
В 2026-ом году требования к торговым системам вышли на новый уровень: низкая задержка (Low-Latency), детерминированное выполнение (Deterministic Execution), масштабирование до 1-го миллиона транзакций в секунду (1M+ TPS) и полное соответствие регуляторным требованиям (Regulatory Compliance). Но за этими терминами стоит не только код.
Фундаментом выступает сложная инженерная экосистема, где важна каждая микросекунда и каждое архитектурное решение. Это двигатель сопоставления (matching engine).
Что такое система сопоставления заявок? «Мозг» современных бирж
Двигатель сопоставления (Matching engine) — это ядро любой криптобиржи, отвечающее за сопоставление заявок (orders) между покупателями и продавцами. Именно здесь формируется ликвидность (Liquidity), определяется спред цены покупки и продажи (Bid-Ask Spread), а также происходит реальное исполнение сделок.За пределами определения: почему это самая важная часть вашей инфраструктуры
В торговой практике двигатель сопоставления является пространством, где сходятся:- задержка (микро- и наносекунды определяют уровень прибыли);
- детерминированное выполнение (повторяемость результатов);
- целостность рынка Market Integrity (защита от манипуляций);
- контроль проскальзывания (разница между ожидаемой и реальной ценой).
В сегменте высокочастотной торговли (high-frequency trading) разница даже в несколько микросекунд может означать потерю прибыли. Именно поэтому инфраструктура вокруг двигателя сопоставления (сетевой стек, управление памятью, локальность кэша) часто важнее самого алгоритма.
По данным Nasdaq TotalView ITCH (2025), до 90% всей ликвидности формируется алгоритмическими ордерами, а среднее время обработки заявки в топовых биржах США — менее 50 мкс.
По данным современных криптобирж, механизм сопоставления вне сети (off-chain matching) позволяет достигать задержки в миллисекунды и более 200K TPS. Высокопроизводительные криптобиржи уже демонстрируют показатель в 100K+ TPS и менее 10 миллисекунд задержки.
Централизованное и децентрализованное сопоставление: скорость против прозрачности
Сегодня большинство институциональных трейдеров в США и Европе отдают предпочтение движкам централизованных бирж, что обусловлено низкой задержкой (Low-Latency) и контролем исполнения.Ниже представлена таблица их сравнения.
| Критерий | Централизованное сопоставление | Децентрализованное сопоставление |
| Задержка | < 100 мкс | 100 мс - несколько секунд |
| Пропускная способность (TPS) | 100 тыс - 1 млн+ TPS | 10-1000 TPS |
| Модель исполнения | вне сети | в сети или гибридная |
| Прозрачность | Низкая | Высокая |
| MEV (Максимальная извлекаемая ценность) | Контролированная | Высокий риск (актуально для DeFi платформ) |
| Соблюдение нормативных требований | Простое | Зависит от консенсуса |
При этом трилемма обмена остается актуальной и требует поиска эффективного компромисса — что напрямую влияет на стоимость создания DEX.
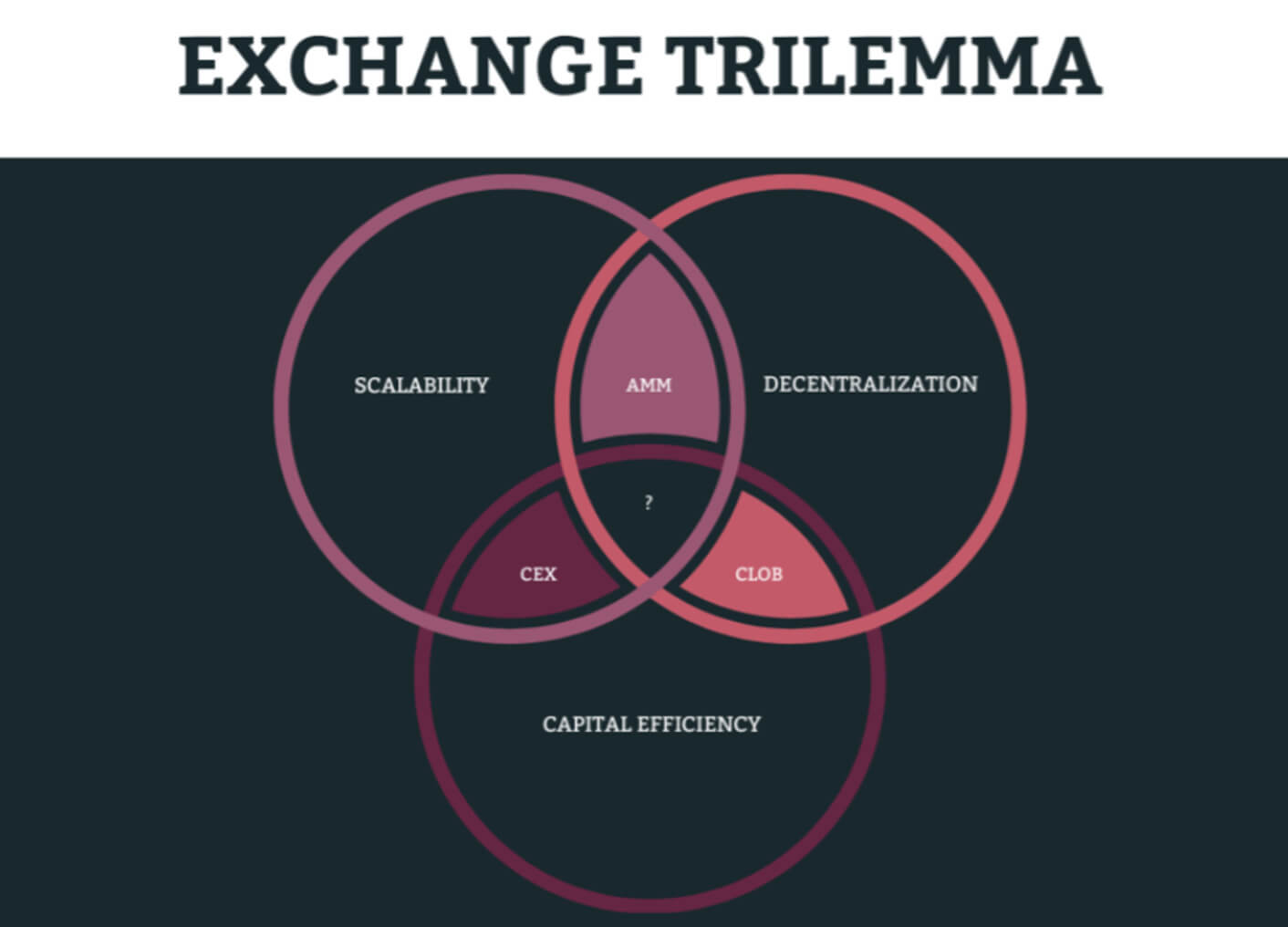
Увы, невозможно одновременно максимизировать скорость, децентрализацию и капитальную эффективность:
- Если акцент падает на высокочастотную торговлю и арбитраж с минимальной задержкой, тогда имеет место централизованная модель сопоставления.
- Если в приоритете прозрачность и самостоятельное хранение средств, тогда выигрывает модель децентрализованного сопоставления.
Анатомия торговой сделки: что происходит «за кулисами»?
Когда трейдер нажимает кнопку Buy (купить) или Sell (продать), кажется, что торговая сделка выполняется мгновенно. Но за этим действием стоит сложная последовательность компонентов. Они должны работать синхронно, обеспечивать минимальную задержку и гарантировать детерминированное исполнение.Этот механизм базируется на трех элементах: шлюз ордеров (Order Gateway), секвенсор (Sequencer), книга ордеров (Order Book).
Именно их архитектура определяет, сможет ли система масштабироваться до сотен тысяч или даже 1M+ TPS без потери стабильности — тема, которую мы подробно рассматриваем в нашем руководстве по архитектуре криптобирж.
Шлюз обработки заказов: проверка и нормализация входящего трафика
Шлюз ордеров (Order Gateway) — это первая точка входа для всех заявок в систему.Здесь «сырой» трафик превращается в стандартизированные и безопасные команды для двигателя сопоставления.
Основные функции шлюза:
- валидация типов ордеров (Limit Order, Market Order);
- проверка баланса пользователя;
- контроль ценовых диапазонов (защита от «fat-finger» ошибок);
- ограничение скорости (Rate limiting) и анти-DDoS механизмы;
- нормализация данных во внутренний формат.
В высокопроизводительных системах шлюз ордеров работает через:
- TCP/UDP Multicast для доставки маркет-данных;
- FIX/FAST Protocol для институциональных клиентов;
- двоичное кодирование (SBE/Protobuf) для минимизации задержки.
Любая задержка или ошибка на этом этапе масштабируется дальше по системе. Если шлюз не оптимизирован, вы теряете ликвидность еще до того, как ордер попадет в книгу ордеров.
Секвенсор: обеспечение детерминированного выполнения порядков
Секвенсор (Sequencer) как компонент архитектуры часто недооценивается. Но именно он обеспечивает порядок в хаосе тысяч параллельных заявок.Его ключевые задачи:
- присваивать идентификаторы последовательностей (Sequence IDs) каждому ордеру;
- обеспечивать строгий порядок выполнения;
- гарантировать детерминированное исполнение (Deterministic Execution).
Без секвенсора возникает хаотичное поведение, появляются проблемы с аудитом, а также повышаются риски для рыночной целостности. Как следствие, невозможно достичь эффективной проверки на нормативном уровне.
Книга ордеров: как структуры данных влияют на задержку
Книга ордеров (Order Book) — это сердце двигателя соответствия, где хранятся все активные заявки: Bid (покупка) и Ask (продажа).Именно в книге формируется ценовая разница (Bid-Ask Spread) и проходит соответствие.
Сравнение структуры данных приведено в таблице ниже:
| Структура | Задержка | Плюсы | Минусы |
| Дерево (Tree / RB-Tree) | Средняя | Гибкость | Кэш промахивается |
| Пирамида (Heap) | Средняя | Простота | Неидеально для сопоставления |
| Массив + уровни цен (Array + Price Levels) | Низкая | Местоположение кэша | Менее гибкая |
| Очереди без блокировки (Lock-free queues) | Очень низкая | Высокая скорость | Сложность реализации |
Почему локализация кэша важнее Big-O:
- в теории дерево может выглядеть эффективно (O(log n)), но на практике кэш теряется и это ведет к задержке на десятки наносекунд. Как следствие, погоня за цифрами ведет к непредсказуемой задержке;
- в двигателе соответствия должна использоваться непрерывная память в виде массивов для оптимизации под CPU cache и минимизации распределений.
Такой подход позволяет избежать блокировки (blocking I/O), сохранить минимальную задержку и масштабироваться без деградации производительности.
Популярные алгоритмы сопоставления: выбор правильной логики для вашего рынка
Алгоритм сопоставления — это не просто техническая деталь архитектуры. Это важный механизм, который определяет:- как распределяется ликвидность (Liquidity) — и какие провайдеры ликвидности найдут вашу платформу привлекательной;
- какой уровень проскальзывания (Slippage) получают трейдеры;
- насколько привлекателен ваш рынок для маркет-мейкеров.
Одна и та же ордерная книга может вести себя совершенно по-разному в зависимости от выбранной логики.
Приоритеты FIFO, пропорционального распределения и соотношения цены и времени брокера
| Алгоритм | Описание | Преимущества | Где используется |
| FIFO (Цена-Время) | Первый пришел — первый исполнен: есть два лимитных ордера. Первым будет исполняться тот, который подан раньше второго. | простая и понятная модель; высокая рыночная целостность; минимальные возможности для манипуляций; |
Binance, Nasdaq |
| Пропорция (Pro-Rata) | Пропорциональное распределение: все заявки на одной цене получают долю исполнения: больший ордер — большая доля. | стимулирует глубину ликвидности; выгоден для крупных маркет-мейкеров |
CME (деривативы) |
| Прайс-Брокер-Время (Price-Broker-Time) | Приоритет брокера | дает предпочтение маркет-мейкерам; позволяет строить стабильную ликвидность |
Институциональные рынки и регулируемые торговые площадки |
Как выбрать правильный алгоритм для работы биржи: здесь все зависит не от технологий, а от вашей бизнес-модели.
- Если ваша цель — спотовая биржа с розничными трейдерами и простым UX, то оптимальным решением будет FIFO.
- Если вы строите деривативную платформу или HFT-экосистему с глубокой ликвидностью, выгодно выбирать Pro-Rata — смотрите, как мы реализовали это в нашем кейсе по бинарным опционам и фьючерсной торговле.
- Если вы ориентируетесь на институциональных игроков, брокерские модели и кастомные правила исполнения, тогда имеет место Price-Broker-Time.
Разработка решений с низкой задержкой: технические аспекты от Merehead
В высокочастотных торговых системах задержка (latency) — это не просто метрика. Это фактор прямого влияния на прибыль, ликвидность и конкурентоспособность.Далее мы объясняем наш практический опыт построения двигателя сопоставления, который стабильно работает в режиме низкой задержки (Low-Latency) и масштабируется до сотен тысяч TPS без деградации.
Ловушка для сбора мусора
Одна из самых распространенных ошибок — это использование языков Garbage Collection (GC) для ядра движка.На первый взгляд все выглядит просто и эффективно:
- Java/Node.js обеспечивает быструю разработку;
- большая экосистема;
- много готовых решений;
Но в реальной практике языки GC создают непредсказуемые паузы, которые критичны для высокочастотного трейдинга (HFT). Даже короткие задержки в 1-10 мс ломают детерминированное исполнение и создают всплески задержек (P99, P999) — что критично для алгоритмических торговых ботов.
В чем преимущества использования Rust:
- отсутствие GC;
- контроль памяти без незапланированных расходов;
- полностью предсказуемое исполнение;
- абстракции с нулевой стоимостью.
Однопоточные циклы событий против многопоточных циклов событий
Ключевая проблема заключается в конфликте блокировок, переключении контекста и непредсказуемой задержке.В наших разработках мы используем однопоточный цикл событий (Single-threaded Event Loop). Он характеризуется такими преимуществами:
- один поток на один двигатель сопоставления;
- конвейер, управляемый событиями;
- очереди без блокировок для передачи данных.
Ключевая особенность однопоточного цикла событий в том, что он похож на LMAX Disruptor и Node.js event loop, но реализован на уровне системного программирования (Rust/C++). При этом имеет такие особенности:
- без мьютексов;
- без переключения контекста;
- стабильная задержка.
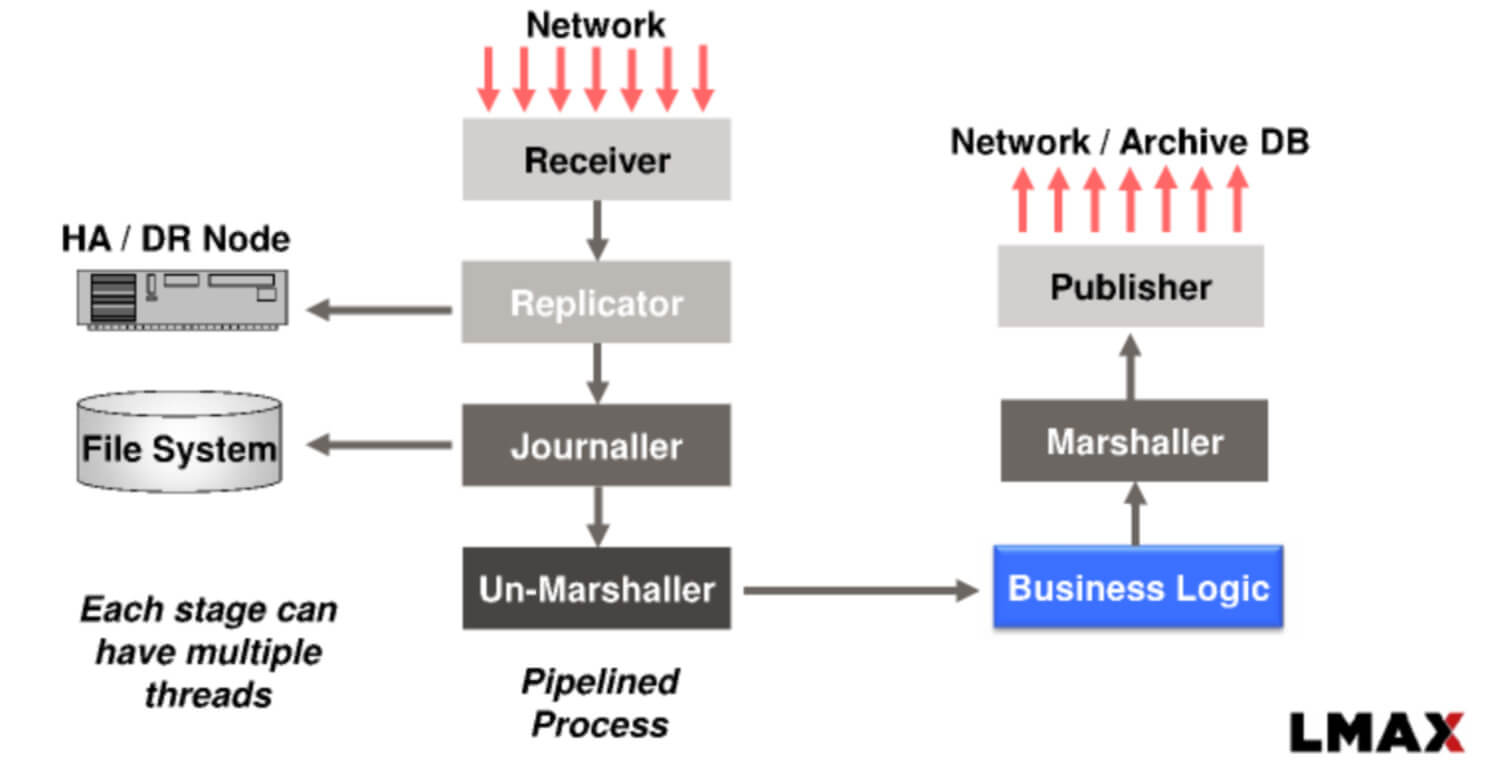
Таким образом, масштабирование достигается не через потоки, а через разделение и горизонтальное масштабирование.
Бинарные протоколы против JSON
И сразу можно привести сравнительную таблицу ключевых параметров:| Протокол | Задержка | Размер полезной нагрузки | Задержка процессора | Вариант использования |
| JSON/REST | Высокая | Большой | Публичный API | |
| REST | Низкая | Средний | Внешние клиенты | |
| ProtoBuf | Очень низкая | Минимальный | Внутренние услуги | |
| SBE | Соответствующий двигатель |
В нашей практике разработки проектов мы используем протоколы SBE (Simple Binary Encoding) и ProtoBuf.
Среди ключевых преимуществ SBE:
- синтаксический анализ без копирования;
- минимальная сериализация;
- оптимизирован под локальность кэша.
Бинарные протоколы полезны и важны тем, что позволяют:
- снизить задержку на 10-30%;
- снизить нагрузку на CPU;
- стабилизировать пропускную способность.
Надежность и аварийное восстановление: уроки из практики
Далее мы подробно разберем наш практический опыт построения системы, которая выдерживает сбои без потери ликвидности и доверия пользователей.Дилемма моментальных снимков
Мы реализовали систему снимков состояния системы (Snapshots). Она подразумевает фиксацию каждые 50-100 мс и сохранение состояния книги ордеров. Таким образом, достигается эффективное восстановление после сбоя < 100 мс.Основная проблема восстановления системы после катастрофы заключается в:
- полный лог операций ведет к медленному восстановлению;
- «голая» система снимков формирует риск потери данных.
Для решения дилеммы важно достичь баланса.
Наш подход таков: система снимков Snapshot + журнал всех событий. То есть мы комбинируем снимки состояния, отслеживаем полное состояние книги ордеров, фиксируем все активные лимитные ордера и позиции пользователей. Одновременно с этим ведется журнал событий (Incremental logs): что происходит после снимков состояния, а также идет запись через Memory-mapped files (mmap).
Как это работает на практике:
- Snapshot каждые 50-100 мс;
- логирование каждого события (order add/cancel/match).
Если происходит сбой, то последовательность восстановления такая: сначала загружается последний snapshot, затем проигрывается лог.
В результате время восстановления < 100 мс, гарантируется нулевая потеря данных и происходит полное восстановление книги ордеров.
Сравнение подходов можно увидеть в таблице ниже:
| Подход | Время восстановления | Риск потери данных | Влияние задержки |
| Полный повтор | Секунды-минуты | Низкий | Высокое |
| Только снимок состояния | Миллисекунды | Высокий | Низкое |
| Гибридный (который мы используем) | < 100 мс | Нулевой | Минимальное |
Детерминизм — король
В финансовых системах недостаточно просто восстановить сбой. Здесь важно гарантировать:- исполнение ордеров в том же порядке, что и до сбоя;
- идентичность и сохранность спреда (Bid-Ask Spread);
- одинаковые результаты после аудита.
Для реализации задействуются следующие инструменты:
- идентификаторы последовательностей (Sequence IDs);
- постоянные журналы (Persistent logs);
- хранилище (mmap storage).
Благодаря идентификаторам последовательностей каждый ордер получает уникальный ID и позицию в глобальной очереди. Это формирует базу детерминированного исполнения.
Постоянные журналы позволяют записывать все события в строгом порядке и через лог «только для добавления». Никаких параллельных записей.
Однопоточный цикл событий дает такие преимущества:
- отсутствие гонки;
- полностью предполагаемый конвейер;
- 100% воспроизводимость после рестарта;
- соответствие требованиям регуляторного соответствия;
- возможность полного аудита.
Как справляться с ошибками ввода и внезапными сбоями
Кроме технических сбоев система должна выдерживать рыночные аномалии, такие как:- ошибки трейдеров (fat-finger);
- резкие движения рынка (flash crashes);
- манипуляции.
Для полного обеспечения безопасности мы внедряем специальные механизмы защиты:
- Price Bands (ценовые коридоры) — для ограничения допустимого диапазона цен. Если ордер выходит за пределы показателей волатильности и последней цены сделки, он отклоняется.
- Circuit Breakers (автоматические выключатели) — автоматическая приостановка торгов при резких движениях цены. Система оценивается в трех состояниях: в условиях короткой паузы, более длинной паузы и с полной остановкой торгов.
- Pre-trade validation (предварительная проверка сделки) — на уровне платежного шлюза осуществляется проверка аномальных объемов, контроль пороговых показателей проскальзывания и антиманипуляционные фильтры.
Масштабирование до 1M+ TPS: архитектура, которая не даст сбоев
Задача достичь исполнения миллионных транзакций в секунду — это не опция быстрого кодирования. Это фундамент, который закладывается в архитектуру торговой системы.Многие платформы сталкиваются с критическими последствиями, обусловленными не логикой соответствия, а именно:
- конфликтами между потоками;
- перегрузом кэша CPU;
- неэффективным использованием памяти.
Поэтому ключевая идея масштабирования в том, чтобы оно было горизонтальным с учетом аппаратного обеспечения.
Разделение на основе тикеров
Мы осуществляем шардинг двигателя сопоставления по торговым парам. Например:- BTC/USDT — отдельный движок;
- ETH/USDT — отдельный движок;
- SOL/USDT — отдельный движок.
Такой подход позволяет горизонтально масштабироваться до 1M+ TPS.
Наш подход в разделении работает как однопоточный цикл событий, таким образом, каждый движок торговой пары имеет собственную ордерную книгу. И мы получаем эффективный результат: отсутствуют блокировки и достигается идеальная локализация кэша (Cache Locality) с прогнозируемым детерминированным исполнением.
Наибольший рост производительности мы наблюдали не за счет оптимизации кода, а именно благодаря переходу на разделенную архитектуру.
NUMA-совместимость и привязка CPU
Когда система уже оптимизирована на уровне архитектуры, следующий уровень — это оптимизация аппаратного обеспечения.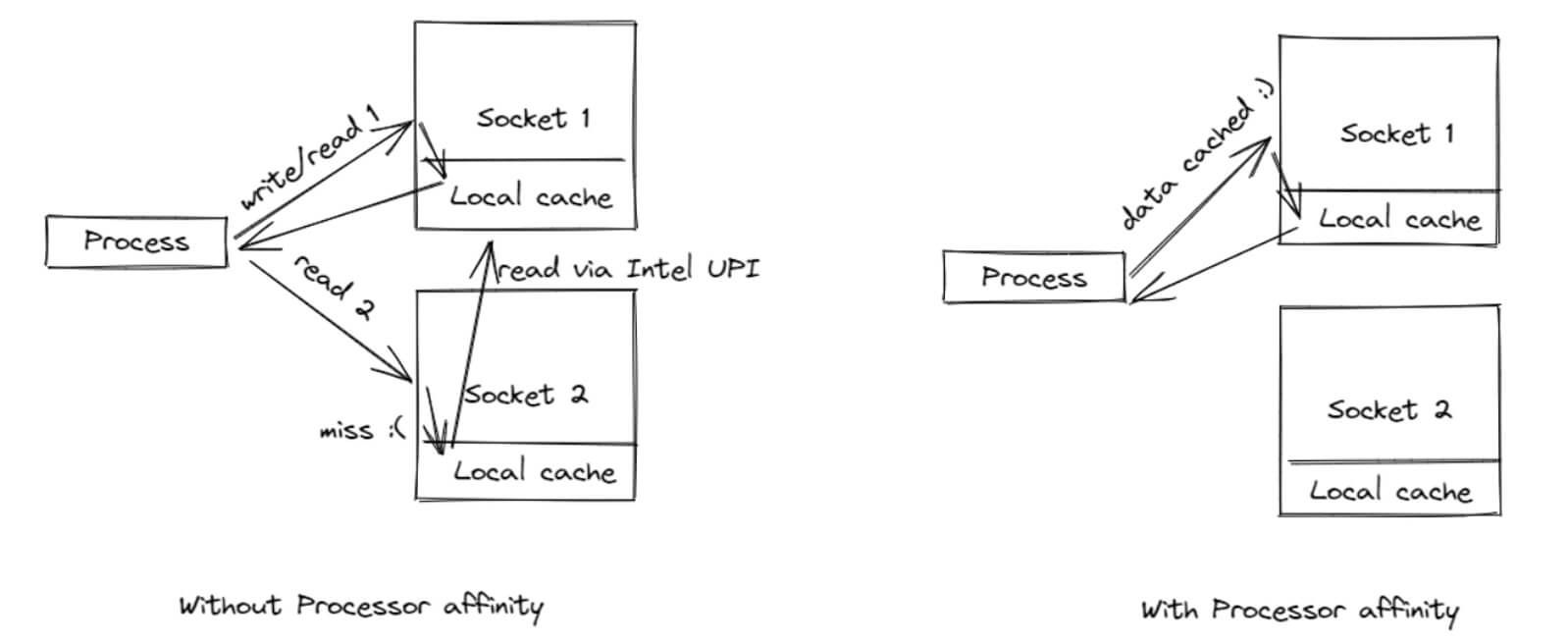
Торговые системы сталкиваются с проблемой NUMA (неравномерный доступ к памяти). Это обусловлено следующими событиями:
- память разделена между CPU узлами;
- доступ к «чужой» памяти происходит медленно.
Как следствие, возникают скачки задержки и промахи кэша, а также нестабильная производительность.
В нашей практике мы реализуем проектирование с учетом NUMA следующим образом, то есть используем привязку CPU (CPU Pinning / Thread Affinity):
- закрепляем движок за конкретным NUMA узлом;
- выделяем память локально;
- минимизируем перекрестный узловой доступ (cross-node access).
В результате двигатель соответствия привязан к конкретному CPU ядру и не мигрирует между другими ядрами. Это дает минимальное переключение контекста (context switching), стабильную задержку (особенно P99) и лучшую локализацию кэша.
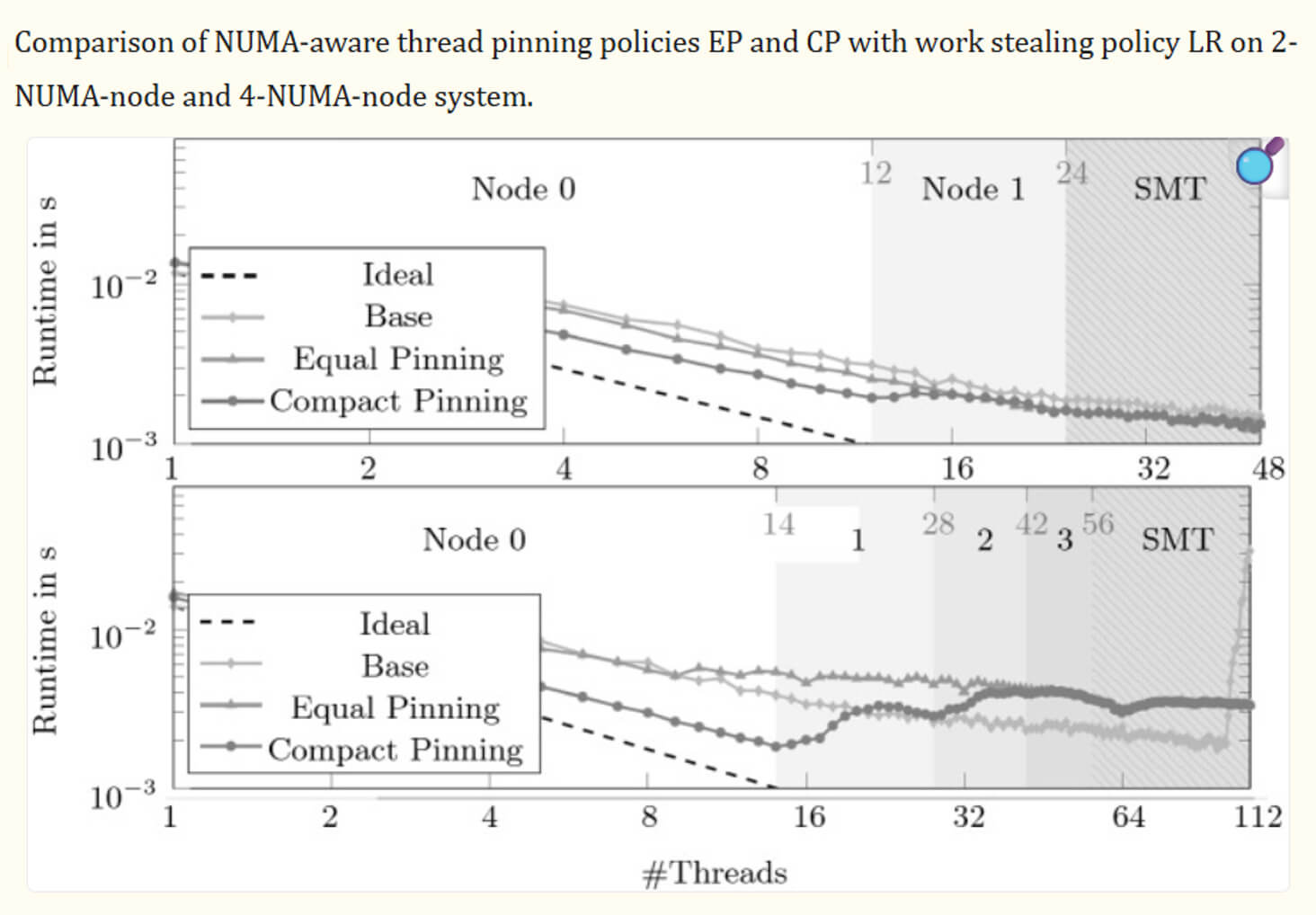
В таблице ниже можно проанализировать эффективность оптимизации:
| Параметр | Без оптимизации | NUMA + привязка CPU |
| Задержка (P99) | Нестабильный | Стабильный |
| Промахи кэша | Высокие | Низкие |
| Пропускная способность | Средняя | Высокая |
| Переключение контекста | Частое | Минимальное |
В реальной практике NUMA оптимизация дает +20-30% производительности, а привязка CPU снижает скачки задержки до 40%.
Безопасность и соответствие нормативным требованиям: больше, чем просто код
Двигатель сопоставления — это не только акцент на скорости и низких задержках в торговой системе. Это приоритет доверия и безопасности. Система безопасности и политика соответствия должны быть встроены в ядро движка на старте разработки.Предотвращение фиктивных сделок: как наши алгоритмы определяют самоторговлю (self-matching)
Wash trading (self-matching) является самой распространенной формой манипуляции. Она проявляется следующим образом:- трейдер одновременно выставляет ордера Bid и Ask;
- создает фейковую ликвидность;
- манипулирует объемами и ценой.
Это критично для системы, так как нарушает рыночную целостность и создает ложный спред (Bid-Ask Spread). Кроме того, в манипулятивных условиях повышаются риски санкций от регуляторов — особенно на P2P криптобиржах, где самоторговлю сложнее обнаружить. В США (SEC/FINRA) и Евросоюзе (MiFID II) это прямо классифицируется как рыночная манипуляция.
Наш эффективный подход — это обнаружение на уровне механизма сопоставления. Мы не полагаемся только на post-trade аналитику. Контроль происходит до и во время выполнения ордера.
Мы задействуем такие ключевые механизмы:
- Предотвращение самоподбора (Self-Match Prevention / SMP): проверка логики «покупатель-продавец» и при положительной оценке ордер подтверждается, упраздняется или частично выполняется с коррекцией.
- Связывание учетных записей и организаций (Account & Entity Linking): происходит связывание аккаунтов через KYC, IP/отпечаток устройства, поведенческие модели. Алгоритм обнаруживает «скрытую» самоторговлю через различные аккаунты.
- Распознавание образов (Pattern Detection): алгоритм анализирует повторяющиеся ордера, симметричные объемы и неестественную частоту сделок.
Ниже в таблице приведено краткое сравнение всех подходов:
| Подход | Когда работает | Эффективность | Влияние задержки |
| Постторговый анализ (Post-trade analysis) | После сделки | Средняя | Нулевой |
| SMP на уровне двигателя (Engine-level SMP) | До и во время сделки | Высокая | Минимальный |
| Поведенческое машинное обучение (Behavioral ML) | Постоянно | Высокая | Средний |
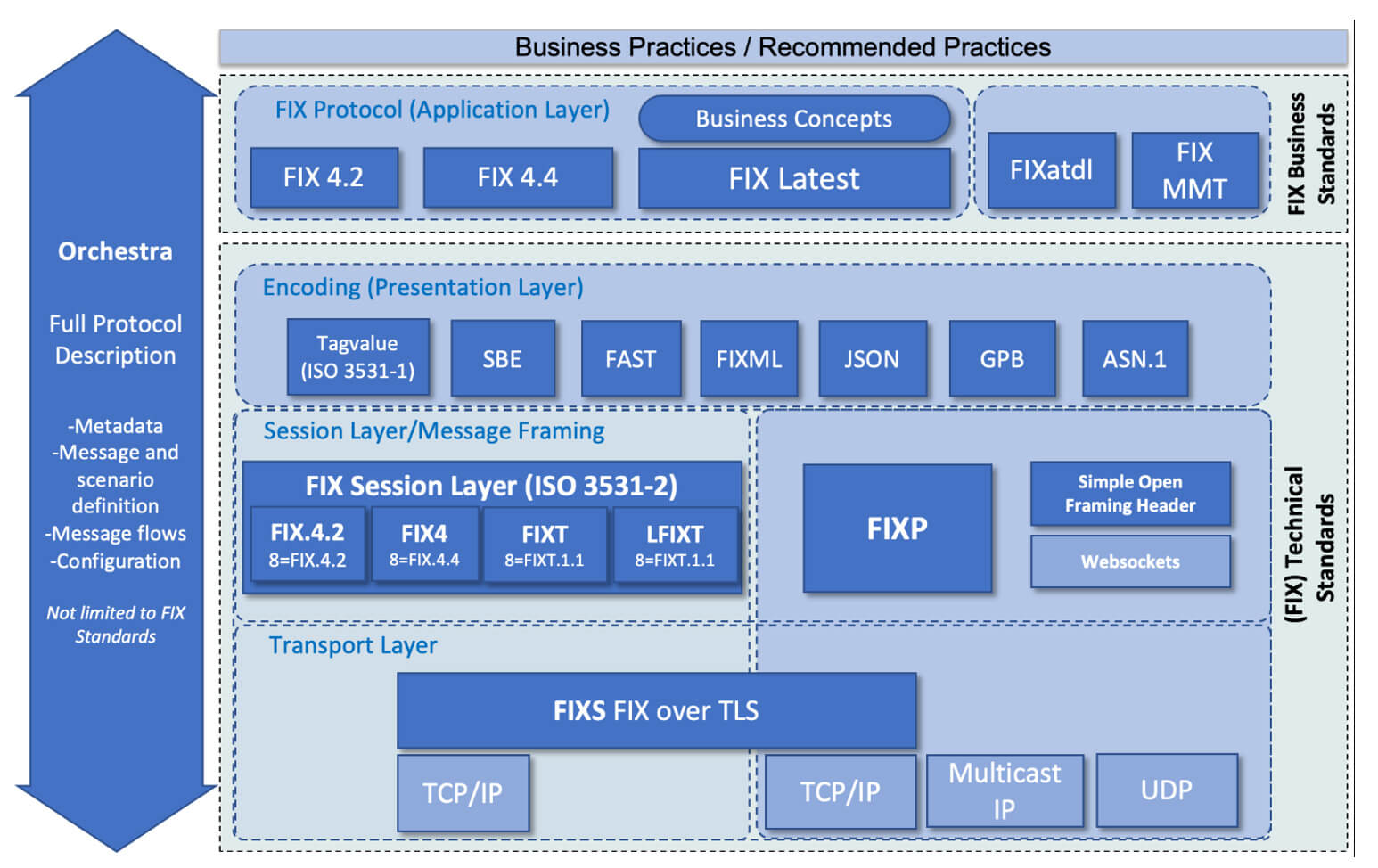
Журналы аудита и протокол FIX
В современной торговой инфраструктуре «прозрачность» — это не абстрактное понятие, а техническое требование. Именно оно определяет возможность работать в регулируемых юрисдикциях (США, ЕС, Великобритания).Это означает, что двигатель сопоставления должен быть не только быстрым, но и полностью воспроизводимым (replayable). Для этого мы анализируем журналы добавления, временные метки каждого события, полную торговую историю (от создания ордера до его отмены или коррекции).
Audit log — это журнал для добавления событий, который фиксирует весь жизненный цикл ордера (от создания до отмены).
Типичная схема аудита выглядит следующим образом:

FIX/FAST Protocol — это стандарт обмена финансовыми сообщениями, который используется практически всеми институциональными игроками (Nasdaq, NYSE, CME, крупные брокеры и банки).
Данный протокол обладает такими преимуществами:
- Стандартизация в унифицированном формате: Новый ордер (единичный) — Отчет об исполнении — Запрос на отмену ордера.
- Полная трассированность (Traceability) — каждое сообщение содержит ClOrdID (идентификатор заказа клиента), ExecID (идентификатор исполнения), временные метки, статус ордера. Таким образом, отслеживается полный жизненный цикл ордера и быстро решаются споры.
- Соответствие регуляторным требованиям — протокол FIX является стандартом де-факто для SEC Rule 613 (CAT reporting) и MiFID II transaction reporting. Без FIX интеграция с институциональным миром практически невозможна.
На сегодняшний день криптобиржа не сможет удержать свои позиции на рынке без сильного фундамента системы безопасности. Политика соответствия должна быть интегрирована в сам движок, при этом важны гарантии полной прозрачности через аудиты и FIX протоколы. Такая система формирует доверие не только трейдеров, но и регуляторов.
Контрольный список для производства: о чем вам не расскажут конкуренты
Большинство команд фокусируются на задержке, пропускной способности и архитектуре. Однако наибольший риск и опасность представляют события «Черный лебедь»:- внезапные прыжки нагрузки;
- разрывы сети;
- частичные отказы компонентов;
- неконсистентные состояния между сервисами.
Поэтому сегодня недостаточно просто протестировать систему. Необходимо доказать наочно, что она выживет в хаосе — как мы продемонстрировали в нашем кейсе по созданию криптобиржи.
Проверка в условиях стресса: моделирование событий типа «Черный лебедь»
Что такое Chaos Engineering в контексте двигателя соответствия? Это специальный подход, где мы сознательно ломаем систему, чтобы проверить:
- сохранится ли детерминированное исполнение;
- не нарушится ли ордерная книга;
- выдержит ли система пиковые нагрузки.
Тестирование подразумевает охват следующих сценариев:
- Раздел сети: разрыв между платежным шлюзом и движком соответствия, задержки в TCP/UDP Multicast. Проверяем, не возникает ли дублирование ордеров и сохраняется ли порядок (Sequence IDs).
- Частичный отказ: падение одного engine (например BTC/USDT), а другие при этом продолжают работать. Ожидание по сценарию — это изоляция проблемы и отсутствие каскадного сбоя.
- Скачки задержки: искусственные задержки в доступе памяти, сетевом уровне и логировании. Ключевая цель — это проверить стабильность P99 задержки и найти «скрытые» уязвимые места.
- Флудинг ордеров: то есть открыты тысячи рыночных ордеров одновременно и фиксируются резкие изменения ликвидности. Мы проверяем, выдерживает ли система разрывную нагрузку и не увеличивается ли проскальзывание.
Как показывает реальная практика, большинство критических багов появляются не под нагрузкой, а в момент частичного сбоя, переключения состояний, восстановления после ошибки. Именно поэтому тестирование хаоса — это обязательный этап перед запуском системы.


