | CPU latency | Use case |
| JSON/REST | High | Big | Public API | |
| REST | Low | Average | External clients | |
| ProtoBuf | Very low | Minimum | Internal services | |
| SBE | The corresponding engine |
In our project development practice, we use the SBE (Simple Binary Encoding) and ProtoBuf protocols.
Key benefits of SBE include:
- parsing without copying;
- minimal serialization;
- optimized for cache locality.
Binary protocols are useful and important because they allow:
- reduce latency by 10-30%;
- reduce CPU load;
- stabilize throughput.
Reliability and Disaster Recovery: Lessons from Practice
Below, we'll detail our practical experience building a system that can withstand disruptions without losing liquidity or user trust.The Snapshot Dilemma
We've implemented a system snapshot system. This involves taking snapshots every 50-100 ms and saving the order book state. This ensures efficient recovery after a failure in < 100 ms.The main problem of system recovery after a disaster is:
- a full log of operations leads to slow recovery;
- A bare snapshot system poses a risk of data loss.
To resolve the dilemma, it is important to achieve balance.
Our approach is a snapshot system + a log of all events. This means we combine snapshots, track the full state of the order book, and record all active limit orders and user positions. Incremental logs are also maintained, detailing what happens after snapshots, and recording data via memory-mapped files (mmap).
How it works in practice:
- Snapshot every 50-100 ms;
- logging of each event (order add/cancel/match)
If a failure occurs, the recovery sequence is as follows: first, the latest snapshot is loaded, then the log is played.
As a result, recovery time is < 100 ms, zero data loss is guaranteed and the order book is fully restored.
A comparison of the approaches can be seen in the table below:
| Approach | Recovery time | Risk of data loss | The impact of delay |
| Full replay | Seconds-minutes | Short | High |
| Snapshot only | Milliseconds | High | Low |
| Hybrid (which we use) | < 100 ms | Null | Minimum |
Determinism is king
In financial systems, simply recovering from a failure is not enough. It's important to ensure:- execution of orders in the same order as before the failure;
- identity and integrity of the spread (Bid-Ask Spread);
- the same results after the audit.
The following tools are used for implementation:
- Sequence IDs;
- Persistent logs;
- storage (mmap storage).
Thanks to sequence identifiers, each order receives a unique ID and position in the global queue. This forms the basis for deterministic execution.
Persistent logging allows all events to be recorded in strict order and through an append-only log. No concurrent writes.
A single-threaded event loop provides the following benefits:
- lack of race;
- fully assumed conveyor;
- 100% reproducibility after restart;
- compliance with regulatory compliance requirements;
- Possibility of full audit.
How to deal with input errors and unexpected crashes
In addition to technical failures, the system must withstand market anomalies such as:- trader mistakes (fat-finger);
- sharp market movements (flash crashes);
To ensure complete security, we implement special protection mechanisms:
- Price Bands – to limit the acceptable price range. If an order exceeds the volatility and last trade price limits, it is rejected.
- Circuit Breakers (automatic switches) – automatic trading pauses during sharp price movements. The system is evaluated in three conditions: a short pause, a longer pause, and a complete halt in trading.
- Pre-trade validation – at the payment gateway level, checks for abnormal volumes, controls slippage thresholds, and implements anti-manipulation filters.
Scaling to 1M+ TPS: Architecture that won't fail
The goal of executing millions of transactions per second isn't a quick-coding option. It's the foundation laid in the trading system's architecture.Many platforms face critical consequences that are not due to compliance logic, namely:
- conflicts between threads;
- CPU cache overload;
- inefficient use of memory.
So the key idea behind scaling is to have it be horizontal, taking into account the hardware.
Ticker-based split
We implement sharding of the matching engine across trading pairs. For example:- BTC/USDT – separate engine;
- ETH/USDT – separate engine;
- SOL/USDT is a separate engine.
This approach allows for horizontal scaling up to 1M+ TPS.
Our partitioning approach operates as a single-threaded event loop, meaning each trading pair engine has its own order book. This results in efficient results: no locking, perfect cache locality, and predictable, deterministic execution.
We observed the greatest performance gains not due to code optimization, but rather due to the transition to a split architecture.
NUMA Compatibility and CPU Affinity
Once the system is optimized at the architectural level, the next level is hardware optimization.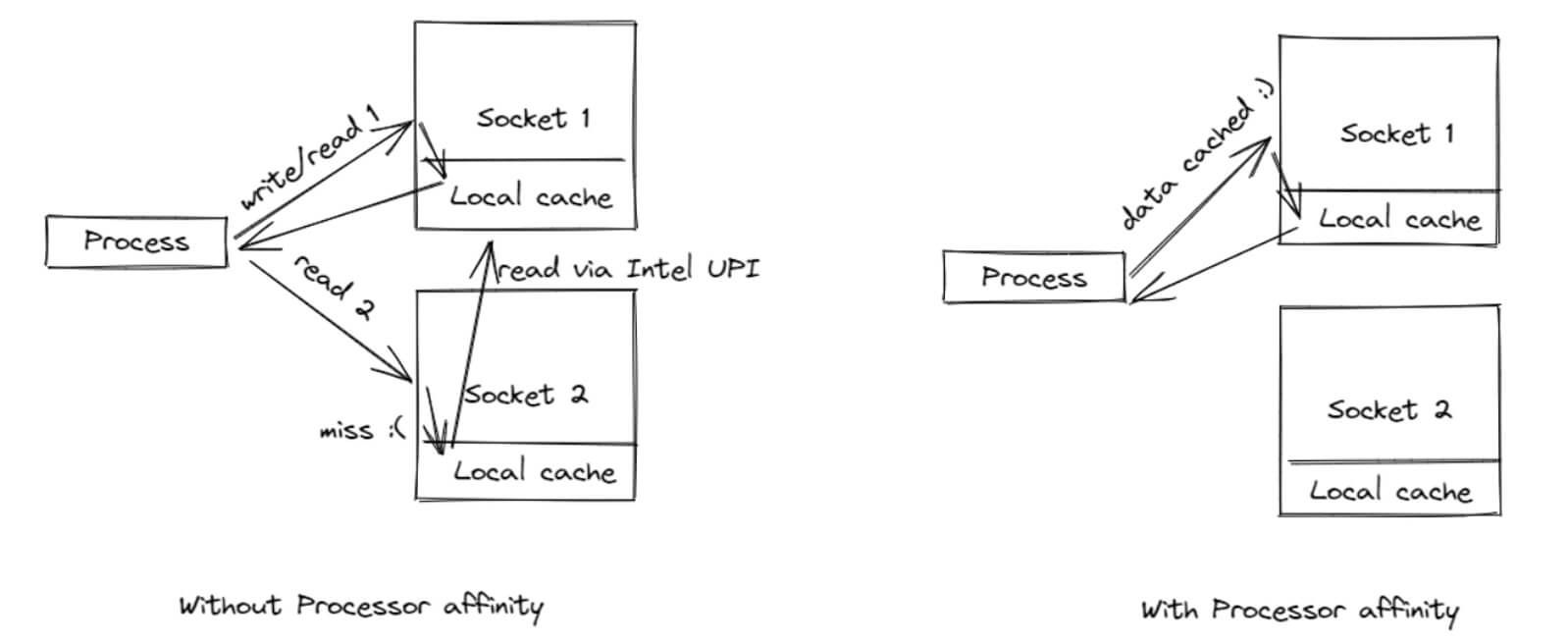
Trading systems are experiencing NUMA (non-uniform memory access) issues. This is caused by the following:
- memory is divided between CPU nodes;
- access to “foreign” memory is slow.
This results in latency spikes, cache misses, and inconsistent performance.
In our practice, we implement NUMA-aware design in the following way, that is, we use CPU Pinning (Thread Affinity):
- we assign the engine to a specific NUMA node;
- allocate memory locally;
- minimize cross-node access.
As a result, the matching engine is tied to a specific CPU core and does not migrate between other cores. This ensures minimal context switching, stable latency (especially on P99), and better cache locality.
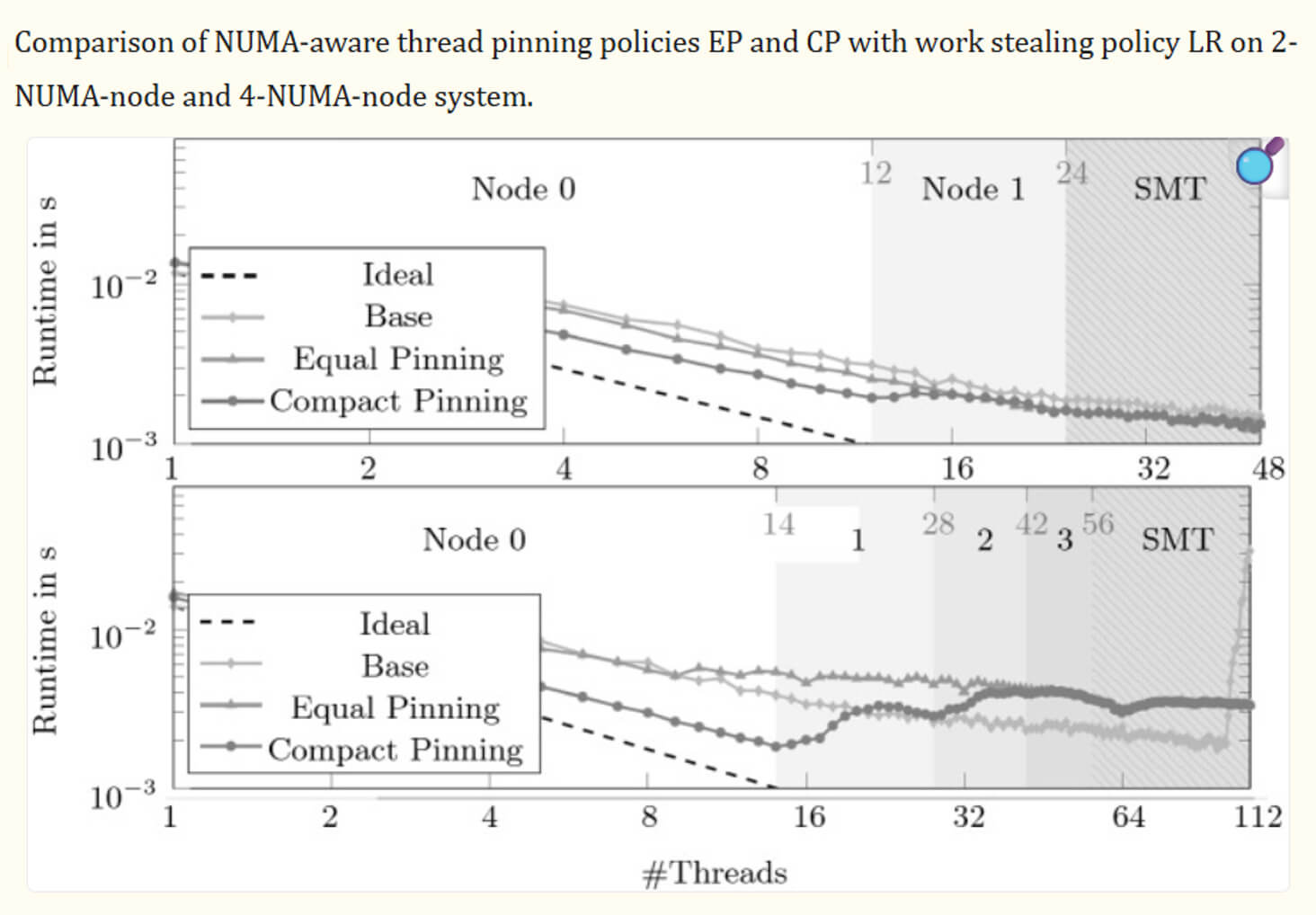
The table below shows the optimization efficiency:
| Parameter | Without optimization | NUMA + CPU affinity |
| Delay (P99) | Unstable | Stable |
| Cache misses | Tall | Low |
| Bandwidth | Average | High |
| Context switching | Frequent | Minimum |
In real practice, NUMA optimization provides , and CPU affinity reduces latency spikes by up to 40%.
Security and Compliance: More Than Just Code
A matching engine isn't just about speed and low latency in the trading system. It prioritizes trust and security. A security system and matching policy should be built into the engine's core from the very beginning.Preventing Wash Trades: How Our Algorithms Detect Self - Matching
Wash trading (self-matching) is the most common form of manipulation. It manifests itself as follows:- the trader places both Bid and Ask orders simultaneously;
- creates fake liquidity;
- manipulates volumes and prices.
This is critical to the system, as it undermines market integrity and creates a false bid-ask spread. Furthermore, manipulative conditions increase the risk of regulatory sanctions — especially on P2P crypto exchanges where self-matching is harder to detect. In the US (SEC/FINRA) and the EU (MiFID II), this is directly classified as market manipulation.
Our effective approach is detection at the matching engine level. We don't rely solely on post-trade analytics. Monitoring occurs before and during order execution. We use the following key mechanisms:
- Self-Match Prevention (SMP): The buyer-seller logic is checked and if the evaluation is positive, the order is confirmed, cancelled or partially executed with a correction.
- Account & Entity Linking: Accounts are linked using KYC, IP/device fingerprinting, and behavioral patterns. The algorithm detects "hidden" self-trading across multiple accounts.
- Pattern Detection: The algorithm analyzes repeating orders, symmetrical volumes, and unnatural trading frequencies.
The table below provides a brief comparison of all approaches:
| Approach | When does it work? | Efficiency | The impact of delay |
| Post-trade analysis | After the deal | Average | Null |
| Engine-level SMP | Before and during the transaction | High | Minimum |
| Behavioral Machine Learning (Behavioral ML) | Constantly | High | Average |
Audit logs and FIX protocol
In the modern trading infrastructure, "transparency" is not an abstract concept but a technical requirement. It determines the ability to operate in regulated jurisdictions (the US, EU, and UK). This means the matching engine must not only be fast but also fully replayable. To achieve this, we analyze insertion logs, timestamps for each event, and the full trading history (from order creation to its cancellation or adjustment).Audit log is a log for adding events that records the entire life cycle of an order (from creation to cancellation).
A typical audit flow chart looks like this:

FIX/FAST Protocol is a financial messaging standard used by virtually all institutional players (Nasdaq, NYSE, CME, major brokers and banks).
This protocol has the following advantages:
- Standardization in a unified format: New order (single) – Execution report – Request to cancel the order.
- Full traceability – each message contains the ClOrdID (customer order identifier), ExecID (execution identifier), timestamps, and order status. This allows for the complete order lifecycle to be tracked and disputes to be resolved quickly.
- Regulatory compliance – the FIX protocol is the de facto standard for SEC Rule 613 (CAT reporting) and MiFID II transaction reporting. Without FIX, integration with the institutional world is virtually impossible.
Today, a crypto exchange cannot maintain its market position without a strong security foundation. Compliance policies must be integrated into the platform itself, with guarantees of complete transparency through audits and FIX protocols essential. Such a system builds trust not only among traders but also among regulators. For a deeper look at security practices, see our Ultimate Guide to Crypto Exchange Security 2026.
Manufacturing Checklist: What Your Competitors Won't Tell You
Most teams focus on latency, throughput, and architecture. However, the greatest risk and danger are Black Swan events:- sudden load jumps;
- network breaks;
- partial component failures;
- inconsistent states between services.
Therefore, today it is not enough to simply test a system. It is necessary to demonstrate that it will survive chaos — as we showed in our crypto exchange case study.
Stress Testing: Modeling Black Swan Events
What is Chaos Engineering in the context of the Compliance Engine? It's a specific approach where we deliberately break the system to test:
- will deterministic execution be preserved;
- will the order book be damaged;
- Will the system be able to withstand peak loads?
Testing involves covering the following scenarios:
- Network partition: gap between the payment gateway and the matching engine, TCP/UDP Multicast latency. We check for duplicate orders and that the order (Sequence IDs) is maintained.
- Partial failure: one engine (e.g., BTC/USDT) crashes while others continue to operate. Scripted waiting isolates the problem and prevents cascading failures.
- Latency spikes: artificial delays in memory access, networking, and logging. The key goal is to test P99 latency stability and identify hidden vulnerabilities.
- Order flooding: This means thousands of market orders are open simultaneously, and sudden changes in liquidity are recorded. We check whether the system can withstand the burst load and whether slippage increases.
As real-world experience shows, most critical bugs appear not under load, but during partial failures, state switches, and post-error recovery. This is why chaos testing is a mandatory step before system launch.


