
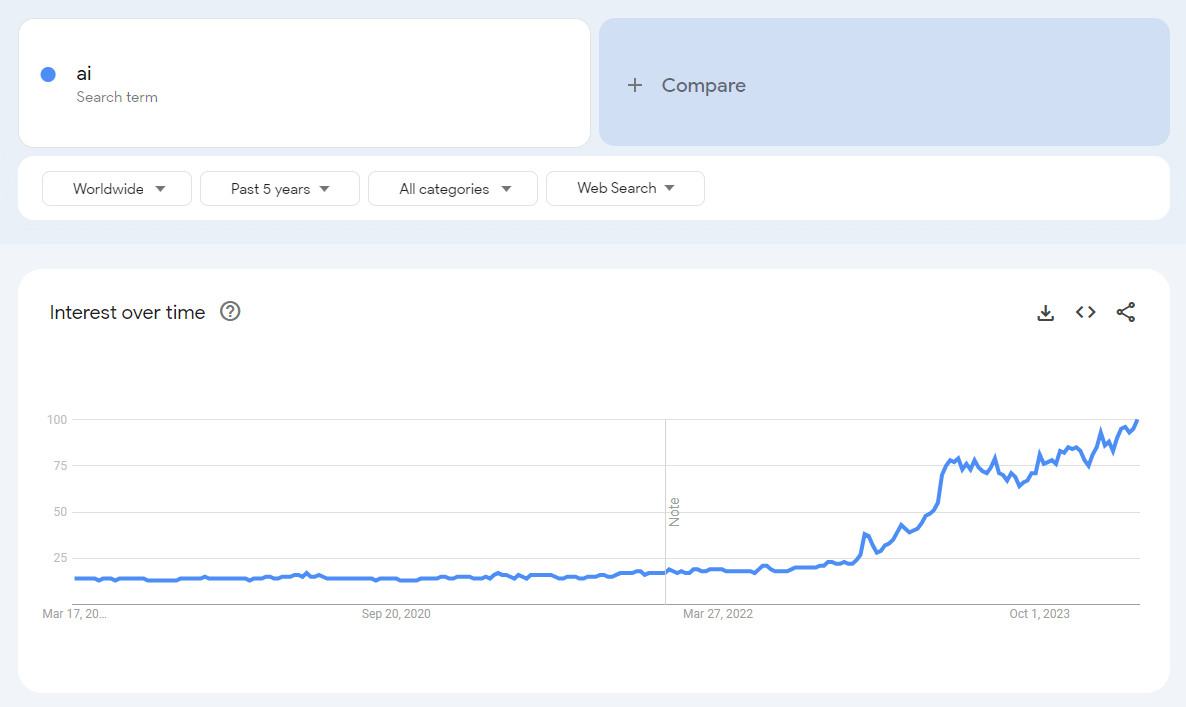
A era da inteligência artificial ganhou vida há muito tempo. As pessoas se acostumaram com a identificação e registro instantâneos, busca mais rápida de transporte e rotas, seleção conveniente de produtos e uso de serviços de IA. A IA tornou-se um assistente confiável para os negócios, substituiu funcionários e reduziu a zero a probabilidade de erros devido ao fator humano. O trabalho rotineiro foi relegado à categoria de trabalho terceirizado para a IA, enquanto as tarefas criativas são realizadas por especialistas líderes.
Aplicações e redes neurais, algoritmos de ação de IA
Modelos e algoritmos baseados em IA, aplicativos e chatbots estão sendo desenvolvidos por cada uma das empresas de TI usando aprendizado de máquina e aprendizado profundo para analisar dados digitais. Para projetos desafiadores, as redes neurais nos negócios estão sendo conectadas. A visualização com IA é reconhecimento e visão computacional 3D.Os aplicativos bancários prospectivos geralmente se baseiam no trabalho de um assistente inteligente de IA. Operações realizadas pela IA segundo critérios refinados de troca, compra, venda - dia a dia. A pré-seleção de quadros de acordo com indicadores específicos, o diagnóstico inicial dos pacientes, a configuração de ações de segurança quando um gatilho específico é acionado também são resultados do pensamento de IA. A geração de textos, imagens e conteúdo de vídeo de nível médio tem sido alvo de boatos há vários anos.
A análise de imagens de quadricóptero FPV é uma maneira conveniente de avaliar o terreno em tempo real. Ele pode ser configurado para ser enviado diretamente a um data center para tomada de decisão acelerada assistida por IA em situações básicas. Automatizar processos é um dos outros benefícios da implementação de IA.
Reconhecimento e verificação, diagnóstico e prognóstico com IA
Exemplos de como a IA pode ser utilizada nas operações comerciais das agências de viagens incluem o reconhecimento de passaportes, seguros e documentos de viajantes. É fácil inserir esses dados em formulários de inscrição ou contratos com taxas de erro mínimas, de 1 a 5%. O reconhecimento da rede neural é treinado por meio da análise de fotos e textos no espaço, com adaptação e verificação, formando uma resposta da API. O próprio software, criado com tecnologias RPA, pode ser integrado em qualquer CRM ou chatbot, gabinete de usuário.O robô RPA está concluindo a documentação de rotina, gerando relatórios e realizando operações para configurar o horário de trabalho. O treinamento é realizado com a ajuda do aprendizado de máquina de ML. A criação e treinamento de redes neurais, sejam convolucionais ou generativas em arquitetura, é uma das técnicas de ML frequentemente utilizadas. As redes neurais têm a capacidade de prever negociação de criptomoeda e preços de criptomoedas, diagnosticar doenças ou comprometimento funcional. Os cientistas estão usando-os para fazer previsões sobre as características de qualidade de medicamentos baseados em componentes, avaliar a condição de um objeto ou liga planejada.
Modelagem de decisão com ciência de dados
Construir bancos de dados e mostrá-los à IA não é suficiente: é preciso ensiná-la a reconhecer situações em que é necessário dar uma resposta clara e rápida. Estas são situações em que os bancos de dados relacionais não conseguem encontrar a solução certa. Tais questões são tratadas por analistas de Data Science. Eles são responsáveis por determinar os algoritmos e as condições do modelo matemático sob o qual ele é implementado:- modelagem de processos;
- segmentação e personalização de clientes, solicitações chave;
- relevância das ofertas.
Para visualizar o processo, digamos que uma pessoa esteja dirigindo um carro. Ele recebeu um telefonema, que provocou uma onda de endorfinas. Como resultado, seus batimentos cardíacos aumentaram, mas sua atenção diminuiu e houve um desejo de “dirigir rápido”. O rastreador em seu braço detecta isso e transmite a informação para o sistema de IA do carro. A IA faz um alerta - recomenda reduzir a velocidade (ou faz ela mesma), reduz o calor na cabine e abre a janela.
Um desafio para a IA
IA simplesmente não é pensamento humano. Os computadores estão realizando o que o programador exige deles – calcular, calcular, executar ações específicas. Você pode definir a tarefa por voz ou texto, mas antes introduz regras e restrições, dependências, inclusive estatísticas. Os algoritmos de transformação são esquemas padrão por padrão: "Descrição" - "Regras" ou "Tarefa" - "Soluções". A previsão funciona se forem introduzidas várias situações com exemplos.Considere a seguinte tarefa: "Escreva um programa em Python para gerar lucros no mercado. Capital inicial 100 mil dólares, lucro esperado 10% do investimento, número de mercadorias no mercado 10.000, preço médio de um produto 50 dólares, comissão de 3%".
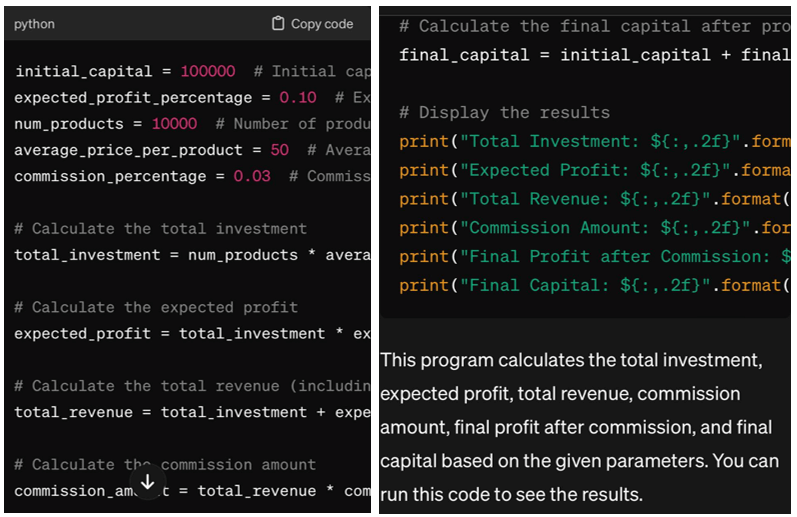
O resultado será uma resposta acima mencionada, que é restrita devido à introdução de um pequeno número de indicadores nas condições problemáticas. Quanto mais detalhados forem os fatores e maior o tamanho do conjunto de dados, menor será o erro na solução final. Ao treinar a IA, o programador insere as informações iniciais e marca cada fragmento. Quando o banco de dados com marcadores de controle é acumulado, o treinamento passa para a fase de busca de regras e verificação na predição.
Cenários e erros de modelagem de etapas
Cada etapa consiste em encontrar um padrão prescrito e procurar um novo com um determinado parâmetro. Por exemplo, se chegou um carro Mercedes, depois Audi e Honda, o próximo pode ser BMW ou Mitsubishi. Caso não haja necessidade de busca de padrões, desabilitamos esta função e utilizamos as soluções dos passos anteriores.Um cenário onde o primeiro marcador é seguido por uma pergunta e o próximo marcador é seguido por uma resposta torna o algoritmo conveniente, pois responderá a quaisquer perguntas dentro dos limites da base de informações. É claro que existe um erro em todo algoritmo de previsão.
É aceitável se as margens de erro estiverem dentro de 5%. O modelo estocástico é adequado quando não há certeza na faixa de entrada ou saída de dados. Uma função local com mapeamento de valor único é guiada por identificadores de objeto. As funções simples são monoparâmetros, os cálculos nelas são realizados por meio de coeficientes, mas não por afirmações, é falso ou verdadeiro.
Algoritmos, resultados e funções de análise
Cada algoritmo é dividido em etapas: condições e transições, cada uma terminando com um operador de resultado, mas não com um retorno. A comparação com uma constante, que é um determinado ponto ou etapa do algoritmo, é a base para a previsão contínua. Pode ser comparado à pesquisa de correlação, quando os dados dos recursos correlacionados são acumulados e combinados em grupos. Em seguida, com base no resultado da base obtida, são selecionadas a condição geral e a distância entre o parâmetro fornecido e o resultado do cálculo.Se parece com isso:
- formando funções com um parâmetro;
- seleção de peças com as mesmas condições;
- criação de uma nova função de dois parâmetros;
- refinamento da linearidade em bases multiparâmetros.
A conversão envolve algoritmos para encontrar soluções e depois criar regras com base nas respostas. Às vezes o resultado é uma recursão com vários níveis ou um fractal. Os tokens de controle respondem às consultas e produzem cálculos finais, levando em consideração velocidade, aceleração e erro do processo. No entanto, os algoritmos são baseados em estatísticas.
Autossuficiência e autonomia: equilibrando análises e decisões
Não é característico de um computador procurar uma solução ou realizar pesquisas sem uma tarefa. Mesmo que programado condicionalmente como uma personalidade humana, sem uma tarefa o PC não executará ações específicas. A lógica formal não funciona aqui, precisamos de matemática e estatística. As decisões tomadas pela IA de forma autônoma devem ser analisadas: se ultrapassam os limites dos algoritmos e scripts, mas representam uma opção preferível, então esta é a confirmação do acerto da decisão sobre “autonomia”.Princípios de IA:
- a análise preditiva com descoberta de padrões e tendências é aplicada à previsão baseada em padrões e probabilidades de eventos;
- multimodalidade implica processamento simultâneo de informações de diversas fontes e tipos de dados;
- o método multidisciplinar assemelha-se ao método científico, pois vai à intersecção de diversas ciências e seus ramos com o objetivo de melhorar o desempenho da IA.
O nível máximo de análise está no ASI, que se assemelha ao pensamento humano. A inteligência da AGI está próxima do nível médio do pensamento humano. ANI é um executor típico que não vai além das tarefas escritas do programa.
Treinamento com números, reconhecimento e com informações incompletas
Acumular uma grande quantidade de dados requer treinamento em IA. Regressão linear e multivariada, vetores de suporte, árvore de decisão com subcategorias e vizinhos KNN são utilizados para formato de máquina. O aprendizado por reforço inclui algoritmos para robôs. A comunicação do chatbot é o resultado do uso de Transformers após o processamento da linguagem humana.A tarefa da PNL é o reconhecimento de texto e áudio, tradução e geração de conteúdo. Há 6 anos, programadores da rede social Facebook desenvolveram um bot baseado em dados da Amazon (6 mil diálogos reais) que não era diferente de um humano, podia barganhar e até trapacear. Isto mostra que as tarefas da IA em esquemas de marketing e entretenimento são diversas:
- no varejo, eles pensam em algoritmos para elaborar promoções e ofertas de compra;
- no ramo de restaurantes, eles criam interiores e cardápios originais;
- na indústria de jogos, após um treinamento aprofundado, eles desenvolvem uma mente ideal que consiste em um gerente de IA e programas de agentes de "arquitetura híbrida".
Olhando para a aplicação Libratus como exemplo, fica claro que a IA consiste em várias partes. A parte central analítica interage com a segunda parte, que monitora os erros dos adversários e a terceira parte, que analisa os erros nas próprias ações. Este é um exemplo em que informações incompletas são usadas para fornecer uma resposta completa e abrangente nos setores de segurança cibernética, militar e de negociação.
Modelos com soluções corretas e operação ChatGPT-3.5
Há 12 anos, os economistas Shepley e Roth receberam o Prémio Nobel pela teoria da distribuição estável. As soluções dos matemáticos foram confirmadas em TI: as técnicas de distribuição unimodal e bimodal funcionam se uma base de dados multibilionária for recrutada e depois analisada na forma de histogramas. Desenvolvedores nos laboratórios OpenAI e Google, a Microsoft monitora constantemente o treinamento da IA, eliminando soluções incorretas e criando templates baseados nas corretas. Existem 60 mil empresas de TI registradas no mundo para desenvolvimento de software baseado em IA.
A versão 3 do ChatGPT usou apenas 175 bilhões de fontes. A versão 5, a ser lançada até o final de 2024, gerará simultaneamente conteúdo textual e audiovisual. O número de fontes para desenvolvimento é 100 vezes a quantidade de dados que o ChatGPT-3 possui. A versão avançada e poderosa analisará dados, servirá de base para chatbots, gerará código e executará outras funções de assistente virtual. Até agora, o modelo 3.5 funciona assim e está sujeito a erros.
Produtos de IA do Google e da Microsoft
Os aplicativos comprovados de IA incluem o DALL-E, que gera e edita imagens e faz colagens. Whisper - um transcritor universal de IA que pode reconhecer fala e traduzir. CLIP - um analogizador de imagens e fotos. Gym Library and Codex – plataformas baseadas em IA para programadores. A lista do Google contém 15 aplicativos e plataformas de IA semelhantes. É verdade que muitas vezes existem bugs e erros em seu trabalho.Algoritmos de IA são usados no Google Fotos e no Youtube, um tradutor para melhorar recursos e analisar dados. O chatbot do Google Bard é análogo ao ChatGPT, mas com sua própria linguagem PaLM 2. Pode ser utilizado simultaneamente com o Gemini, que possui alto nível de geração e análise. Imagen AI gera imagens, Generative AI é um testador de modelos de aprendizagem generativos. A Vertex AI ajuda os cientistas a processar dados, o Dialogflow serve para criar chatbots.
As plataformas de IA da Microsoft incluem a enciclopédia universal Copilot, o serviço de desenvolvedor do Azure Space que gera imagens, imagens e logotipos, esboços do Image Creator.
Grã-Bretanha e Foxconn de Taiwan vão alavancar IA
No cadastro HMLR do Reino Unido, onde são registados os títulos de terras e propriedades, metade do trabalho é feito pela IA. O monitoramento de desempenho de software, Android e aplicativos Android é feito pelo APM, então a Atlassian usa ferramentas de plataforma baseadas em IA para monitorar processos e garantir que não haja erros. É por isso que a IA é frequentemente utilizada para manutenção preventiva de sistemas vitais, avaliando as condições técnicas para evitar paralisações e acidentes.A previsão de negócios de um projeto ou operação comercial específica melhora a precisão e economiza orçamento. Por exemplo, a Foxconn, fabricante taiwanesa de componentes para smartphones e produtos Apple, economizou mais de meio milhão de dólares em uma fábrica mexicana graças ao desenvolvimento de IA baseada no Amazon Forecast.
Aprendizagem profunda e escolas para IA
Programadores e desenvolvedores estão treinando neurônios artificiais (nós) para resolver problemas usando métodos de aprendizagem profunda. Isso inclui um algoritmo de PNL para processamento de linguagem, significado e tom, e IA generativa cujo conteúdo e artefatos de áudio, vídeo e texto são semelhantes aos humanos. Os dados brutos – recursos com subcamadas – representam a infraestrutura operacional na qual ocorre o aprendizado. Eles podem ser armazenados em recursos físicos ou na nuvem.Uma espécie de "escolas" para IA - plataformas como TensorFlow ou PyTorch. Uma biblioteca de código aberto Scikit-learn escrita em Python está disponível. Para o treinamento, são formadas funções e feitas aulas de acordo com o plano de arquitetura da aplicação de IA. No nível de modelagem, o poder é determinado, depois a segmentação por níveis e a funcionalidade de ativação.
Os desenvolvedores analisam como os neurônios alteram os pesos de seus vizinhos durante a comunicação e estimam os nós de deslocamento. A previsão e os dados reais não devem ser muito diferentes entre si - para isso, utiliza-se a comparação por meio de uma função de perda. Nesse processo, otimizadores como gradiente descendente ou sequências de gradiente adaptativas, levando em consideração mínimos e máximos e rapidez de mudança, ajudam. A IA no formato de aplicativo atende ao cliente e não ao funcionário.
Geração de conjunto de dados, utilização de GPU e modelo base
A versatilidade do modelo GPT é condicionada pela correção das abordagens de aprendizagem promtom, customização para questões específicas, trabalho com conjunto de dados e poder computacional. Em uma empresa envolvida no treinamento de modelos de IA, existem cem ou duas GPUs e mais. Eles são responsáveis por computar e processar informações gráficas, treinando modelos por até 10 a 30 dias, dependendo da complexidade. Quanto mais parâmetros houver no conjunto de dados, maior será o preço.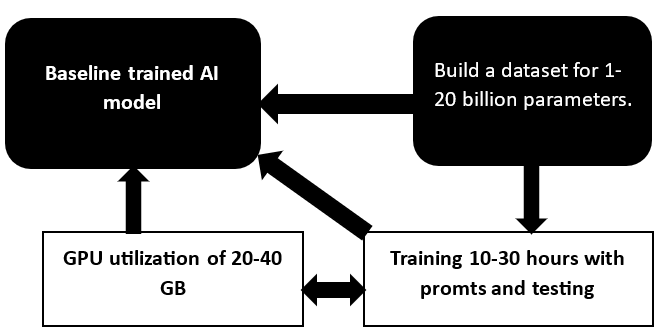
Modelos simplificados de código aberto funcionam. Embora o limite de entrada seja baixo, eles apresentam resultados elevados em benchmarks. O preço do treinamento de aplicativos simples com base no complexo GPT-4 com Google Bard ou LLaMA com Evol-Instruct começa em US$ 500-1000. Cada base nessas versões é fácil de finalizar e obter um aplicativo de autoria customizado, melhor que um pago.
Os clientes devem estar cientes de que a capacidade de memória para desenvolver aplicativos simplificados de IA é relativamente pequena e são necessárias GPUs com 40-80 GB de memória. Os sistemas generativos de IA também são desenvolvidos usando tecnologias de nuvem baseadas nos serviços e conjuntos de dados certos. O Pipeline funciona bem na nuvem, começando pelo processamento do conjunto de dados, coletando informações e analisando os dados. Freqüentemente, o modelo correto já está estabelecido, portanto, é necessário treinar e ajustar alguns parâmetros com adaptadores. Para representar a quantidade de informações, lembre-se da regra prática: 10 a 15 bilhões de parâmetros cabem em uma GPU de 16 a 24 ou 40 GB.
Modelo LLM com método PEFT, cenário simplificado
Se estiver usando um modelo LLM treinado como base, o método PEFT expandirá o subconjunto desejado de parâmetros, mas deixará aqueles que não são necessários em um estado "congelado". Os analistas da empresa descobrem no briefing quais parâmetros o cliente tem interesse e treinam com base nos selecionados. Acontece que é uma formação parcial, cujo resultado não é pior do que um curso de formação completo. É por isso que no processo de consulta ao cliente, os especialistas em TI especificam imediatamente se precisam gerar um conjunto de soluções com instruções e condições ou criar de forma independente programas de treinamento com pares de perguntas e respostas.O cenário de treinamento em nuvem padrão envolve recursos escalonáveis em nuvem, gerenciamento de provedores de nuvem e aproveitamento de serviços prontos para uso como ferramentas de treinamento. Protocolo de desenvolvimento de ML com cenários de geração e processamento de dados de origem, experimentos de versionamento, implantação e incorporação de modelo, acompanhamento com atualizações funciona sem customização manual. Aqui está um exemplo de solução completa para a plataforma - uma combinação de JupyterHub para experimentação, MLflow para implantação e interação de ciência de dados e tarefas, ambiente MLflow Deploy para empacotamento e implantação.
Este modelo treinado em GPT responde às perguntas para as quais as informações são inseridas no conjunto de dados. Tais respostas podem ser curtas ou longas, com soluções e exemplos específicos. Modelos treinados escrevem funções e códigos de programas em JavaScript e Python, extraem informações de texto, banco de dados ou documentação quando fazem perguntas.
Revolução multimodal e modelagem imersiva
Ter modelos de IA com informações básicas disponíveis simplifica o trabalho de treinamento e implantação de múltiplas unidades ou dezenas dentro de um circuito de serviço. É importante que os dados do conjunto de dados sejam validados: a precisão e a validade determinam a agregação e a integridade do complexo. Já em 2024, espera-se que o paradigma da multimodalidade ultrapasse a IA e conecte todos os tipos de informação numa única entidade. Os desenvolvedores experientes percebem isso e muitas vezes oferecem soluções combinadas onde diversas categorias de dados são analisadas, processadas e interpretadas.A IA está começando a atuar como treinamento de AR/VR com base no princípio da simulação imersiva. Cenários de treinamento prático realistas proporcionam experiência prática em um ambiente seguro. Portanto, para universidades e faculdades, o treinamento virtual é um passo para que os alunos adquiram habilidades enquanto estudam. Além disso, existe a comodidade acrescida de utilizar a Netflix e a app Instagram técnicas de personalização, considerando os interesses e valor dos materiais de aprendizagem e o progresso dos alunos.
A aceleração do desenvolvimento da esfera da IA mostra que chatbots fáceis de usar e de aprendizagem rápida com aplicações para geração de conteúdo de vídeo, foto e texto, reconhecimento de dados, geração de relatórios e documentação, busca de soluções e verificação do funcionamento de objetos ou sistemas estão aumentando geometricamente. As aplicações de IA assumem funções humanas simples e complexas. A principal tarefa é compor adequadamente um algoritmo de aprendizagem, formar um conjunto de dados e escrever prompts, bem como realizar testes pós-aprendizagem.
Os programadores e desenvolvedores da empresa são fluentes nessas técnicas. Direcione a tarefa no formulário de inscrição.


