
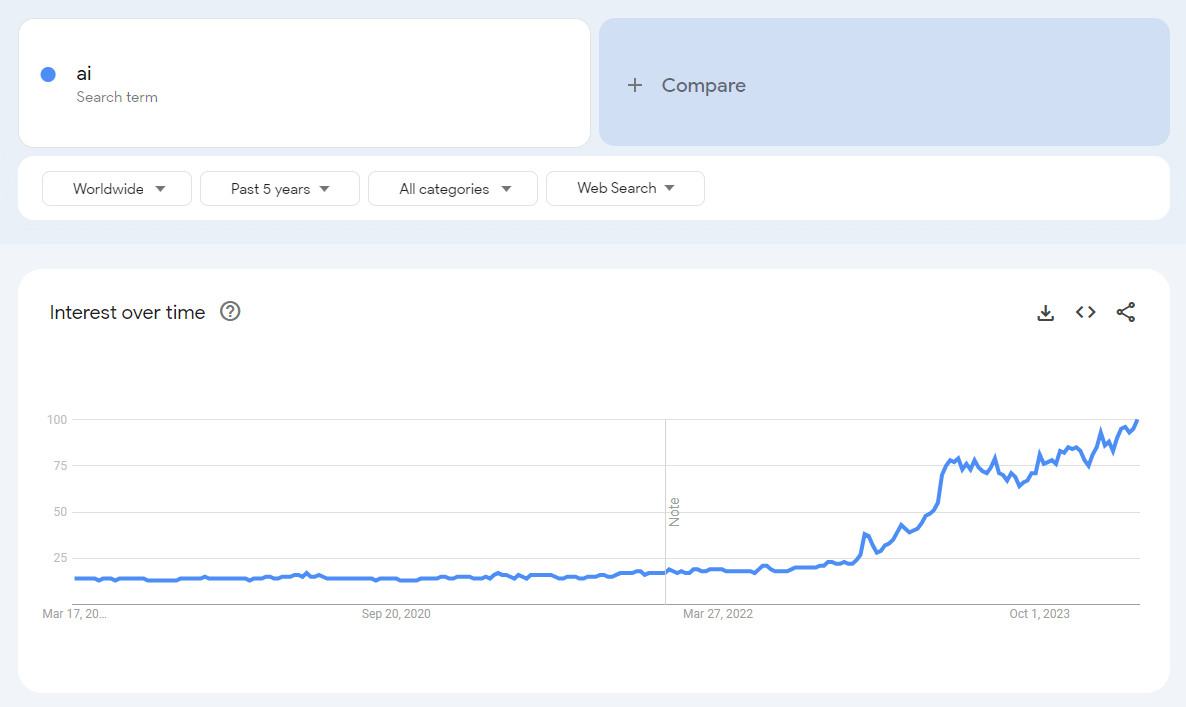
Епоха штучного інтелекту вибухнула давно. Люди звикли до миттєвої ідентифікації та реєстрації, швидшого пошуку транспорту та маршрутів, зручного вибору товарів та використання сервісів Штучного Інтелекту. AI став надійним помічником бізнесу, замінив співробітників і звів до нуля ймовірність помилок через людський фактор. Рутинну роботу віднесено до розряду робіт, переданих на аутсорсинг ШІ, а творчими завданнями займаються провідні спеціалісти.
Програми та нейронні мережі, алгоритми дій ШІ
Кожна з ІТ-компаній розробляє моделі та алгоритми, програми та чат-боти на основі штучного інтелекту, використовуючи машинне та глибоке навчання для аналізу цифрових даних. Для складних додатків у бізнесі підключаються нейронні мережі. Візуалізація за допомогою штучного інтелекту – це розпізнавання та тривимірне комп’ютерне бачення.Перспективні банківські програми часто базуються на роботі розумного помічника ШІ. Операції, які виконує Штучний Інтелект за уточненими критеріями на біржах, купівля, продаж – повсякденне життя. Попередній відбір кадрів за конкретними показниками, первинна діагностика пацієнтів, налаштування дій безпеки при спрацьовуванні певного тригера також є результатом мислення ШІ. Про генерацію текстів середнього рівня, зображень і відеоконтенту ходять чутки вже кілька років.
Аналіз зображень квадрокоптера FPV є зручним способом оцінки місцевості в режимі реального часу. Його можна налаштувати для надсилання безпосередньо в центр обробки даних для прискореного прийняття рішень за допомогою ШІ в базових ситуаціях. Автоматизація процесів є однією з інших переваг впровадження ШІ.
Розпізнавання та верифікація, діагностика та прогноз за допомогою ШІ
Приклади того, як штучний інтелект можна використовувати в бізнес-операціях туристичних агентств, включають розпізнавання паспортів, страховок і документів подорожуючих. Ці дані легко вводити в форми заявки або контракти з мінімальною частотою помилок до 1-5%. Розпізнавання нейронної мережі навчається шляхом аналізу фотографій і тексту в просторі з адаптацією та перевіркою, формування відповіді API. Саме програмне забезпечення, створене за технологіями RPA, можна інтегрувати в будь-яку CRM систему або чат-бот, кабінет користувача.Робот RPA завершує рутинну документацію, генерує звіти та виконує операції для встановлення робочого часу. Навчання здійснюється за допомогою машинного навчання ML. Створення та навчання нейронних мереж, як згорткових, так і генеративних в архітектурі, є одним із часто використовуваних методів машинного навчання. Нейронні мережі мають можливість прогнозувати торгівлю акціями та ціни криптовалюти, діагностувати захворювання чи функціональні порушення. З їх допомогою вчені роблять прогнози щодо якісних характеристик препаратів на основі компонентів, оцінюють стан проектованого об’єкта чи сплаву.
Моделювання рішень за допомогою Data Science
Недостатньо створювати бази даних і показувати їх ШІ: потрібно навчити його розпізнавати ситуації, коли потрібно швидко дати чітку відповідь. Це ситуації, коли реляційні бази даних не можуть знайти правильне рішення. Такими питаннями займаються аналітики Data Science. Вони відповідають за визначення алгоритмів і умов математичної моделі, за якої вона реалізується:- моделювання процесу;
- сегментація та персоналізація клієнтів, ключові запити;
- релевантність пропозицій.
Для візуалізації процесу припустимо, що людина їде в машині. У нього був телефонний дзвінок, який спровокував сплеск ендорфінів. В результаті серцебиття прискорилося, але знизилася концентрація уваги, з'явилося бажання «швидко покататися». Трекер на вашій руці виявляє це та передає інформацію системі ШІ автомобіля. ШІ попереджає - рекомендує знизити швидкість (або робить це сам), зменшує тепло в салоні і відкриває вікно.
Виклик для ШІ
ШІ — це просто не людське мислення. Комп’ютери виконують те, що від них вимагає програміст – обчислюють, обчислюють, виконують певні дії. Ви можете поставити завдання голосом або текстом, але перед цим вводите правила та обмеження, залежності, в тому числі статистичні. Алгоритми перетворення являють собою покрокові схеми: «Опис» — «Правила» або «Задача» — «Рішення». Прогноз працює, якщо ввести кілька ситуацій з прикладами.Розглянемо наступне завдання: «Напишіть програму на Python для отримання прибутку на ринку. Початковий капітал 100 тисяч доларів, очікуваний прибуток 10% від інвестицій, кількість товарів на ринку 10000, середня ціна одного товару 50 доларів, комісія 3%".
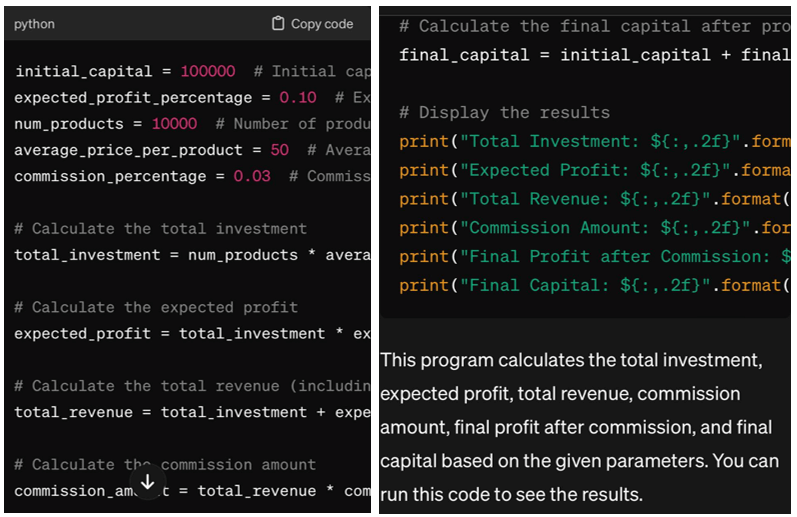
Результатом буде згадана вище відповідь, яка обмежена через введення невеликої кількості показників в умови задачі. Чим детальніші фактори та більший розмір набору даних, тим менша помилка в остаточному рішенні. Навчаючи ШІ, програміст вводить початкову інформацію та позначає тегами кожен фрагмент. Коли база даних з контрольними маркерами накопичена, навчання переходить до етапу пошуку правил і перевірки в прогнозуванні.
Сценарії та помилки покрокового моделювання
Кожен етап — це пошук заданого шаблону та пошук нового з певним параметром. Наприклад, якщо прийшов автомобіль Mersedes, потім Audi і Honda, наступним може бути BMW або Mitsubishi. Якщо немає необхідності шукати шаблони, то відключаємо цю функцію і використовуємо рішення попередніх кроків. Сценарій, коли після першого маркера йде запитання, а за наступним маркером – відповідь, робить алгоритм зручним, оскільки він дасть відповідь на будь-які запитання в межах інформаційної бази. Зрозуміло, що в кожному алгоритмі передбачення є помилка.Прийнятно, якщо похибка знаходиться в межах 5%. Стохастична модель підходить, коли немає впевненості в діапазоні вхідних або вихідних даних. Локальна функція з однозначним відображенням керується ідентифікаторами об’єктів. Прості функції є однопараметричними, обчислення в них проводяться за допомогою коефіцієнтів, а не за допомогою тверджень, хибно чи істинно.
Алгоритми аналізу, результати та функції
Кожен алгоритм розбивається на кроки: умови та переходи, кожен із яких закінчується оператором результату, але не поверненням. Порівняння з константою, яка є певною точкою або кроком алгоритму, є основою безперервного прогнозування. Його можна порівняти з кореляційним пошуком, коли дані корельованих ознак накопичуються та об’єднуються в групи. Потім за результатом отриманої основи вибирається загальний стан і відстань між заданим параметром і результатом розрахунку.Це виглядає так:
- формування функцій з одним параметром;
- вибір частин з однаковими умовами;
- створення нової функції з двома параметрами;
- уточнення лінійності в багатопараметричних базах.
Перетворення передбачає алгоритми пошуку рішень і створення правил на основі відповідей. Іноді в результаті виходить рекурсія з кількома рівнями або фрактал. Контрольні маркери відповідають на запити та виробляють остаточні розрахунки, враховуючи швидкість процесу, прискорення та помилку. Тим не менш, алгоритми засновані на статистиці.
Самостійність і автономія: баланс між аналізом і рішеннями
Для комп'ютера невластиво шукати рішення або проводити дослідження без завдання. Навіть умовно запрограмований як людська особистість, без завдання ПК не виконуватиме конкретних дій. Формальна логіка тут не працює, потрібні математика і статистика. Рішення, прийняті ШІ автономно, підлягають аналізу: якщо вони виходять за межі алгоритмів і скриптів, але є кращим варіантом, то це є підтвердженням правильності рішення про «автономність».Принципи ШІ:
- прогнозний аналіз із виявленням закономірностей і тенденцій застосовується для прогнозування на основі закономірностей і ймовірності подій;
- мультимодальність передбачає одночасну обробку інформації з кількох джерел і типів даних;
- мультидисциплінарний метод нагадує науковий метод, оскільки він бере участь у перетині кількох наук та їхніх галузей, щоб покращити продуктивність ШІ.
Максимальний рівень аналізу – на ASI, що нагадує людське мислення. Інтелект AGI близький до середнього рівня людського мислення. АНІ - це типовий виконавець, який не виходить за межі письмових програмних завдань.
Навчання з числами, розпізнаванням і неповною інформацією
Накопичення величезної кількості даних вимагає навчання ШІ. Для машинного формату використовуються лінійна та багатовимірна регресія, опорні вектори, дерево рішень із підкатегоріями та сусідами KNN. Навчання з підкріпленням включає алгоритми для роботів. Спілкування через мобільний месенджер є результатом використання Transformers після обробки людської мови. Завдання НЛП - розпізнавання тексту та аудіо, переклад і генерація контенту. 6 років тому програмісти Facebook на основі даних Amazon (6 тисяч реальних діалогів) розробили бота, який нічим не відрізнявся від людини, міг торгуватися і навіть шахраювати. Це показує, що завдання ШІ в маркетингових схемах і розвагах різноманітні:- у роздрібному бізнесі продумують алгоритми розробки акцій і пропозицій про купівлю;
- в ресторанному бізнесі створюють інтер'єри та оригінальні меню;
- в ігровій індустрії після поглибленого навчання вони розвивають ідеальний розум, що складається з менеджера штучного інтелекту та агентських програм «гібридної архітектури».
Дивлячись на приклад програми Libratus, стає зрозуміло, що ШІ складається з кількох частин. Аналітична центральна частина взаємодіє з другою частиною, яка відстежує помилки суперників, і третьою частиною, яка аналізує помилки у власних діях. Це приклад використання неповної інформації для надання повної вичерпної відповіді в індустрії кібербезпеки, військовій сфері та переговорах.
Шаблони з правильними рішеннями та роботою ChatGPT-3.5
12 років тому економісти Шеплі та Рот отримали Нобелівську премію за теорію стабільного розподілу. Рішення математиків були підтверджені в ІТ: методи унімодального та бімодального розподілу працюють, якщо набрати багатомільярдну базу даних і потім проаналізувати її у формі гістограм. Розробники в лабораторіях OpenAI і Google, Microsoft постійно стежать за навчанням ШІ, відсікаючи некоректні рішення і створюючи шаблони на основі правильних. У світі зареєстровано 60 тисяч ІТ-компаній, які займаються розробкою програмного забезпечення на основі ШІ.
Версія ChatGPT 3 використовувала лише 175 мільярдів джерел. Версія 5, яка буде випущена до кінця 2024 року, одночасно генеруватиме текстовий та аудіовізуальний контент. Кількість джерел для розробки в 100 разів перевищує обсяг даних ChatGPT-3. Розширена та потужна версія аналізуватиме дані, працюватиме як основа для чат-ботів, генеруватиме код та виконуватиме інші функції віртуального помічника. Поки що модель 3.5 працює так і є схильною до помилок.
Продукти ШІ Google і Microsoft
Перевірені програми ШІ включають DALL-E, який генерує та редагує зображення та робить колажі. Whisper - універсальний AI транскриптор, який може розпізнавати мову та перекладати. CLIP - аналогізатор картинок і фотографій. Gym Library та Codex – платформи для програмістів на основі ШІ. У списку Google є 15 подібних мобільних додатків на Андроїд і платформ ШІ. Правда, в їх роботі часто трапляються баги і помилки.Алгоритми ШІ використовуються в Google Photos і Youtube, перекладачі для покращення функцій і аналізу даних. Чат-бот Google Bard є аналогом ChatGPT, але має власну мову PaLM 2. Це можна використовувати одночасно з Gemini, який має високий рівень генерації та аналізу. Imagen AI генерує зображення, Generative AI тестує генеративні моделі навчання. Vertex AI допомагає вченим обробляти дані, Dialogflow — для створення чат-ботів.
Платформи штучного інтелекту Microsoft включають універсальну енциклопедію Copilot, службу розробника Azure Space, яка генерує зображення, зображення та логотипи, ескізи Image Creator.
Британська та тайванська Foxconn використовуватимуть ШІ
У британському кадастрі HMLR, де реєструються права власності на землю та власність, половину роботи виконує ШІ. Відстеження продуктивності програмного забезпечення та додатків виконує APM, тому Atlassian використовує інструменти платформи на основі штучного інтелекту для моніторингу процесів і перевірки відсутності помилок. Тому штучний інтелект часто використовується для профілактичного обслуговування життєво важливих систем, оцінки технічного стану для запобігання простою та аварій.Бізнес-прогнозування проекту або конкретної бізнес-операції підвищує точність і економить бюджет. Наприклад, Foxconn, тайванський виробник компонентів для смартфонів і продуктів Apple, заощаджує понад півмільйона доларів на мексиканському заводі завдяки розробці AI на основі Amazon Forecast.
Глибоке навчання та школи для ШІ
Програмісти та розробники навчають штучні нейрони (вузли) вирішувати проблеми за допомогою методів глибокого навчання. Це включає в себе алгоритм NLP для обробки мови, значення та тону, а також генеративний штучний інтелект, аудіо-, відео- та текстовий вміст і артефакти якого схожі на людські. Необроблені дані - ресурси з підрівнями - представляють операційну інфраструктуру, на якій відбувається навчання. Вони можуть зберігатися як на фізичних ресурсах, так і в хмарі.Своєрідні «школи» для ШІ – платформи на зразок TensorFlow чи PyTorch. Доступна бібліотека з відкритим кодом Scikit-learn, написана на Python. Для навчання формуються функції та складаються класи відповідно до плану архітектури додатку ШІ. На рівні моделювання визначається потужність, потім сегментація за рівнями та функціональність активації.
Розробники аналізують, як нейрони змінюють вагу своїх сусідів під час спілкування, і оцінюють вузли зміщення. Прогноз і реальні дані не повинні сильно відрізнятися один від одного - для цього використовується порівняння за допомогою функції втрат. У цьому процесі допомагають такі оптимізатори, як градієнтний спуск або адаптивні градієнтні послідовності, що враховують мінімуми та максимуми, а також швидкість змін. ШІ у форматі програми обслуговує клієнта, а не співробітника.
Створення набору даних, використання GPU та базової моделі
Універсальність моделі GPT зумовлена правильністю підходів до швидкого навчання, налаштуванням під конкретні питання, роботою з набором даних та обчислювальною потужністю. У компанії, яка займається навчанням моделей штучного інтелекту, є сотня-дві GPU і більше. Вони відповідають за обчислення та обробку графічної інформації, навчання моделей до 10-30 днів, залежно від складності. Чим більше параметрів у наборі даних, тим вища ціна.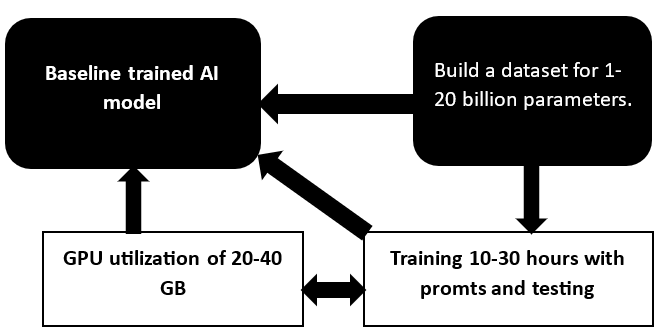
Працюють спрощені моделі з відкритим кодом. Незважаючи на низький поріг входу, вони показують високі результати в бенчмарках. Ціна навчання простих додатків з базою від комплексу GPT-4 з Google Bard або LLaMA з Evol-Instruct починається від $500-1000. Кожну базу в цих версіях легко доопрацювати та отримати індивідуальну авторську програму, яка є кращою за платну.
Клієнти повинні знати, що об’єм пам’яті для розробки спрощених додатків штучного інтелекту відносно малий, і потрібні графічні процесори з 40–80 ГБ пам’яті. Генеративні системи штучного інтелекту також розробляються з використанням хмарних технологій на основі правильних сервісів і наборів даних. Конвеєр добре працює в хмарі, починаючи з обробки набору даних, збору інформації та аналізу даних. Часто правильна модель уже встановлена, тому потрібне навчання та налаштування деяких параметрів за допомогою адаптерів. Щоб представити обсяг інформації, запам’ятайте емпіричне правило: 10-15 мільярдів параметрів вміщаються в графічний процесор 16-24 або 40 ГБ.
Модель LLM з методом PEFT, спрощений сценарій
Якщо використовувати навчену модель LLM як основу, метод PEFT розширить бажану підмножину параметрів, але залишить непотрібні в «замороженому» стані. Аналітики компанії в брифі з’ясовують, які параметри цікавлять клієнта, і тренуються на основі обраних. Виходить часткове навчання, результат якого не гірше повного курсу навчання. Тому в процесі консультації із замовником IT-спеціалісти відразу уточнюють, чи потрібно їм згенерувати набір рішень з інструкціями та умовами або самостійно створити навчальні програми з парами запитань і відповідей.Стандартний сценарій навчання в хмарі передбачає масштабовані хмарні ресурси в хмарі, керування хмарними провайдерами та використання готових служб як інструментів навчання. Протокол ML-development зі сценаріями генерації та обробки вихідних даних, експериментів з керуванням версіями, розгортання та вбудовування моделі, подальших оновлень працює без ручного налаштування. Ось приклад повного рішення для платформи – поєднання JupyterHub для експериментів, MLflow для розгортання та взаємодії Data Science і завдань, середовища MLflow Deploy для упаковки та розгортання.
Ця навчена GPT модель відповідає на питання, для яких інформація вводиться в набір даних. Такі відповіді можуть бути короткими або розширеними, з конкретними рішеннями та прикладами. Навчені моделі пишуть функції та програмні коди на JavaScript і Python, витягають інформацію з тексту, бази даних або документації, коли їм задають запитання.
Революція мультимодальності та захоплююче моделювання
Наявність моделей штучного інтелекту з доступною базовою інформацією спрощує роботу з навчання та розгортання кількох одиниць або десятків у межах циклу обслуговування. Важливо, щоб дані набору даних були перевірені: точність і валідність визначають сукупність і цілісність комплексу. Очікується, що вже в 2024 році парадигма мультимодальності обійде ШІ та об’єднає всі типи інформації в єдине ціле. Досвідчені розробники це розуміють і часто пропонують комбіновані рішення, де аналізуються, обробляються та інтерпретуються кілька категорій даних.ШІ починає діяти як навчання AR/VR на основі принципу захоплюючої симуляції. Реалістичні сценарії практичного навчання забезпечують практичний досвід у безпечному середовищі. Тому для університетів і коледжів віртуальне навчання – це крок до отримання студентами навичок під час навчання. Крім того, є додаткова зручність використання технік персоналізації Netflix і TikTok, враховуючи інтереси та цінність навчальних матеріалів і прогрес студентів.
Прискорений розвиток сфери штучного інтелекту показує, що геометрично зростає кількість зручних і швидконавчальних чат-ботів із додатками для генерації відео, фото та текстового контенту, розпізнавання даних, створення звітів та документації, пошуку рішень і перевірки функціонування об’єктів чи систем. Програми ШІ беруть на себе прості та складні людські функції. Основне завдання — правильно скласти алгоритм навчання, сформувати набір даних і написати підказки, а також провести тестування після навчання.
Програмісти та розробники компанії вільно володіють цими прийомами. Дайте завдання в аплікаційній формі.


