
Не претендуя на то, что удастся рассмотреть все нюансы по планированию, разработке и тестированию ИИ-приложений, считаем, что полезные позиции в лонгриде-инструкции и примеры найдут как опытные разработчики, так и начинающие. Ареал внедрения технологий, основанных на применении нейронных сетей, огромен: начиная с упрощенного бота-информатора и заканчивая приложением, оснащенным функционалом для планирования объемов торговых операций, доставки, расчета и прогнозирования прибыли, контроля сотрудников и взаимодействия с клиентами. Примеры удачных внедрений ИИ, начинавшихся с минимальных вложений – Grammarly и Duolingo, сервисы Waze и Canva, фоторедактор FaceApp.
Обзор сфер для применения ИИ-приложений
Функционирование ИИ проходит в прокрустовом ложе нескольких правил и категорий, включая:- наличие мощных графических процессоров, тысячегигового объема данных и оперативной памяти из нескольких узлов, соединенных в сеть для обучения модели;
- встраивание в ИИ-модели Интернета вещей и алгоритмов объединения информации с нескольких уровней;
- прогнозирование событий, понимание парадоксальных ситуаций и координацию работы высокоточных систем;
- внедрение API для генерации новых протоколов и шаблонов взаимодействия.
Стандартное машинное обучение ML заменяет оператора в начале общения с центром поддержки, базово уточняя вопросы. При глубоком формате, когда задействованы VCA, происходит персонализация запросов, повышается безопасность контактов благодаря распознаванию речи и психологического статуса клиентов. Автоматизация выполнения текущих задач – поиск билетов, заказ товаров, выбор точек маршрута – входит в функции виртуальных операторов. Поэтому выбор ML или VCA зависит от решаемых вопросов.
Логистика, оценка клиентов и подбор персонала
Поставки и логистика, координируемые ИИ, упрощают ведение бизнеса, так как показывают наличие позиций на складе, указывают на резервы, прогнозируют эффективность и сроки окупаемости. Это работа ИИ-приложений и сервисов высокого уровня, с ценой от $100.000. Аудит статей доходов и расходов, выявление трендов по сегментации прибыли – пример применения ИИ в финансовой отрасли. Аналогично действует приложение, персонализируя каждого клиента и анализируя эффективность продаж: медиастратегии продвижения улучшают маркетинговые позиции.NLP-возможности ИИ обеспечивают первичный поиск сотрудников и определение их профессиональных навыков. В процессе работы AI-кадровик рекомендует изменить должностные обязанности персонала, если видит прогрессивное усвоение навыков и доведение до автоматизма, что способствует карьерному росту.
Фундамент: правильные задачи и точные данные
Первые два этапа по планированию организационных и технологических операций для разработки ИИ-приложения представляют собой фундаментально обоснованную программу с несколькими шагами. Наглядно видно на схеме, что в первую часть входят постановка проблемы, подбор инструментов, ожидаемые затраты и прибыль, нужные ресурсы. Второй этап отвечает за формирование проверенных и точных баз данных, готовых к обучению модели.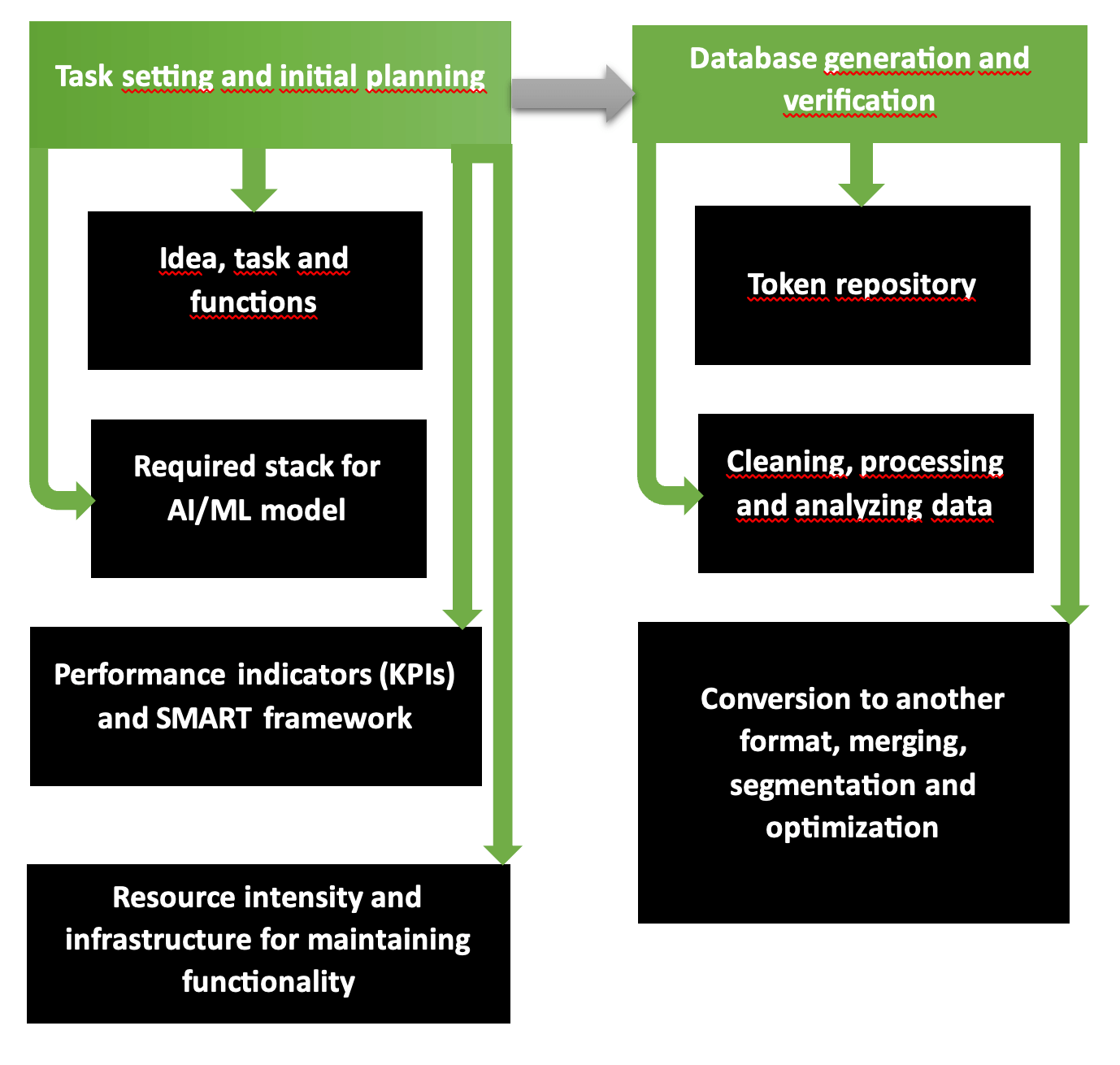
По такой схеме начинают работать разработчики кроссплатформенного ИИ-приложения. Цепочка «требования – цели – согласование видения – единый стиль» продумывается согласно структуре SMART и разбивается поэтапно на категории в Scrum либо Agile. Задачи и наличие ресурсов определяют, какие объемы услуг и товаров можно предоставить в планируемом режиме и сократить либо расширить при дефиците или обилии фондов.
Сервис Common Crawl, платформы типа Kaggle либо AWS в случае нехватки исходного цифрового и графического материала предоставляют базы данных, проверенные на предмет точности, информативности, без повторов и ошибок. Чтобы проверить собственную базу данных, пропускают через утилиту Tibco Clarity (запуск с 1997 года) или ПО OpenRefine.
Постоянное совершенствование и мультимодальные решения
Востребованный язык программирования, который одновременно представляет основу для создания ИИ-приложений ввиду простоты команд – Python. Кейсы продуктовых разработчиков пестрят ИИ-решениями для Google и Netflix, видеохостингов и крупных стриминговых сервисов. AI-приложения нужно постоянно совершенствовать:- обучать анализировать секретную и конфиденциальную информацию;
- удалять неприемлемые и жуткие элементы из сгенерированных фото и видео;
- формировать алгоритмы с шифрованием баз данных клиентов и компаний, с которыми подписаны договора о сотрудничестве;
- проводить детекцию на предмет наличия аномалий в предлагаемых решениях, разработанных ИИ.
Обработка модальных данных по типу действия модели Chameleon приближает AI к парадоксально-исключающему формату размышления человека. Авторегрессия по протоколу 34B прошла обучение на 10T токенов данных, поэтому мультимодальность модели обеспечивает генерацию контента и картинок с реалистичными параметрами.
4D в модели PSG4DFormer и развитие во временном диапазоне
Обучение согласно правилам 4D – с учетом времени – интерпретирует информацию (данные, аудиовизуальный контент, видео) по временной шкале. Динамичность 4D – это понимание текущих процессов во времени. Модель PSD-4D формирует объемные узлы, на ребрах которых расположены изучаемые объекты.Затем модель путем применения базы аннотированных данных с 4D-масками проводит сегментацию и детализированно разрабатывает ситуации в определенном временном диапазоне. Это сходно с раскадровкой фильма, когда режиссер поминутно распределяет сцены и события. Модель PSG4DFormer прогнозирует создание масок и последующее развитие по временной шкале. Такие компоненты представляют собой основу для генерации будущих сцен и событий.
Тестирование перед запуском
Ускорение тестирования приложений осуществляется путем интеграции пакета Python с фреймворком Django. Python- и веб-разработчики, DevOps-инженеры для этого используют встроенные инструменты Django, пишут тест-кейсы под юнит-проверки и затем встраивают пакет в фреймворк.В библиотеке Featuretools фичи для ML-моделей разрабатываются автоматически: для этого из базы переменных выбирают те, которые станут основой обучающей матрицы. Данные во временном формате и из реляционных баз в процессе генерации становятся обучающими панелями.
Библиотеки, платформы и языки – элементы стека
В перечне фреймворков, улучшающих производительность ИИ-моделей, отмечаем библиотеку с открытым кодом TensorFlow и платформу TFX, ускоряющую развертывание готового проекта. Они заточены под изображения. Модуль PyTorch написан на нескольких языках, куда входят Python, базисная версия C++ и архитектура CUDA, придуманная под процессоры и видеокарты NVIDIA.При недостатке физических сред для хранения и развертывания информации применяют облачные решения SageMaker, Azure и Google. В число востребованных новых языков для генерации ИИ-приложения вошла Julia: при использовании команд, написанных на ней, больше 81 % команд выполняются быстро, четко и с минимумом ошибок. JavaScript и Python, R тоже показывают неплохие результаты с точностью 75+ %.
В стек для приложения добавляем среду JupyterLab, библиотеку NumPy для многомерных массивов или вариант попроще Pandas. Библиотека Dask предназначена для анализа больших баз данных с кластерами, визуализации и распараллеливания, интеграции со средами и системами, с целью снижения затрат на аппаратное обслуживание.
Особенности XGBoost, TensorFlow, FastAPI
XGBoost 2.0 работает по принципу многофакторной и квантильной регрессии, включая множество признаков в дерево операций. В новом функционале улучшено ранжирование и оптимизированы размеры гистограмм, стал понятнее интерфейс PySpark. Если сравнить MXNet и TensorFlow, то лучше выбрать последнюю платформу ввиду лучшей обучаемости, отладки и скорости загрузки данных.Асинхронность и быстрота операций FastAPI делает фреймворк предпочтительнее Django, на котором на серверах стандарт WSGI нужно конфигурировать к новому асинхронному ASGI. Ввиду того, что интерфейсу 6 лет, у него ограничен объем данных для JWT-токенов и хранилища S3. Принимаем во внимание, что асинхронные библиотеки часто имеют проблемы с нечитаемостью информации и иногда приходится делать записи, задействуя execute() после передачи SQL-запроса и материалов. Примечание: атрибут root_path не меняется на “/api”, что создает неудобства.
Контейнеризация, деплой и архитектура ИИ-модели
Когда компоненты для создания ИИ-приложения собраны вместе (код и библиотеки с фреймворками), запускают процесс контейнеризации. Автономный контейнер абстрагируется от хоста и без перекомпиляции переносится в другую среду. Docker Engine и Kubernetes – пионеры этого сегмента, востребованная ОС – Linux (облачная либо локальная), OCI работают в режиме чтения, без изменения. В этом списке VMware и LXC. Контейнеры иногда хранят на платформе GitHub: особенно когда идет совместная работа над проектом.Инструменты для деплоя включают проприентарную платформу Heroku, работающую по протоколу PaaS, более сложную Elastic Beanstalk и Qovery, взявшую лучшее у обоих ресурсов. Для тестирования используют:
- Selenium с тремя видами сервисов WebDriver, IDE и Grid;
- платформу PyTest с масштабируемыми тестами на версиях Python 3.8+ либо PyPy3;
- Locust с нагрузочными тестами.
| Архитектура модели | Назначение | Особенности |
| Сверточная (CNN) | Видео и изображения | Точная идентификация, устранение шумов и ошибок |
| Рекуррентная (RNN) | Цифровые данные и язык | Обработка последовательностей |
| Генеративно-состязательная (GAN) | Генерация новых данных и картинок | Имитация с генерацией новых данных, в качестве баз для обучения |
После этого идёт тонкая, филигранная настройка обучения ИИ-модели. Если в сценарий заложены высокие требования с точными параметрами, обучение продолжается с наблюдением – такие условия дороже. Чтобы найти артефакты и закономерности в кластеризации, предпочтительно сделать выбор самостоятельного обучения. Для проектов в робототехнике и простых игр в Телеграм или сложных приложениях на iOS/Android применяют подкрепление (поощрение или наказание – метод «кнута и пряника»).
Тайминг разработки, проверка на ошибки
Временные затраты на разработку, тестирование и запуск ИИ-модели выглядят примерно так, как на диаграмме. Алгоритм требует точного описания выполнения задач – таким образом, чтобы в результате вышло новое решение для обнаружения закономерностей. Цепочку «итерации – прогнозы – коррекция» завершают гиперпараметры, введенные вручную перед началом перекрестной проверки в подмножествах.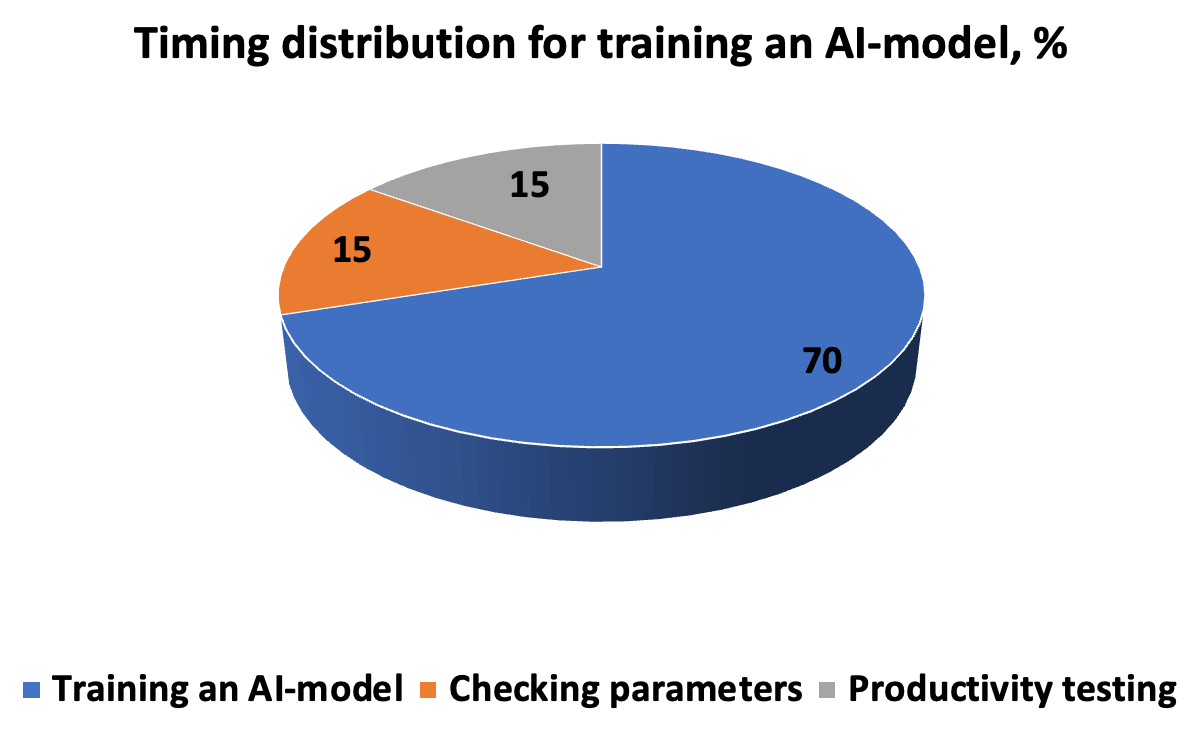
Чтобы в условиях реальных сценариев модель продуктивно работала, нужно оценить правильность и скорость ответа. Поэтому в параметры измерения включают прецизионность и повторяемость, метрики ROC-AUC, где нет необходимости отсечения порога (для несбалансированной базы данных), F-score, уточняющего долю положительных решений, среднеквадратичную ошибку MSE и коэффициент детерминации R-квадрат. Ошибку в пределах 5 % считают допустимой, при уменьшении до 1 и 0,1 % результат относят к высокоточным.
RAG и настройка, интеграция в бэкенд или фронтенд, тестирование
Метод RAG применяется для разработки генеративных моделей, когда векторы и семантика приближены друг к другу по сегментам, исходя из контекста и релевантности. Основа RAG – извлечение информации из объемных баз данных и последующая генерация в модели для получения точного ответа. В тонкую настройку для специализированных экспериментов входят нормализация (приведение к единым параметрам) и, после адаптации, токеинизация. Чтобы ИИ-модель продуктивно работала, интеграция проводится, в зависимости от задачи, в бэкенд или фронтенд. Языковую модель лучше встроить в серверную часть, для работы с клиентами – в интерфейс.В IoT предпочтительнее периферическая работа на устройстве, так как сохраняет конфиденциальность и обеспечивает быстродействие. На базе IoT происходит генерация данных, суть которой в конвергенции ИИ с IoT. Такая синергия наращивает функциональность двух частей, рождая AIoT. Но для усиления мощности и масштабируемости функционала лучше применять облачные технологии, используя встроенные API-протоколы. Если важно услышать отклик клиентов (удобство, понятность, скорость), встраиваем функцию обратной связи.
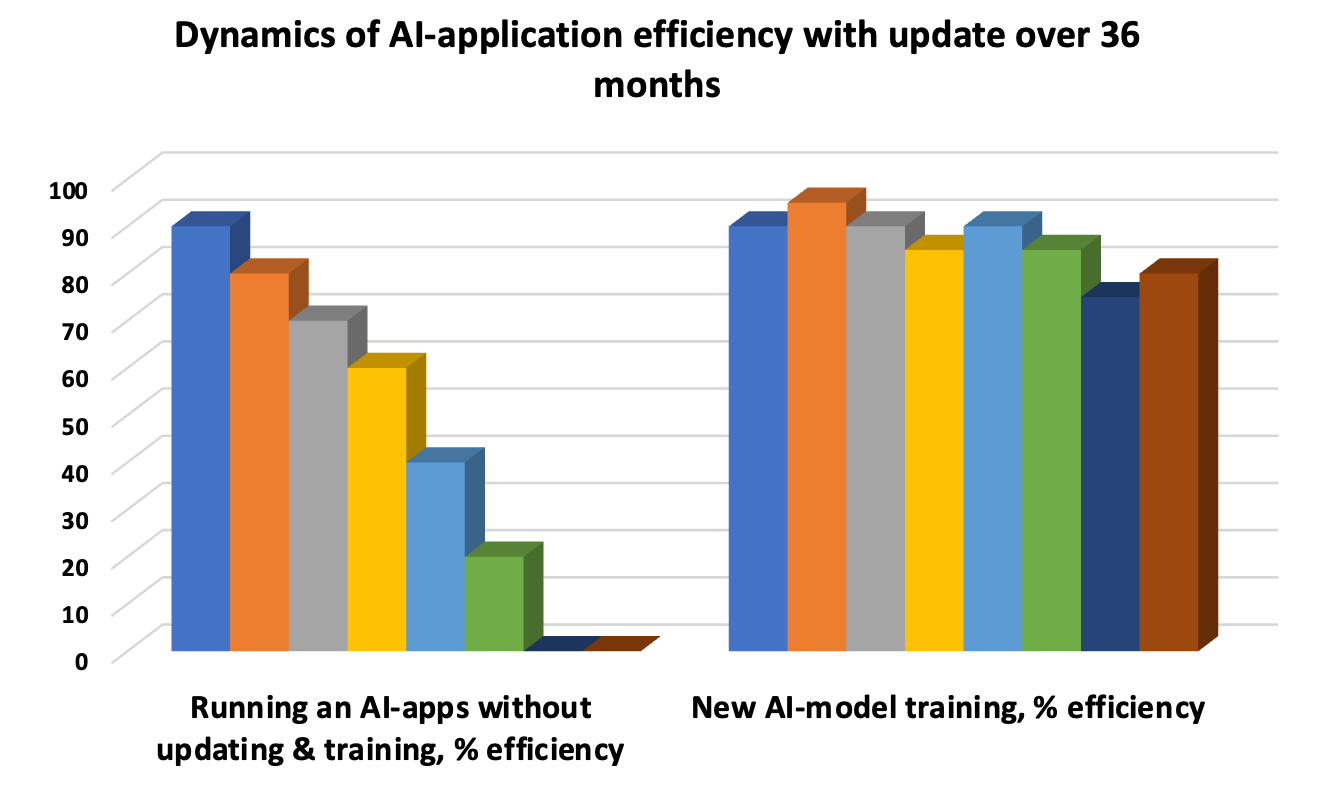
Обновление ИИ-модели – необходимость ввиду избежания «дрейфа», когда базовые шаблоны устаревают и точность ответа снижается. Поэтому тестирование с итерациями продлевают жизненный цикл модели. Автоматизированное модульное тестирование, периодическое интеграционное для оценки совокупности работы отдельных функций и приемочное UAT – три обязательных «кита» оценки работы и тестов.
ZBrain – открытый код и бесшовная интеграция
Примером проработанной платформы для симбиоза корпоративных процессов и информации со встраиванием ИИ-функционала является ZBrain. Открытый код с шаблонами и памятью, интегрированными LLM, обеспечивают:- хранение и обмен фиата и криптовалюты в парах, с регистрацией операций по принципу блокчейн;
- продуктивную работу на понятной и подробной инфопанели;
- управление мультиплатформенными и кроссплатформенными приложениями на микро-и макроэтапах;
- внедрение когнитивных технологий и проектно-ориентированных решений.
Это наглядная демократизация и упрощение трансформации бизнес-процессов, когда сами пользователи без написания кода разрабатывают и развертывают ИИ-модели применительно к логике и рабочим процессам маркетинга и производства. Так, бесшовная интеграция Flow динамически выбирает нужные данные и на их основе готовит ИИ-решения.
Квантовые вычисления: уйти от узких мест Неймана и снизить энергозатраты
Для обработки больших массивов данных применяют квантовые вычисления. Алгоритмы, используемые в квантовых технологиях, ускоряют процессы ИИ-обучения в отрасли медицины, материалов, биологических и химических процессов, уменьшают выбросы СО2 и парниковых газов. Чтобы задействовать обучение на миллиардах параметров, нужны сверхмощные графические процессоры либо TPU, заточенные под проведение нескольких параллельных операций.Одновременно нужно преодолеть проблемы узких мест Неймана (VNB), чтобы процессор не ждал, когда оперативная память (ОЗУ) обеспечит доступ к процессу. Задача – увеличить скорость получения и передачи данных из базы либо хранилища. Даже высокая скорость многоядерных процессоров при объеме ОЗУ в 32–64 Гб и больше может не оправдать вложения в мощности при ограничении передачи информации из «облака». Для решения проблемы VNB расширяют кэш, вводят многопоточную обработку, изменяют конфигурацию шины, дополняют ПК дискретными переменными, используют мемристоры и вычисляют в оптической среде. Есть также моделирование по принципу биологических процессов, таких, как квантование.
Цифровая парадигма ИИ при параллельной обработке увеличивает энергозатраты и время процессов обучения. Поэтому кубиты в суперпозициях (несколько положений в один период времени) и положении запутанности предпочтительнее классических битов при условии сохранения стабильности. Для ИИ квантовые технологии лучше ввиду снижения стоимости разработки и анализа данных в нескольких конфигурациях. «Тензоризация» сжимает ИИ-модели и обеспечивает развертывание на простых устройствах при улучшении качества исходных данных.
Правила киберзащиты
Уделяйте внимание киберзащите – ИИ-алгоритмы выявляют закономерности в несущих угрозу действиях, прогнозируют возможные киберугрозы, защищают конфиденциальность, что является императивом в юридической сфере и этике. Правила GDPR и CCPA, как и другие протоколы защиты, должны поддерживаться путем гарантирования:- анонимности клиентов и отсутствия лазеек их идентификации сторонними лицами;
- дифференциации недопустимых для разглашения конфиденциальных моментов в паспортных данных, электронной почте, номерах телефонов и других документах;
- совместного анализа сегментов информации в двух-трех разъединенных системах, без раскрытия полной базы.
Отравление моделей (внедрение вредоносных элементов) в ИИ, наличие состязательных уязвимостей приводят к ошибочной классификации. Поэтому целостный подход должен включать принципы защиты, начиная со стадии разработки до тестирования и развертывания, чтобы минимизировать вызовы и риски.
Работа ИИ: экспертная и НЛП, по генетическим алгоритмам и творческая
Выявлены ключевые особенности обучения ИИ в случае, когда поставлена цель решать задачи на уровне эксперта, ориентируясь на рассуждения и анализ многомиллионной эмпирической базы данных с наглядным рассмотрением конкретных ситуаций. Например, по вегетационному индексу NDVI определяют уровень роста растительности. Но есть нюансы – одно дело, когда вегетация идет зерновых или масличных культур, другое – сорняков. ИИ в приложении должен суметь различить по цвету, что лучше растет и дать ответ. Аналогично – распознать тип лица, линейные параметры фигуры для рекомендаций по выбору косметики или одежды для аутфитов.При планировании работы ИИ в качестве психолога в алгоритмы внедряют принцип НЛП – происходит анализ естественной речи, уточнение психоэмоционального настроения пациента. Тогда на вопросы поступает сгенерированный ответ, приближенный к человеческому звучанию и интонациям. Есть еще генетические алгоритмы, когда для решения миллионов задач создают ботов и затем отсекают худших, оставляя лучших. Совмещение удачных разработок и последующая генерация новых приспособленных и апробированных моделей, на базе предшественников и ряда итераций, приводит к полноценному решению задачи.
Подход к разработке ИИ-приложения должен быть творческим. Допустим, сделать чат-бот в виде весёлого животного или птицы, смешного эльфа либо одухотворенного растения или прагматические вещи типа торгового бота. Те, кто читал Курта Воннегута, помнят рассказ о суперкомпьютере, получившем человеческое мышление. Поэтому, если персонаж будет озвучивать реплики, используя предыдущее общение, давать подсказки и коротко пресс-релизить о новинках, клиенты полюбят и привыкнут к ИИ, будут доверять. Рост продаж составит не менее 10–20 %.
MVP, CRISP-DM и расценки
Первый шаг после разработки ИИ в приложение – запуск MVP с анализом и поддержкой, улучшением функционала и перманентным тестированием. Если в планах компании – поддержание ИИ-приложения на протяжении 10–20 лет, то необходимо регулярное ежеквартальное обновление баз данных, тестирование по разным типам, согласно методологии CRISP-DM.Чтобы определить финансовые расходы и временные затраты, обратитесь в Merehead с задачей и вопросами: стоимость разработки искусственного интеллекта начинается с $20.000 и занимает по срокам до квартала. Время разработки приложений средней сложности с логическими цепочками на трех-пяти уровнях вдвое больше и цена достигает $100.000. Для сложных математических проектов, с экспертным анализом и точностью ответов 99,9 % – до $500.000. Перед началом работы разработаем дорожную карту проекта и спланируем ожидаемые результаты рентабельности.


