
Era sztucznej inteligencji narodziła się dawno temu. Ludzie przyzwyczaili się do błyskawicznej identyfikacji i rejestracji, szybszego wyszukiwania transportu i tras, wygodnego wyboru towarów i korzystania z usług AI. AI stała się niezawodnym asystentem biznesu, zastąpiła pracowników i zredukowała do zera prawdopodobieństwo błędów spowodowanych czynnikiem ludzkim. Rutynowe prace zostały zdegradowane do kategorii prac zlecanych AI, a zadaniami kreatywnymi zajmują się czołowi specjaliści.
Aplikacje i sieci neuronowe, algorytmy działania AI
Każda z firm IT opracowuje modele i algorytmy, aplikacje i chatboty oparte na sztucznej inteligencji, wykorzystujące uczenie maszynowe i głębokie uczenie się do analizy danych cyfrowych. W przypadku wymagających projektów podłączane są sieci neuronowe w biznesie. Wizualizacja za pomocą AI to rozpoznawanie i wizja komputerowa 3D.Obiecujące aplikacje bankowe często opierają się na pracy inteligentnego asystenta AI. Co więcej, możliwe jest stworzenie aplikacje AI, która pomoże w obrocie papierami wartościowymi lub akcjami . Wstępna selekcja ramek według konkretnych wskaźników, wstępna diagnoza pacjentów, ustalanie działań zabezpieczających po uruchomieniu określonego wyzwalacza to także efekty myślenia AI. O generowaniu tekstów, obrazów i treści wideo średniego szczebla krążyły plotki od kilku lat.
Analizowanie obrazów quadkoptera FPV to wygodny sposób oceny terenu w czasie rzeczywistym. Można go skonfigurować tak, aby był wysyłany bezpośrednio do centrum danych w celu przyspieszenia podejmowania decyzji wspomaganych sztuczną inteligencją w podstawowych sytuacjach. Automatyzacja procesów to jedna z kolejnych korzyści wdrożenia AI.
Rozpoznawanie i weryfikacja, diagnoza i rokowanie za pomocą AI
Przykłady wykorzystania sztucznej inteligencji w działalności biznesowej biur podróży obejmują rozpoznawanie paszportów, ubezpieczeń i dokumentów podróżnych. Wprowadzenie tych danych do formularzy wniosków lub umów jest łatwe przy minimalnym poziomie błędów, sięgającym 1–5%. Rozpoznawanie sieci neuronowej jest trenowane poprzez analizę zdjęć i tekstu w przestrzeni, z adaptacją i weryfikacją, tworząc odpowiedź API. Samo oprogramowanie, stworzone przy użyciu technologii RPA, można zintegrować z dowolnym CRM-em lub chatbotem, szafką użytkownika.Robot RPA kompletuje rutynową dokumentację, generuje raporty i wykonuje operacje w celu ustalenia godzin pracy. Szkolenia realizowane są z wykorzystaniem uczenia maszynowego ML. Tworzenie i uczenie sieci neuronowych, o architekturze splotowej lub generatywnej, jest jedną z często stosowanych technik uczenia maszynowego. Sieci neuronowe mają zdolność przewidywania transakcji giełdowych i udzielania porad zakupowych na rynku tokenizacji nieruchomości. Za ich pomocą naukowcy dokonują przewidywań dotyczących cech jakościowych leków na podstawie składników, oceniają stan projektowanego obiektu lub stopu.
Modelowanie decyzji z wykorzystaniem nauki o danych
Budowanie baz danych i pokazywanie ich AI nie wystarczy: trzeba ją nauczyć rozpoznawać sytuacje, w których trzeba szybko udzielić jasnej odpowiedzi. Są to sytuacje, w których relacyjne bazy danych nie mogą znaleźć odpowiedniego rozwiązania. Takimi zagadnieniami zajmują się analitycy Data Science. Odpowiadają za określenie algorytmów i warunków modelu matematycznego, w ramach którego jest on realizowany:- modelowanie procesów;
- segmentacja i personalizacja klientów, kluczowe żądania;
- trafność ofert.
Aby zwizualizować ten proces, załóżmy, że osoba jedzie samochodem. Odbył telefon, który wywołał przypływ endorfin. W rezultacie jego tętno wzrosło, ale jego zdolność koncentracji uległa zmniejszeniu i pojawiła się chęć „szybkiej jazdy”. Tracker na Twoim ramieniu wykrywa to i przesyła informacje do systemu AI samochodu. Sztuczna inteligencja ostrzega – zaleca zmniejszenie prędkości (lub sama to robi), zmniejsza nagrzewanie się kabiny i otwiera okno.
Wyzwanie dla sztucznej inteligencji
Sztuczna inteligencja po prostu nie jest ludzkim sposobem myślenia. Komputery realizują to, czego wymaga od nich programista – obliczają, obliczają, wykonują określone czynności. Możesz ustawić zadanie głosowo lub tekstowo, ale wcześniej wprowadzasz reguły i ograniczenia, zależności, w tym statystyczne. Algorytmy transformacji to schematy wzór po wzorze: „Opis” - „Reguły” lub „Zadanie” - „Rozwiązania”. Prognozowanie sprawdza się, jeśli przedstawionych zostanie kilka sytuacji z przykładami.Rozważ następujące zadanie: „Napisz program w Pythonie, który będzie generował zyski rynkowe. Kapitał początkowy 100 tys. dolarów, oczekiwany zysk 10% inwestycji, ilość towarów na rynku 10000, średnia cena jednego produktu 50 dolarów, prowizja 3 %”.
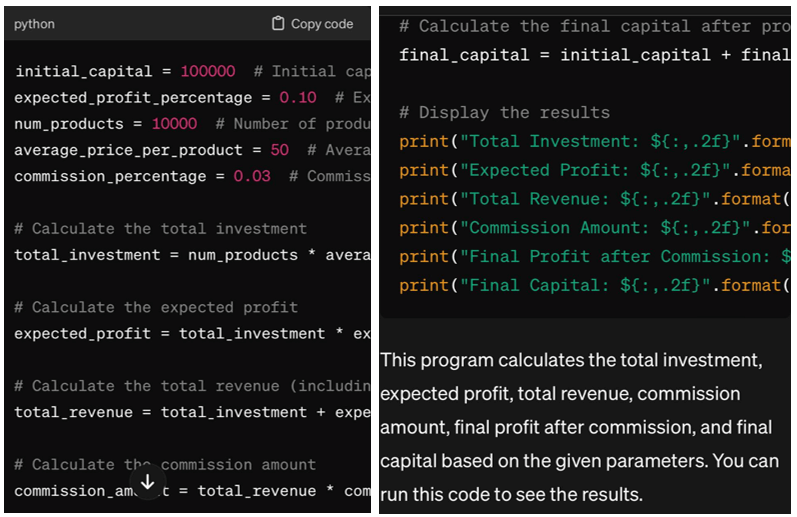
Rezultatem będzie powyższa odpowiedź, która jest ograniczona ze względu na wprowadzenie niewielkiej liczby wskaźników do warunków problemowych. Im bardziej szczegółowe są czynniki i im większy rozmiar zbioru danych, tym mniejszy błąd w ostatecznym rozwiązaniu. Ucząc sztuczną inteligencję programista wprowadza początkowe informacje i taguje każdy fragment. Po zgromadzeniu bazy danych ze znacznikami kontrolnymi uczenie przechodzi do etapu wyszukiwania reguł i weryfikacji w predykcji.
Scenariusze i błędy modelowania krokowego
Każdy etap polega na odnalezieniu zadanego wzorca i poszukiwaniu nowego o określonym parametrze. Na przykład, jeśli przyjechał samochód Mersedes, następnie Audi i Honda, następnym może być BMW lub Mitsubishi. Jeśli nie ma potrzeby wyszukiwania wzorców, wówczas wyłączamy tę funkcję i korzystamy z rozwiązań z poprzednich kroków.Scenariusz, w którym po pierwszym znaczniku następuje pytanie, a po kolejnym znaczniku następuje odpowiedź, sprawia, że algorytm jest wygodny, ponieważ odpowie na każde pytanie w granicach bazy informacji. Oczywiste jest, że w każdym algorytmie przewidywania występuje błąd.
Dopuszczalne jest, jeśli marginesy błędu mieszczą się w granicach 5%. Model stochastyczny jest odpowiedni, gdy nie ma pewności co do zakresu wprowadzanych danych wejściowych lub wyjściowych. Funkcja lokalna z mapowaniem jednowartościowym opiera się na identyfikatorach obiektów. Funkcje proste są jednoparametrowe, obliczenia w nich przeprowadza się za pomocą współczynników, a nie za pomocą stwierdzeń, jest to fałsz lub prawda.
Algorytmy analizy, wyniki i funkcje
Każdy algorytm jest podzielony na kroki: warunki i przejścia, z których każdy kończy się operatorem wyniku, ale nie zwrotem. Porównanie ze stałą, czyli pewnym punktem lub krokiem algorytmu, jest podstawą ciągłej predykcji. Można to porównać do wyszukiwania korelacji, gdy dane o skorelowanych cechach są gromadzone i łączone w grupy. Następnie na podstawie uzyskanej podstawy wybierany jest stan ogólny oraz odległość między danym parametrem a wynikiem obliczeń. To wygląda tak:- tworzenie funkcji z jednym parametrem;
- wybór części o tych samych warunkach;
- utworzenie nowej funkcji dwuparametrowej;
- udoskonalenie liniowości w bazach wieloparametrowych.
Konwersja polega na algorytmach znajdowania rozwiązań, a następnie tworzeniu reguł na podstawie odpowiedzi. Czasami rezultatem jest rekurencja z kilkoma poziomami lub fraktal. Tokeny kontrolne odpowiadają na zapytania i generują końcowe obliczenia, biorąc pod uwagę szybkość, przyspieszenie i błąd procesu. Niemniej jednak algorytmy opierają się na statystykach.
Samodzielność i autonomia: analiza równowagi i decyzje
Nietypowe jest, aby komputer szukał rozwiązania lub prowadził badania bez zadania. Nawet jeśli warunkowo zaprogramowano ludzką osobowość, bez zadania komputer nie wykona określonych czynności. Logika formalna tu nie działa, potrzebna jest matematyka i statystyka. Decyzje podejmowane przez AI muszą być analizowane autonomicznie: jeśli wykraczają poza granice algorytmów i skryptów, ale stanowią preferowaną opcję, to jest to potwierdzenie słuszności decyzji o „autonomii”.Zasady sztucznej inteligencji:
- analiza predykcyjna polegająca na znajdowaniu wzorców i trendów jest stosowana do prognozowania w oparciu o wzorce i prawdopodobieństwo zdarzeń;
- multimodalność oznacza jednoczesne przetwarzanie informacji z kilku źródeł i typów danych;
- Metoda multidyscyplinarna przypomina metodę naukową, ponieważ łączy kilka nauk i ich gałęzi w celu poprawy wydajności sztucznej inteligencji.
Maksymalny poziom analizy jest w ASI, co przypomina ludzkie myślenie. Inteligencja AGI jest bliska przeciętnemu poziomowi ludzkiego myślenia. ANI jest typowym wykonawcą, który nie wykracza poza zadania zapisane w programie.
Trening z liczbami, rozpoznawaniem i niekompletnymi informacjami
Gromadzenie ogromnej ilości danych wymaga szkolenia w zakresie sztucznej inteligencji. Do formatu maszynowego wykorzystuje się regresję liniową i wielowymiarową, wektory wsparcia, drzewo decyzyjne z podkategoriami i sąsiadów KNN. Uczenie się przez wzmacnianie obejmuje algorytmy dla robotów. Komunikacja Chatbota jest wynikiem wykorzystania Transformersów po przetworzeniu ludzkiego języka.Zadaniem NLP jest rozpoznawanie tekstu i dźwięku, tłumaczenie i generowanie treści. 6 lat temu programiści Facebooka opracowali bota bazującego na danych Amazona (6 tys. prawdziwych dialogów), który niczym nie różnił się od człowieka, potrafił targować się, a nawet oszukiwać. Pokazuje to, że zadania AI w programach marketingowych i rozrywce są różnorodne:
- w handlu detalicznym przemyślają algorytmy opracowywania promocji i ofert zakupu;
- w branży restauracyjnej tworzą wnętrza i autorskie menu;
- w branży gier po dogłębnym szkoleniu rozwijają idealny umysł składający się z menedżera AI i programów agentów „architektury hybrydowej”.
Patrząc na przykład aplikacji Libratus, jasne jest, że sztuczna inteligencja składa się z kilku części. Część centralna analityczna współdziała z częścią drugą, która monitoruje błędy przeciwników oraz częścią trzecią, która analizuje błędy we własnych działaniach. Jest to przykład wykorzystania niekompletnych informacji w celu zapewnienia pełnej, kompleksowej odpowiedzi w branżach cyberbezpieczeństwa, wojskowości i negocjacji.
Szablony z poprawnymi rozwiązaniami i obsługą ChatGPT-3.5
12 lat temu ekonomiści Shepley i Roth otrzymali Nagrodę Nobla za teorię stabilnej dystrybucji. Rozwiązania matematyków znalazły swoje potwierdzenie w informatyce: techniki dystrybucji unimodalnej i bimodalnej sprawdzają się, jeśli rekrutuje się wielomiliardową bazę danych, a następnie analizuje ją w postaci histogramów. Programiści w laboratoriach OpenAI i Google, Microsoft na bieżąco monitorują szkolenie AI, odcinając błędne rozwiązania i tworząc szablony w oparciu o te prawidłowe. Na świecie zarejestrowanych jest 60 tysięcy firm IT zajmujących się tworzeniem oprogramowania opartego na sztucznej inteligencji.
ChatGPT w wersji 3 korzystało tylko ze 175 miliardów źródeł. Wersja 5, która ma zostać wydana do końca 2024 r., będzie jednocześnie generować treści tekstowe i audiowizualne. Liczba źródeł rozwoju jest 100 razy większa niż ilość danych, jakie posiada ChatGPT-3. Zaawansowana i wydajna wersja będzie analizować dane, działać jako podstawa dla chatbotów, generować kod i wykonywać inne funkcje wirtualnego asystenta. Póki co model 3.5 działa tak i jest podatny na błędy.
Produkty AI Google i Microsoft
Sprawdzone aplikacje AI obejmują DALL-E, który generuje i edytuje obrazy oraz tworzy kolaże. Whisper – uniwersalny transkryptor AI, który rozpoznaje mowę i tłumaczy. CLIP - analogizator obrazu i zdjęć. Gym Library i Codex – platformy dla programistów oparte na sztucznej inteligencji. Na liście Google znajduje się 15 podobnych aplikacji i platform AI. To prawda, że \u200b\u200bw ich pracy często występują błędy i błędy.Algorytmy AI są wykorzystywane w Zdjęciach Google i Youtube, tłumaczu do ulepszania funkcji i analizowania danych. Chatbot Google Bard jest analogiczny do ChatGPT, ale ma własny język PaLM 2. Można tego używać jednocześnie z Gemini, który ma wysoki poziom generowania i analizy. Imagen AI generuje obrazy, Generative AI jest testerem generatywnych modeli uczenia się. Vertex AI pomaga naukowcom przetwarzać dane, Dialogflow służy do tworzenia chatbotów.
Platformy sztucznej inteligencji firmy Microsoft obejmują uniwersalną encyklopedię Copilot, usługę programistyczną Azure Space, która generuje obrazy, obrazy i logo oraz szkice Image Creator.
Wielka Brytania i Tajwan Foxconn wykorzystują sztuczną inteligencję
W brytyjskim katastrze HMLR, w którym rejestrowane są tytuły gruntów i nieruchomości, połowa pracy jest wykonywana przez sztuczną inteligencję. Śledzeniem wydajności oprogramowania i aplikacji zajmuje się APM, dlatego Atlassian korzysta z narzędzi platformy opartych na sztucznej inteligencji do monitorowania procesów i sprawdzania, czy nie występują błędy. Dlatego też sztuczną inteligencję często wykorzystuje się do konserwacji zapobiegawczej najważniejszych systemów, oceny stanu technicznego pod kątem zapobiegania przestojom i wypadkom.Prognozowanie biznesowe projektu lub konkretnej operacji biznesowej poprawia dokładność i oszczędza budżet. Przykładowo Foxconn, tajwański producent komponentów do smartfonów i produktów Apple, oszczędza w meksykańskiej fabryce ponad pół miliona dolarów dzięki rozwojowi sztucznej inteligencji opartej na Amazon Forecast.
Głębokie uczenie się i szkoły dla sztucznej inteligencji
Programiści i programiści szkolą sztuczne neurony (węzły) w celu rozwiązywania problemów za pomocą metod głębokiego uczenia się. Obejmuje to algorytm NLP do przetwarzania języka, znaczenia i tonu oraz generatywną sztuczną inteligencję, której zawartość audio, wideo i tekstowa oraz artefakty są podobne do ludzkich. Surowe dane – zasoby z podwarstwami – reprezentują infrastrukturę operacyjną, na której odbywa się nauka. Można je przechowywać zarówno na zasobach fizycznych, jak i w chmurze.Swego rodzaju „szkoły” AI – platformy takie jak TensorFlow czy PyTorch. Dostępna jest biblioteka open source Scikit-learn napisana w Pythonie. Na potrzeby szkolenia tworzone są funkcje i tworzone są zajęcia zgodnie z planem architektury aplikacji AI. Na poziomie modelowania wyznaczana jest moc, następnie segmentacja według poziomów i funkcjonalność aktywacji.
Twórcy analizują, jak neurony zmieniają wagę swoich sąsiadów podczas komunikacji i szacują węzły przemieszczenia. Dane przewidywane i rzeczywiste nie powinny zbytnio się od siebie różnić – w tym celu stosuje się porównanie za pomocą funkcji straty. W tym procesie pomagają optymalizatory, takie jak opadanie gradientu lub adaptacyjne sekwencje gradientów, uwzględniające minima i maksima oraz szybkość zmian. Sztuczna inteligencja w formacie aplikacji służy klientowi, a nie pracownikowi.
Generowanie zbioru danych, wykorzystanie procesora graficznego i modelu podstawowego
Uniwersalność modelu GPT uwarunkowana jest poprawnością podejścia do uczenia promtomowego, dostosowaniem do konkretnych pytań, pracą ze zbiorem danych oraz mocą obliczeniową. W firmie zajmującej się szkoleniem modeli AI pracuje sto, dwa i więcej procesorów graficznych. Odpowiadają za obliczanie i przetwarzanie informacji graficznych, szkolenie modeli nawet do 10-30 dni, w zależności od stopnia złożoności. Im więcej parametrów w zbiorze danych, tym wyższa cena.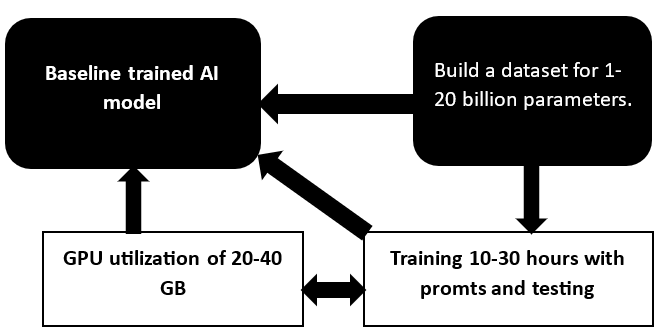
Uproszczone modele Open Source działają. Mimo że próg wejścia jest niski, w benchmarkach osiągają wysokie wyniki. Cena szkolenia prostych aplikacji z bazą z kompleksu GPT-4 z Google Bard lub LLaMA z Evol-Instruct zaczyna się od 500-1000 dolarów. Każda baza w tych wersjach jest łatwa do sfinalizowania i uzyskania spersonalizowanej aplikacji autorskiej, która jest lepsza niż płatna.
Klienci powinni mieć świadomość, że pojemność pamięci do tworzenia uproszczonych aplikacji AI jest stosunkowo niewielka i wymagane są procesory graficzne o pojemności 40-80 GB. Systemy generatywne AI powstają także w oparciu o technologie chmurowe w oparciu o odpowiednie usługi i zbiór danych. Pipeline dobrze sprawdza się w chmurze, zaczynając od przetwarzania zbioru danych, zbierania informacji i analizowania danych. Często odpowiedni model jest już ustalony, dlatego wymagane jest przeszkolenie i dostrojenie niektórych parametrów za pomocą adapterów. Aby przedstawić ilość informacji, należy pamiętać o ogólnej zasadzie: 10–15 miliardów parametrów mieści się w procesorze graficznym o pojemności 16–24 lub 40 GB.
Model LLM z metodą PEFT, scenariusz uproszczony
Jeśli jako podstawę wykorzystasz przeszkolony model LLM, metoda PEFT rozszerzy pożądany podzbiór parametrów, ale pozostawi te, które nie są potrzebne, w stanie „zamrożonym”. Analitycy firmy dowiadują się w briefie, jakie parametry interesują klienta i szkolą się na ich podstawie. Okazuje się, że jest to szkolenie częściowe, którego wynik nie jest gorszy od pełnego szkolenia. Dlatego w procesie konsultacji z klientem informatycy od razu określają, czy muszą wygenerować zestaw rozwiązań wraz z instrukcjami i warunkami, czy też samodzielnie stworzyć programy szkoleniowe z parami pytań i odpowiedzi.Scenariusz szkolenia w chmurze standardowej obejmuje skalowalne zasoby w chmurze, zarządzanie dostawcami usług w chmurze i wykorzystanie gotowych usług jako narzędzi szkoleniowych. Protokół rozwoju ML ze scenariuszami generowania i przetwarzania danych źródłowych, eksperymentami z wersjonowaniem, wdrażaniem i osadzaniem modeli, dalszymi aktualizacjami działa bez ręcznego dostosowywania. Oto przykład kompletnego rozwiązania dla platformy - połączenie JupyterHub do eksperymentów, MLflow do wdrażania i interakcji Data Science i zadań, MLflow Deploy do pakowania i wdrażania.
Ten model wytrenowany za pomocą GPT odpowiada na pytania, dla których informacje są wprowadzane do zbioru danych. Takie odpowiedzi mogą być krótkie lub długie, z konkretnymi rozwiązaniami i przykładami. Wyszkoleni modele piszą funkcje i kody programów w JavaScript i Pythonie, wyciągają informacje z tekstu, bazy danych lub dokumentacji w przypadku zadawanych pytań.
Dodatkowo sztuczna inteligencja umożliwia analizę otwartych danych i wydawanie rekomendacji dotyczących inwestycji w memecoiny, które są obecnie wykorzystywane do szybkiego zarobku.
Rewolucja multimodalna i modelowanie immersyjne
Posiadanie modeli AI z dostępnymi informacjami podstawowymi upraszcza pracę związaną ze szkoleniem i wdrażaniem wielu lub dziesiątek jednostek w ramach pętli usług. Ważne jest, aby dane zestawu danych zostały sprawdzone: dokładność i ważność określają agregat i integralność kompleksu. Oczekuje się, że już w 2024 r. paradygmat multimodalności wyprzedzi sztuczną inteligencję i połączy wszystkie rodzaje informacji w jedną całość. Doświadczeni programiści zdają sobie z tego sprawę i często oferują łączone rozwiązania, w których analizuje się, przetwarza i interpretuje kilka kategorii danych.Sztuczna inteligencja zaczyna pełnić funkcję szkolenia AR/VR w oparciu o zasadę immersyjnej symulacji. Realistyczne scenariusze szkoleń praktycznych zapewniają praktyczne doświadczenie w bezpiecznym środowisku. Dlatego dla uniwersytetów i szkół wyższych wirtualne szkolenia są krokiem w kierunku zdobywania przez studentów umiejętności w trakcie studiów. Ponadto dodatkową wygodą jest korzystanie z technik personalizacji Netflix i TikTok, biorąc pod uwagę zainteresowania i wartość materiałów edukacyjnych oraz postępy uczniów.
Przyspieszający rozwój sfery AI pokazuje, że przyjazne dla użytkownika i szybko uczące się chatboty z aplikacjami do generowania treści wideo, zdjęć i tekstów, rozpoznawania danych, generowania raportów i dokumentacji, wyszukiwania rozwiązań oraz sprawdzania funkcjonowania obiektów czy systemów, geometrycznie rosną. Aplikacje AI przejmują proste i złożone funkcje człowieka. Głównym zadaniem jest odpowiednie skomponowanie algorytmu uczącego, utworzenie zbioru danych i napisanie promtów, a także przeprowadzenie testów post-learningowych.
Programiści i programiści firmy biegle posługują się tymi technikami. Skieruj zadanie w formularzu zgłoszeniowym.


