
Не претендуючи на те, що вдасться розглянути всі нюанси щодо планування, розробки та тестування ШІ-додатків, вважаємо, що корисні позиції в лонгріді-інструкції та приклади знайдуть як досвідчені розробники, так і початківці. Ареал впровадження технологій, заснованих на застосуванні нейронних мереж, величезний: починаючи зі спрощеного бота-інформатора та закінчуючи додатком, оснащеним функціоналом для планування обсягів торгових операцій, доставки, розрахунку та прогнозування прибутку, контролю співробітників та взаємодії з клієнтами. Приклади вдалих впроваджень ШІ, що розпочиналися з мінімальних вкладень – Grammarly та Duolingo, сервіси Waze та Canva, фоторедактор FaceApp.
Огляд сфер застосування ШІ-додатків
Функціонування ШІ відбувається у прокрустовому ложі кількох правил і категорій, включаючи:- наявність потужних графічних процесорів, тисячогігового обсягу даних та оперативної пам'яті з кількох вузлів, з'єднаних у мережу для навчання моделі;
- вбудовування в ШІ-моделі Інтернету речей та алгоритмів об'єднання інформації з кількох рівнів;
- прогнозування подій, розуміння парадоксальних ситуацій та координацію роботи високоточних систем;
- впровадження API для створення нових протоколів і шаблонів взаємодії.
Стандартне машинне навчання ML замінює оператора на початку спілкування із центром підтримки, базово уточнюючи питання. При глибокому форматі, коли задіяні VCA, відбувається персоналізація запитів, підвищується безпека контактів завдяки розпізнаванню мови та психологічного статусу клієнтів. Автоматизація виконання поточних завдань – пошук квитків, замовлення товарів, вибір точок маршруту – входить до функцій віртуальних операторів. Тому вибір ML чи VCA залежить від вирішуваних питань.
Логістика, оцінка клієнтів та підбір персоналу
Постачання та логістика, що координуються ШІ, спрощують ведення бізнесу, оскільки показують наявність позицій на складі, вказують на резерви, прогнозують ефективність та терміни окупності. Це робота ШІ-додатків та сервісів високого рівня, з ціною від $100.000. Аудит статей доходів та витрат, виявлення трендів із сегментації прибутку – приклад застосування ШІ у фінансовій галузі. Аналогічно діє програма, персоналізуючи кожного клієнта та аналізуючи ефективність продажів: медіастратегії просування покращують маркетингові позиції.NLP-можливості ШІ забезпечують первинний пошук співробітників та визначення їх професійних навичок. У процесі роботи AI-кадровик рекомендує змінити посадові обов'язки персоналу, якщо бачить прогресивне засвоєння навичок та доведення до автоматизму, що сприяє кар'єрному зростанню.
Фундамент: правильні завдання та точні дані
Перші два етапи з планування організаційних та технологічних операцій для розробки ШІ-додатку є фундаментально обґрунтованою програмою з кількома кроками. Наочно видно на схемі, що в першу частину входять постановка проблеми, добір інструментів, очікувані витрати та прибуток, необхідні ресурси. Другий етап відповідає за формування перевірених та точних баз даних, готових до навчання моделі.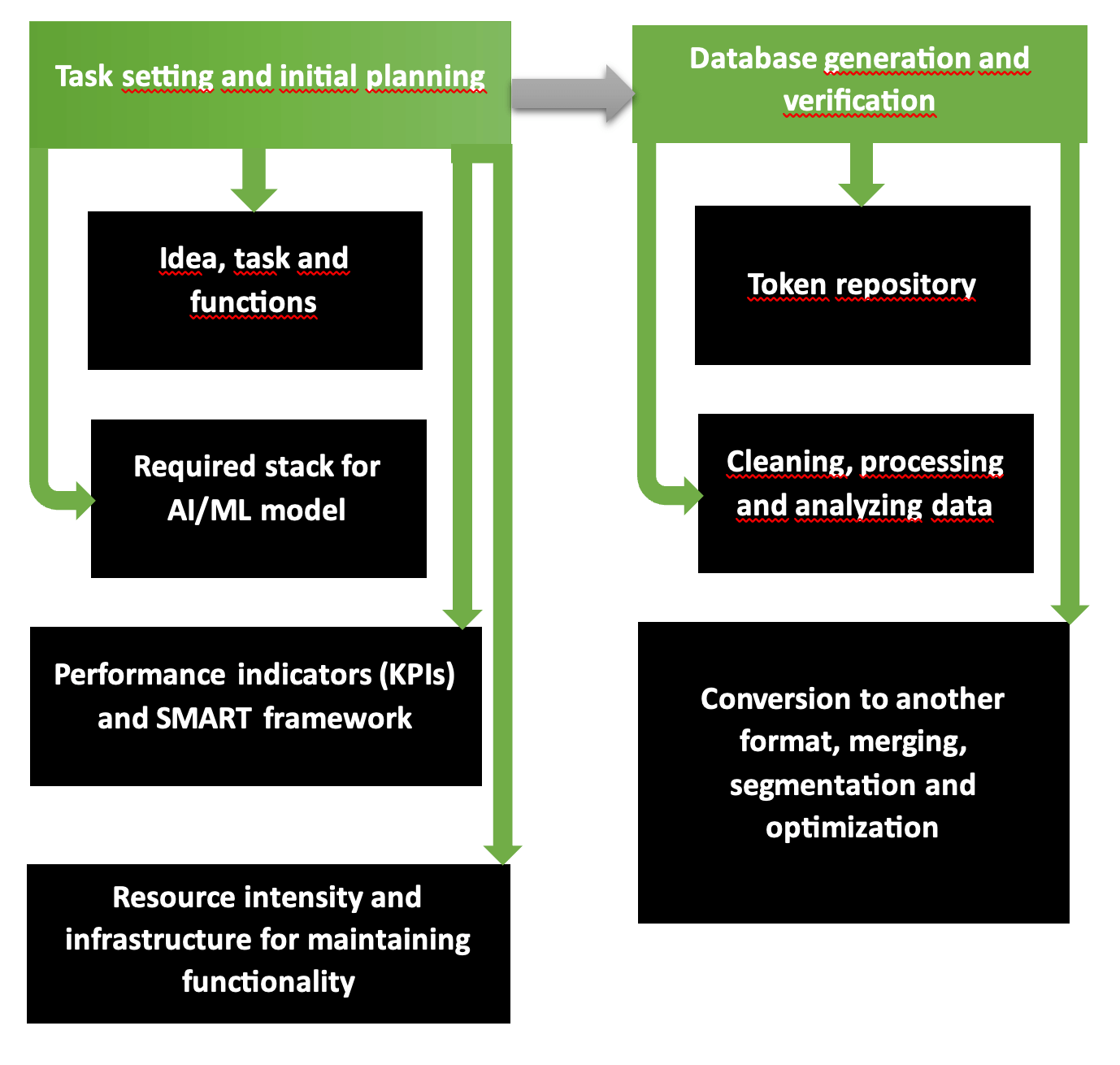
За такою схемою починають працювати розробники кроссплатформенного ШІ-додатку. Ланцюжок «вимоги – мети – узгодження бачення – єдиний стиль» продумується відповідно до структури SMART і розбивається поетапно на категорії у Scrum чи Agile. Завдання та наявність ресурсів визначають, які обсяги послуг і товарів можна надати в запланованому режимі та скоротити чи розширити при дефіциті чи різноманітті фондів.
Сервіс Common Crawl, платформи типу Kaggle або AWS у разі нестачі вихідного цифрового та графічного матеріалу надають бази даних, перевірені щодо точності, інформативності, без повторів і помилок. Щоб перевірити власну базу даних, пропускають через утиліту Tibco Clarity (запуск з 1997 року) або OpenRefine.
Постійне вдосконалення та мультимодальні рішення
Затребувана мова програмування, яка одночасно є основою для створення ШІ-додатків через простоту команд – Python. Кейси продуктових розробників рясніють ШІ-рішеннями для Google і Netflix, - відеохостингів та великих стрімінгових сервісів. AI-додатки потрібно постійно вдосконалювати:- навчати аналізувати секретну та конфіденційну інформацію;
- вилучати неприйнятні та моторошні елементи зі згенерованих фото та відео;
- формувати алгоритми із шифруванням баз даних клієнтів та компаній, з якими підписано договори про співпрацю;
- проводити детекцію щодо наявності аномалій у запропонованих рішеннях, розроблених ШІ.
Обробка модальних даних на кшталт дії моделі Chameleon наближає AI до парадоксально-виключного формату роздумів людини. Авторегресія за протоколом 34B пройшла навчання на 10T токенів даних, тому мультимодальність моделі забезпечує генерацію контенту та картинок з реалістичними параметрами.
4D у моделі PSG4DFormer та розвиток у часовому діапазоні
Навчання згідно з правилами 4D – з урахуванням часу – інтерпретує інформацію (дані, аудіовізуальний контент, відео) за тимчасовою шкалою. Динамічність 4D – це розуміння поточних процесів у часі. Модель PSD-4D формує об'ємні вузли, на ребрах яких розташовані об'єкти, що вивчаються.Потім модель шляхом застосування бази анотованих даних з 4D-масками проводить сегментацію та детально розробляє ситуації у певному часовому діапазоні. Це подібно до розкадрування фільму, коли режисер щохвилини розподіляє сцени та події. Модель PSG4DFormer прогнозує створення масок та подальший розвиток за тимчасовою шкалою. Такі компоненти є основою для генерації майбутніх сцен і подій.
Тестування перед запуском
Прискорення тестування додатків здійснюється шляхом інтеграції пакету Python із фреймворком Django. Python- та веб-розробники, DevOps-інженери для цього використовують вбудовані інструменти Django, пишуть тест-кейси під юніт-перевірки і потім вбудовують пакет у фреймворк.У бібліотеці Featuretools фічі для ML-моделей розробляються автоматично: з бази змінних вибирають ті, які стануть основою навчальної матриці. Дані в часовому форматі та з реляційних баз у процесі генерації стають навчальними панелями.
Бібліотеки, платформи та мови – елементи стека
У переліку фреймворків, що покращують продуктивність ШІ-моделей, відзначаємо бібліотеку з відкритим кодом TensorFlow та платформу TFX, що прискорює розгортання готового проекту. Вони заточені під зображення. Модуль PyTorch написаний кількома мовами, куди входять Python, базова версія C++ та архітектура CUDA, придумана під процесори та відеокарти NVIDIA.При нестачі фізичних середовищ для зберігання та розгортання інформації застосовують хмарні рішення SageMaker, Azure та Google. До нових нових мов для генерації ШІ-програми увійшла Julia: при використанні команд, написаних на ній, більше 81 % команд виконуються швидко, чітко і з мінімумом помилок. JavaScript та Python, R теж показують непогані результати з точністю 75+%.
У стек для програми додаємо середовище JupyterLab, бібліотеку NumPy для багатовимірних масивів або простіше варіант Pandas. Бібліотека Dask призначена для аналізу великих баз даних з кластерами, візуалізації та розпаралелювання, інтеграції з середовищами та системами з метою зниження витрат на апаратне обслуговування.
Особливості XGBoost, TensorFlow, FastAPI
XGBoost 2.0 працює за принципом багатофакторної та квантильної регресії, включаючи безліч ознак у дерево операцій. У новому функціоналі покращено ранжування та оптимізовано розміри гістограм, став зрозумілішим інтерфейс PySpark. Якщо порівняти MXNet і TensorFlow, то краще вибрати останню платформу через краще навчання, налагодження та швидкість завантаження даних.Асинхронність та швидкість операцій FastAPI робить фреймворк кращим за Django, на якому на серверах стандарт WSGI потрібно конфігурувати до нового асинхронного ASGI. Зважаючи на те, що інтерфейсу 6 років, у нього обмежений обсяг даних для JWT-токенів і сховища S3. Беремо до уваги, що асинхронні бібліотеки часто мають проблеми з нечитаністю інформації і іноді доводиться робити записи, задіявши execute() після передачі SQL-запиту та матеріалів. Примітка: атрибут root_path не змінюється на “/api”, що створює незручності.
Контейнеризація, деплой та архітектура ШІ-моделі
Коли компоненти для створення ШІ-програми зібрані разом (код і бібліотеки з фреймворками), запускають процес контейнеризації. Автономний контейнер абстрагується від хоста і без перекомпіляції переноситься до іншого середовища. Docker Engine і Kubernetes - піонери цього сегмента, потрібна ОС - Linux (хмарна або локальна), OCI працюють в режимі читання, без зміни. У цьому списку VMware та LXC. Контейнери іноді зберігають на платформі GitHub: особливо, коли йде спільна робота над проектом.Інструменти для деплою включають пропрієнтарну платформу Heroku, що працює за протоколом PaaS, складнішою Elastic Beanstalk і Qovery, яка взяла краще у обох ресурсів. Для тестування використовують:
- Selenium з трьома видами сервісів WebDriver, IDE та Grid;
- платформу PyTest з масштабованими тестами на версіях Python 3.8+ або PyPy3;
- Locust з тестами навантаження.
| Архітектура моделі | Призначення | Особливості |
| Згорткова (CNN) | Відео та зображення | Точна ідентифікація, усунення шумів та помилок |
| Рекурентна (RNN) | Цифрові дані та мова | Обробка послідовностей |
| Генеративно-змагальна (GAN) | Генерація нових даних та картинок | Імітація з генерацією нових даних, як бази для навчання |
Після цього йде тонке, філігранне налаштування навчання ШІ-моделі. Якщо в сценарій закладені високі вимоги з точними параметрами, навчання продовжується зі спостереженням – такі умови дорожчі. Щоб знайти артефакти та закономірності у кластеризації, бажано зробити вибір самостійного навчання. Для проектів у робототехніці та простих ігор у Телеграм або складних додатках на iOS/Android застосовують підкріплення (заохочення або покарання – метод «батога та пряника»).
Таймінг розробки, перевірка на помилки
Тимчасові витрати на розробку, тестування та запуск ШІ-моделі виглядають приблизно так, як на діаграмі. Алгоритм вимагає точного опису виконання завдань – таким чином, щоб у результаті вийшло нове рішення виявлення закономірностей. Ланцюжок «ітерації – прогнози – корекція» завершують гіперпараметри, введені вручну перед початком перехресної перевірки у підмножинах.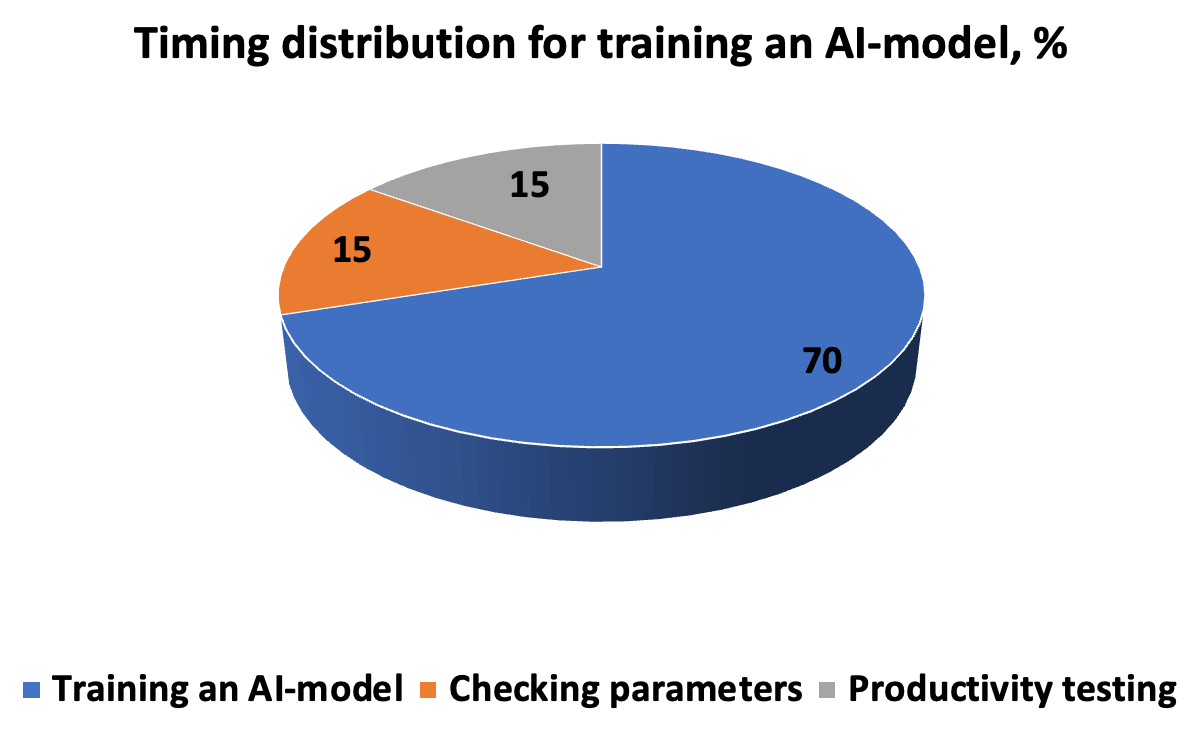
Щоб за умов реальних сценаріїв модель продуктивно працювала, потрібно оцінити правильність і швидкість відповіді. Тому параметри вимірювання включають прецизійність і повторюваність, метрики ROC-AUC, де немає необхідності відсікання порога (для незбалансованої бази даних), F-score, що уточнює частку позитивних рішень, середньоквадратичну помилку MSE і коефіцієнт детермінації R-квадрат. Помилку в межах 5 % вважають допустимою, при зменшенні до 1 та 0,1 % результат відносять до високоточних.
RAG та налаштування, інтеграція в бекенд або фронтенд, тестування
Метод RAG застосовується для розробки генеративних моделей, коли вектори та семантика наближені один до одного за сегментами, виходячи з контексту та релевантності. Основа RAG – вилучення інформації з об'ємних баз даних і подальша генерація моделі для отримання точної відповіді. У тонку настройку для спеціалізованих експериментів входять нормалізація (приведення до єдиних параметрів) і, після адаптації, токеїнізація. Щоб ШІ-модель продуктивно працювала, інтеграція проводиться, залежно від завдання, у бекенд чи фронтенд. Мовну модель краще вбудувати в серверну частину, до роботи з клієнтами – в інтерфейс.В IoT краще периферична робота на пристрої, оскільки зберігає конфіденційність і забезпечує швидкодію. На базі IoT відбувається генерація даних, суть якої в конвергенції ШІ з IoT. Така синергія збільшує функціональність двох елементів, породжуючи AIoT. Але для посилення потужності та масштабованості функціоналу краще застосовувати хмарні технології, використовуючи вбудовані API-протоколи. Якщо важливо почути відгук клієнтів (зручність, зрозумілість, швидкість), то вбудовуємо функцію зворотного зв'язку.
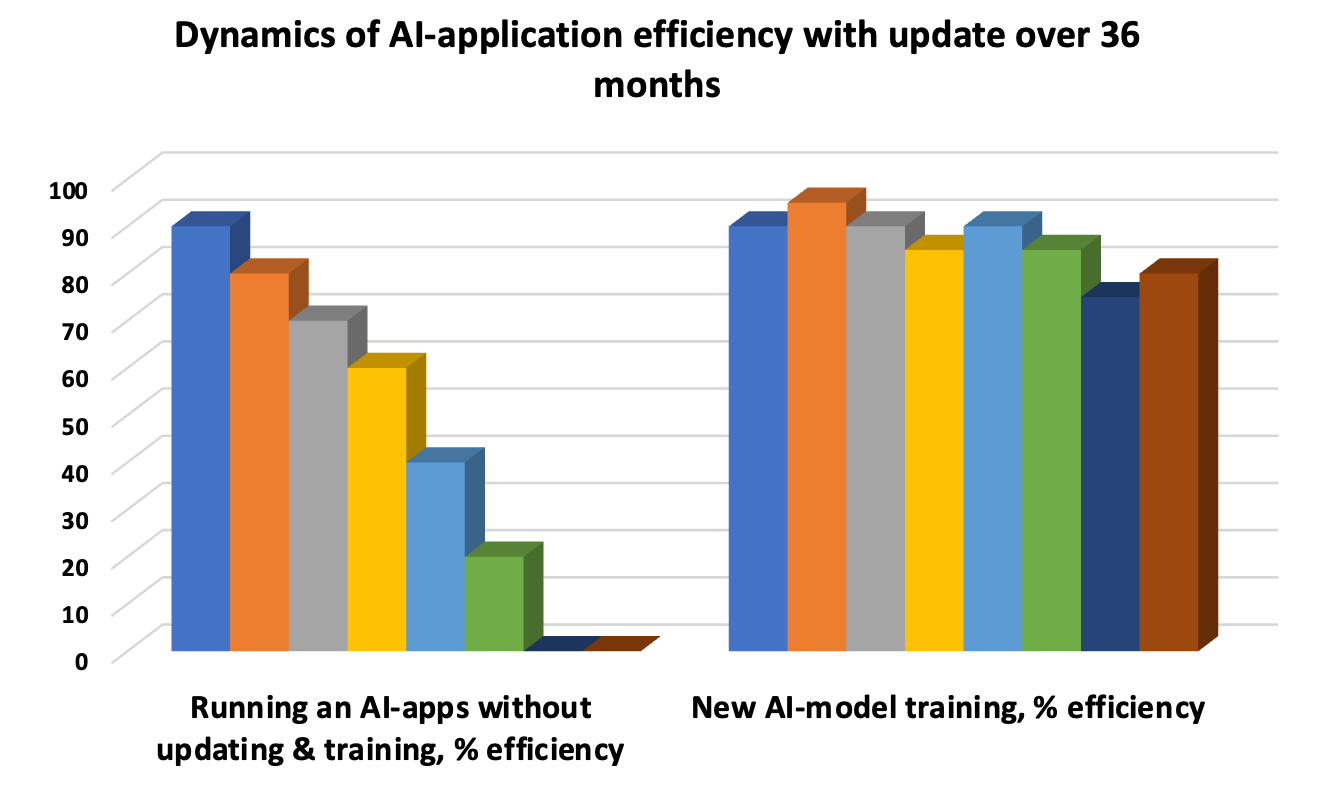
Оновлення ШІ-моделі – необхідність уникнення «дрейфу», коли базові шаблони старіють і точність відповіді знижується. Тому тестування з ітераціями продовжує життєвий цикл моделі. Автоматизоване модульне тестування, періодичне інтеграційне для оцінки сукупності роботи окремих функцій та приймальне UAT – три обов'язкові «кити» оцінки роботи та тестів.
ZBrain – відкритий код та безшовна інтеграція
Прикладом платформи для симбіозу корпоративних процесів та інформації з вбудовуванням ШІ-функціоналу є ZBrain. Відкритий код із шаблонами та пам'яттю, інтегрованими LLM, забезпечують:- зберігання та обмін фіату та криптовалюти в парах, з реєстрацією операцій за принципом блокчейн;
- продуктивну роботу на зрозумілій та докладній інфопанелі;
- управління мультиплатформенними та кросплатформовими додатками на мікро- та макроетапах;
- впровадження когнітивних технологій та проектно-орієнтованих рішень.
Це наочна демократизація та спрощення трансформації бізнес-процесів, коли самі користувачі без написання коду розробляють та розгортають ШІ-моделі стосовно логіки та робочих процесів маркетингу та виробництва. Так, безшовна інтеграція Flow динамічно вибирає потрібні дані та на їх основі готує ШІ-рішення.
Квантові обчислення: уникнути вузьких місць Неймана і знизити енерговитрати
Для обробки великих масивів даних застосовують квантові обчислення. Алгоритми, що використовуються у квантових технологіях, прискорюють процеси ШІ-навчання в галузі медицини, матеріалів, біологічних та хімічних процесів, зменшують викиди СО2 та парникових газів. Щоб залучити навчання на мільярдах властивостей, необхідні надпотужні графічні процесори або TPU, заточені під проведення кількох паралельних операцій.Одночасно потрібно подолати проблеми вузьких місць Неймана (VNB), щоб процесор не чекав, коли оперативна пам'ять (ОЗП) забезпечить доступ до процесу. Завдання – збільшити швидкість отримання та передачі з бази чи сховища. Навіть висока швидкість багатоядерних процесорів при обсязі ОЗП в 32-64 Гб і більше може не виправдати вкладення потужності при обмеженні передачі інформації з «хмари». Для вирішення проблеми VNB розширюють кеш, вводять багатопотокову обробку, змінюють конфігурацію шини, доповнюють ПК дискретними змінними, використовують меристори і обчислюють в оптичному середовищі. Є також моделювання за принципом біологічних процесів, таких як квантування.
Цифрова парадигма ШІ при паралельній обробці збільшує енерговитрати та час процесів навчання. Тому кубити в суперпозиціях (кілька положень в один період часу) і положенні заплутаності краще класичних бітів за умови збереження стабільності. Для ШІ квантові технології краще через зниження вартості розробки та аналізу даних у кількох конфігураціях. "Тензоризація" стискає ШІ-моделі та забезпечує розгортання на простих пристроях при покращенні якості вихідних даних.
Правила кіберзахисту
Приділяйте увагу кіберзахисту – ШІ-алгоритми виявляють закономірності в діях, що несуть загрозу, прогнозують можливі кіберзагрози, захищають конфіденційність, що є імперативом у юридичній сфері та етиці. Правила GDPR та CCPA, як і інші протоколи захисту, повинні підтримуватись шляхом гарантування:- анонімності клієнтів та відсутності лазівок їх ідентифікації сторонніми особами;
- диференціації неприпустимі для розголошення конфіденційних моментів у паспортних даних, електронній пошті, номерах телефонів та інших документах;
- спільного аналізу сегментів інформації у двох-трьох роз'єднаних системах, без розкриття повної бази.
Отруєння моделей (використання шкідливих елементів) в ШІ, наявність змагальних уразливостей призводять до помилкової класифікації. Тому цілісний підхід повинен включати принципи захисту, починаючи зі стадії розробки до тестування та розгортання, щоб мінімізувати виклики та ризики.
Робота ШІ: експертна та НЛП, за генетичними алгоритмами та творча
Виявлено ключові особливості навчання ШІ у разі, коли поставлено мету вирішувати завдання на рівні експерта, орієнтуючись на міркування та аналіз багатомільйонної емпіричної бази даних з наочним розглядом конкретних ситуацій. Наприклад, за вегетаційним індексом NDVI визначають рівень зростання рослинності. Але є нюанси – одна річ, коли вегетація йде зернових чи олійних культур, інша – бур'янів. ШІ в додатку повинен зуміти розрізнити за кольором, що краще росте і відповісти. Аналогічно – розпізнати тип обличчя, лінійні параметри фігури для рекомендацій щодо вибору косметики або одягу для аутфітів.При плануванні роботи ШІ як психолога в алгоритми впроваджують принцип НЛП – відбувається аналіз природного мовлення, уточнення психоемоційного настрою пацієнта. Тоді на запитання надходить згенерована відповідь, наближена до людського звучання та інтонацій. Є ще генетичні алгоритми, коли вирішення мільйонів завдань створюють ботів і потім відсікають гірших, залишаючи кращих. Поєднання вдалих розробок та подальша генерація нових пристосованих та апробованих моделей, на базі попередників та низки ітерацій, призводить до повноцінного вирішення задачі.
Підхід до розробки ШІ-додатку має бути творчим. Припустимо, зробити чат-бот у вигляді веселої тварини або птиці, смішного ельфа чи одухотвореної рослини або прагматичні речі типу торговельного бота. Ті, хто читав Курта Воннегута, пам'ятають розповідь про суперкомп'ютер, який отримав людське мислення. Тому, якщо персонаж озвучуватиме репліки, використовуючи попереднє спілкування, підказуватиме і коротко прес-релізуватиме про новинки, клієнти полюблять і звикнуть до ШІ, будуть довіряти. Зростання продажів складе щонайменше 10–20%.
MVP, CRISP-DM та розцінки
Перший крок після розробки штучного інтелекту у додаток – запуск MVP з аналізом та підтримкою, покращенням функціоналу та перманентним тестуванням. Якщо в планах компанії – підтримка ШІ-програми протягом 10–20 років, то необхідне регулярне щоквартальне оновлення баз даних, тестування за різними типами згідно методології CRISP-DM.Щоб визначити фінансові витрати та тимчасові витрати, зверніться до Merehead із завданням та питаннями: ціна розробки штучного інтелекту починається з $20.000 і займає терміном до кварталу. Час розробки додатків середньої складності з логічними ланцюжками на трьох-п'яти рівнях вдвічі більший і ціна сягає $100.000. Для складних математичних проектів з експертним аналізом та точністю відповідей 99,9 % – до $500.000. Перед початком роботи розробимо дорожню карту проекту та сплануємо очікувані результати рентабельності.


