
Nie omawiając wszystkich niuansów związanych z planowaniem, tworzeniem i testowaniem aplikacji AI, uważamy, że zarówno doświadczeni programiści, jak i początkujący znajdą przydatne pozycje w długich instrukcjach i przykładach. Wachlarz technologii aplikacyjnych opartych na wykorzystaniu sieci neuronowych jest ogromny: od uproszczonego bota informującego po aplikację wyposażoną w funkcjonalność planowania wolumenu operacji handlowych, dostaw, kalkulacji i prognozowania zysków, kontroli pracowników i interakcji z klientami. Do udanych przykładów wdrożeń sztucznej inteligencji, które rozpoczęły się przy minimalnych nakładach inwestycyjnych, należą Grammarly i Duolingo, usługi Waze i Canva oraz edytor zdjęć FaceApp.
Przegląd obszarów zastosowań AI
Funkcjonowanie AI odbywa się w prokrustowym łożu kilku zasad i kategorii, do których należą:- posiadanie wydajnych procesorów graficznych, tysięcy gigabajtów danych i pamięci RAM z wielu węzłów połączonych w sieć w celu uczenia modelu;
- osadzanie Internetu rzeczy i algorytmów łączenia informacji z wielu warstw w modele sztucznej inteligencji;
- przewidywanie zdarzeń, zrozumienie sytuacji paradoksalnych i koordynowanie systemów o wysokiej precyzji;
- wdrażanie interfejsów API do generowania nowych protokołów i wzorców interakcji.
Typowe uczenie maszynowe ML zastępuje operatora na początku komunikacji z centrum wsparcia, wyjaśniając podstawowe pytania. Kiedy VCA angażują się w głęboki format, żądania są personalizowane, a bezpieczeństwo kontaktu wzrasta dzięki rozpoznawaniu mowy i stanowi psychologicznemu klientów. Automatyzacja bieżących zadań, takich jak wyszukiwanie biletów, zamawianie towarów, wybieranie punktów orientacyjnych, wpisuje się w funkcje wirtualnych operatorów. Z tego powodu wybór ML lub VCA zależy od kwestii do rozwiązania.
Logistyka, ocena klientów i rekrutacja
Skoordynowany przez sztuczną inteligencję łańcuch dostaw i logistyka upraszczają działalność, pokazując dostępność towarów w magazynie, wskazując rezerwy, prognozując wydajność i okresy zwrotu. Jest to dzieło zaawansowanych aplikacji i usług AI, których ceny zaczynają się od 100 000 dolarów. Audyt pozycji przychodów i kosztów, identyfikacja trendów w segmentacji zysków to przykład zastosowania AI w branży finansowej. Aplikacja działa w podobny sposób, personalizując każdego klienta i analizując efektywność sprzedaży: strategie promocji w mediach poprawiają pozycje marketingowe.Możliwości NLP AI umożliwiają wstępne wyszukiwanie pracowników i identyfikację ich umiejętności zawodowych. W tym procesie AI HR zaleca zmiany w opisach stanowisk pracowników, jeśli zauważy postępującą asymilację umiejętności i automatyzację, co sprzyja rozwojowi kariery.
Fundacja: właściwe zadania i dokładne dane
Pierwsze dwie fazy planowania działań organizacyjnych i technologicznych w celu opracowania aplikacji AI to zasadniczo rozsądny program składający się z kilku etapów. Diagram wyraźnie pokazuje, że pierwsza część obejmuje sformułowanie problemu, wybór narzędzi, wymagane zasoby, oczekiwane koszty i zyski. Drugi etap odpowiada za utworzenie zweryfikowanych i dokładnych baz danych gotowych do uczenia modeli.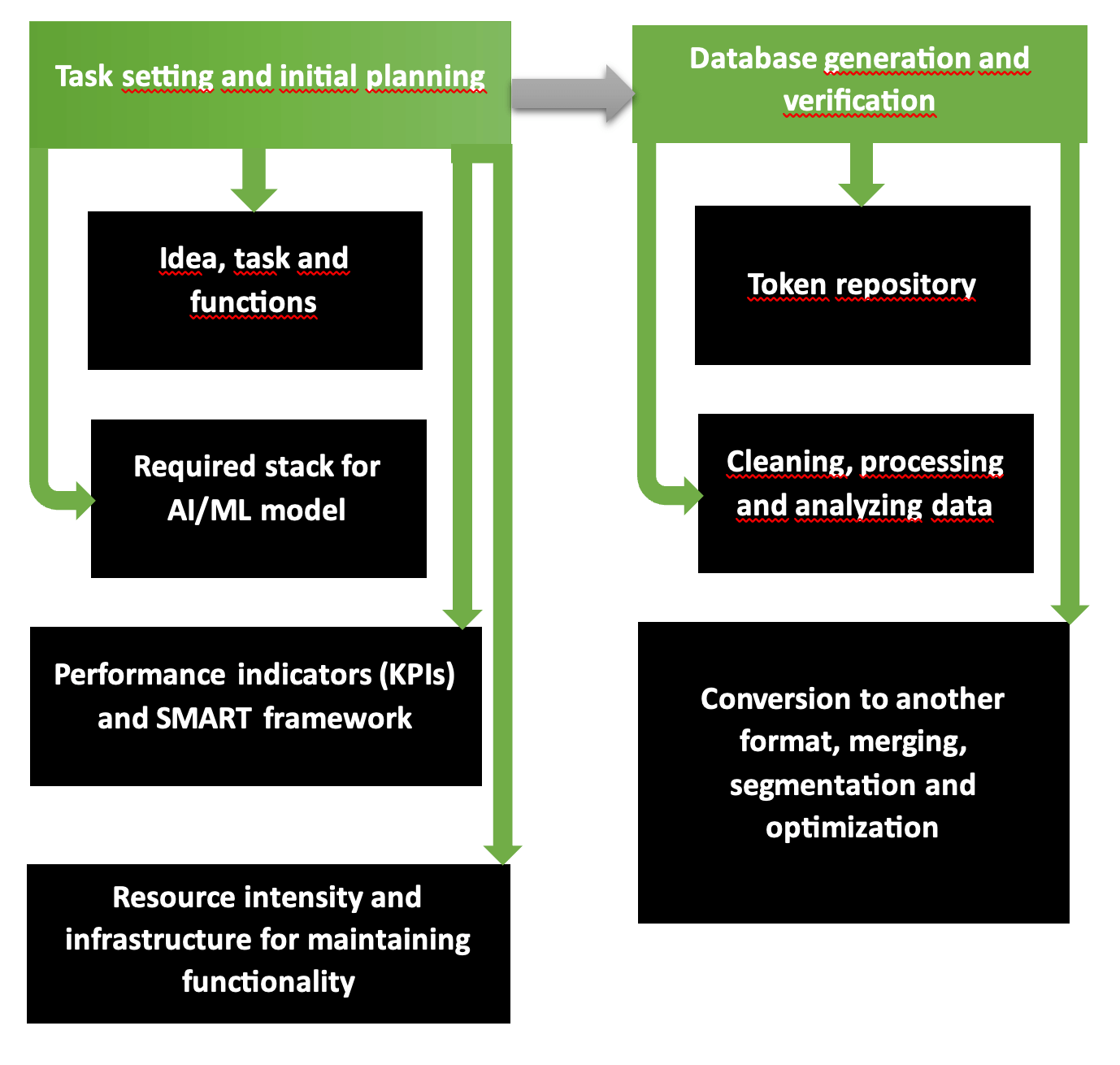
Tak zaczyna działać firma zajmująca się rozwojem AI aplikacji wieloplatformowych. Łańcuch „wymagania – cele – zgodność wizji – ujednolicony styl” jest przemyślany zgodnie ze strukturą SMART i kategoryzowany krok po kroku w Scrumie lub Agile. Cele i dostępność zasobów określają, jaki zakres usług i towarów można świadczyć w sposób planowy, a w przypadku niedoboru lub obfitości środków można go zmniejszyć lub rozszerzyć.
Common Crawl, platformy takie jak Kaggle czy AWS udostępniają bazy danych, które zostały sprawdzone pod kątem dokładności, informatywności, powtarzalności i zawartości wolnej od błędów w przypadku niedoboru materiałów źródłowych w formie cyfrowej i graficznej. Aby sprawdzić własną bazę danych, uruchom narzędzie Tibco Clarity (uruchomione w 1997 r.) lub oprogramowanie OpenRefine.
Ciągłe doskonalenie i rozwiązania multimodalne
Python to popularny język programowania, który jednocześnie stanowi podstawę do tworzenia aplikacji AI ze względu na prostotę poleceń. Przypadki twórców produktów pełne są rozwiązań AI dla Google i Netflix, usług hostingu wideo i strumieniowego przesyłania wideo. Aplikacje AI wymagają ciągłego udoskonalania:- przeszkol ich w zakresie analizowania wrażliwych i poufnych informacji;
- usuwaj nieodpowiednie i przerażające elementy z wygenerowanych zdjęć i filmów;
- algorytmy formularzy z szyfrowaniem baz danych klientów i firm, z którymi podpisano umowy o współpracy;
- Wykrywaj anomalie w proponowanych rozwiązaniach opracowanych przez sztuczną inteligencję.
Modalne przetwarzanie danych typu działania w modelu kameleona przybliża sztuczną inteligencję do ekskluzywnego dla paradoksu formatu ludzkiej refleksji. Autoregresja z wykorzystaniem protokołu 34B została wytrenowana na tokenach danych 10T, dzięki czemu model multimodalność zapewnia generowanie treści i obrazów o realistycznych parametrach.
4D w modelu PSG4DFormer i rozwój w dziedzinie czasu
Uczenie się według zasad 4D – uczenie się oparte na czasie – interpretuje informacje (dane, treści audiowizualne, wideo) na osi czasu. Dynamizm 4D to zrozumienie procesów zachodzących w czasie. Model PSD-4D tworzy węzły objętościowe, na krawędziach których zlokalizowane są badane obiekty.Następnie model poprzez zastosowanie adnotowanej bazy danych z maskami 4D dokonuje segmentacji i szczegółowo opracowuje sytuacje w określonym przedziale czasowym. Przypomina to tworzenie scenorysu w filmie, w którym reżyser rozdziela sceny i wydarzenia minuta po minucie. Model PSG4DFormer przewiduje tworzenie masek i późniejszy rozwój na osi czasu. Takie komponenty są podstawą do generowania przyszłych scen i wydarzeń.
Testowanie przed uruchomieniem
Testowanie aplikacji przyspiesza się poprzez integrację pakietu Pythona z frameworkiem Django. Programiści Pythona i webowcy, inżynierowie DevOps wykorzystują w tym celu wbudowane narzędzia Django, piszą przypadki testowe do testów jednostkowych, a następnie osadzają pakiet w frameworku.W bibliotece Featuretools funkcje modeli ML opracowywane są automatycznie: w tym celu wybierane są zmienne z bazy danych, które stają się podstawą macierzy szkoleniowej. Dane w formacie czasu oraz z relacyjnych baz danych stają się panelami szkoleniowymi w procesie generowania.
Biblioteki, platformy i języki to elementy stosu
Na liście frameworków poprawiających wydajność modeli AI znajduje się otwarta biblioteka TensorFlow oraz platforma TFX, która przyspiesza wdrożenie gotowego projektu. Są one dopracowane pod kątem obrazów. Moduł PyTorch napisany jest w kilku językach, w tym w Pythonie, podstawowej wersji C++ oraz architekturze CUDA przeznaczonej dla procesorów i kart graficznych NVIDIA.Gdy brakuje fizycznych środowisk przechowywania i wdrożeń, stosuje się rozwiązania chmurowe SageMaker, Azure i Google. Julia to jeden z najpopularniejszych nowych języków do generowania aplikacji AI: podczas korzystania z poleceń napisanych w Julii ponad 81% poleceń jest wykonywanych szybko, dokładnie i przy minimalnych błędach. JavaScript i Python, R również wykazują dobre wyniki z dokładnością ponad 75%.
W stosie aplikacji dodajemy środowisko JupyterLab, bibliotekę NumPy dla tablic wielowymiarowych lub prostszy wariant Pand. Biblioteka Dask przeznaczona jest do analizy dużych baz danych z klastrami, wizualizacji i równoległości, integracji ze środowiskami i systemami w celu zmniejszenia kosztów utrzymania sprzętu.
Obsługuje XGBoost, TensorFlow, FastAPI
XGBoost 2.0 działa na zasadzie regresji wielowymiarowej i kwantylowej, uwzględniając wiele funkcji w drzewie operacji. Nowa funkcjonalność obejmuje ulepszony ranking i zoptymalizowane rozmiary histogramów, a interfejs PySpark stał się bardziej przejrzysty. Jeśli porównasz MXNet i TensorFlow, lepiej wybrać tę drugą platformę ze względu na lepszą łatwość uczenia się, debugowanie i szybkość ładowania danych.Asynchroniczne i szybkie operacje FastAPI sprawiają, że framework jest lepszy od Django, gdzie na serwerach standard WSGI musi zostać skonfigurowany do nowego asynchronicznego ASGI. Ze względu na to, że interfejs ma 6 lat, ma ograniczoną pojemność danych dla tokenów JWT i pamięci S3. Bierzemy pod uwagę, że biblioteki asynchroniczne często mają problemy z nieczytelnymi informacjami i czasami musimy dokonać zapisu wywołując funkcję generate() po przekazaniu zapytania SQL i materiałów. Uwaga: atrybut root_path nie jest zmieniany na „/api”, co jest niewygodne.
Konteneryzacja, wdrażanie i architektura modelu AI
Proces konteneryzacji rozpoczyna się w momencie połączenia komponentów do stworzenia aplikacji AI (kodu i bibliotek wraz z frameworkami). Samodzielny kontener jest pobierany z hosta i przenoszony do innego środowiska bez ponownej kompilacji. Docker Engine i Kubernetes są pionierami w tym segmencie, poszukiwanym systemem operacyjnym jest Linux (w chmurze lub lokalnie), OCI działają w trybie odczytu, bez modyfikacji. Na tej liście znajdują się VMware i LXC. Kontenery są czasami przechowywane na platformie GitHub: zwłaszcza gdy następuje wspólna praca nad projektem.Narzędzia do wdrażania obejmują zastrzeżoną platformę PaaS Heroku, bardziej zaawansowaną Elastic Beanstalk i Qovery, która wykorzystuje to, co najlepsze z obu zasobów. Do testów używają:
- Selenium z trzema rodzajami usług WebDriver, IDE i Grid;
- Platforma PyTest ze skalowalnymi testami w wersjach Python 3.8+ lub PyPy3;
- Szarańcza z testami obciążenia.
| Model architektury | Zadanie | Funkcje specjalne |
| Splotowy (CNN) | Wideo i obrazy | Dokładna identyfikacja, eliminacja szumów i błędów |
| Nawracające (RNN) | Dane cyfrowe i język | Przetwarzanie sekwencji |
| Ogólny kontradyktoryjność (GAN) | Generowanie nowych danych i obrazów | Symulacja z generowaniem nowych danych, jako podstawa do szkolenia |
Następnie szkolenie modelu AI jest dopracowywane w filigranowy sposób. Jeśli scenariusz zakłada wysokie wymagania i dokładne parametry, szkolenie kontynuuje się obserwacją – takie warunki są droższe. Aby znaleźć artefakty i wzorce w klastrowaniu, lepiej jest zdecydować się na samokształcenie. W przypadku projektów z zakresu robotyki i prostych gier typu „tap, aby zarobić” stosuje się wzmocnienie (zachętę lub karę – metoda „kija i marchewki”).
Czas rozwoju, sprawdzanie błędów
Koszt czasu opracowania, testowania i uruchomienia modelu sztucznej inteligencji wygląda mniej więcej tak, jak na diagramie. Algorytm wymaga dokładnego opisu wykonania zadania - tak aby efektem było nowe rozwiązanie do odkrywania wzorców. Łańcuch „iteracje-przewidywania-korekta” uzupełniają hiperparametry wprowadzone ręcznie przed rozpoczęciem sprawdzania krzyżowego w podzbiorach.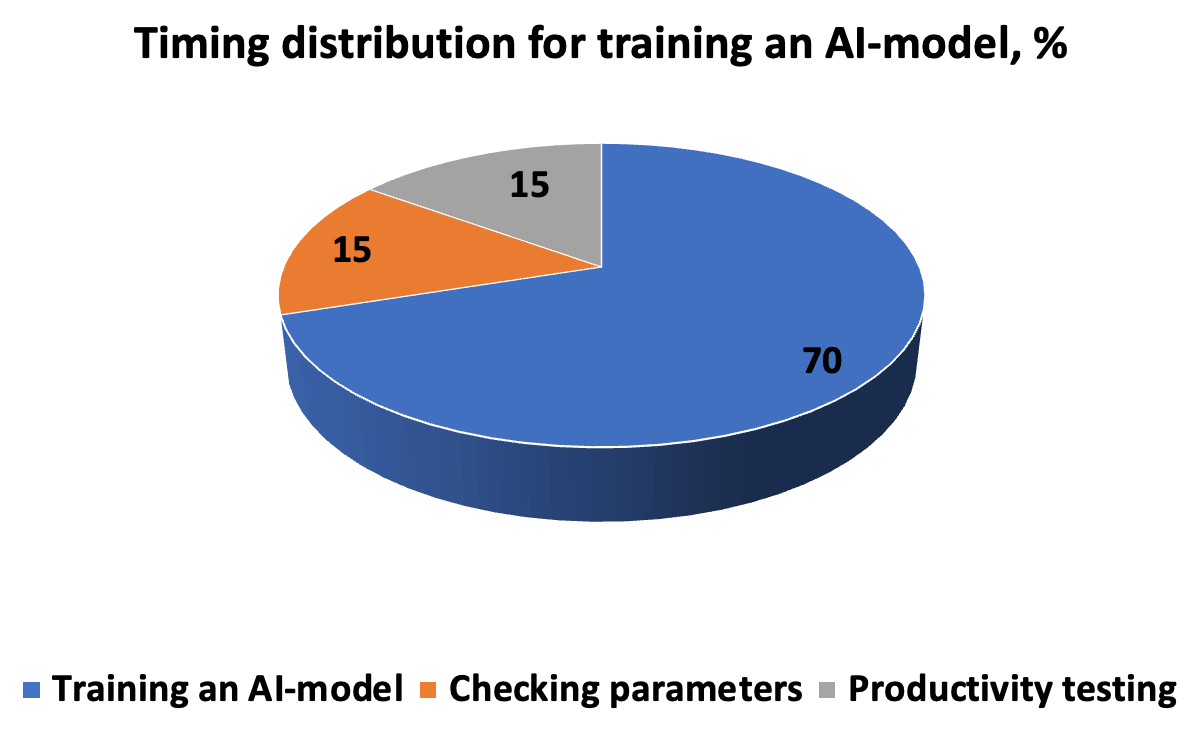
Aby model mógł wydajnie działać w rzeczywistych scenariuszach, musimy ocenić poprawność i szybkość reakcji. Dlatego do parametrów pomiaru zalicza się precyzję i powtarzalność, metrykę ROC-AUC, gdzie nie ma konieczności odcięcia progu (dla niezrównoważonej bazy danych), F-score określający proporcję rozwiązań dodatnich, błąd średniokwadratowy MSE oraz R- kwadratowy współczynnik determinacji. Za dopuszczalny uważa się błąd w granicach 5%; po zmniejszeniu do 1 i 0,1% wynik uważa się za bardzo dokładny.
RAG i dostosowywanie, integracja backendu lub frontendu, testowanie
Metodę RAG stosuje się do opracowywania modeli generatywnych, w których wektory i semantyka są aproksymowane segment po segmencie w oparciu o kontekst i trafność. Podstawą RAG jest wyodrębnienie informacji z obszernych baz danych, a następnie wygenerowanie ich w modelu w celu uzyskania dokładnej odpowiedzi. Dostrajanie do eksperymentów specjalistycznych obejmuje normalizację (redukcję do wspólnych parametrów) oraz po adaptacji tokenizację. Aby model AI był produktywny, integracja odbywa się, w zależności od zadania, w backendzie lub frontendzie. Lepiej jest zintegrować model językowy z częścią serwerową, a pracę z klientami - z interfejsem.W IoT preferowane jest działanie peryferyjne na urządzeniu, ponieważ chroni to prywatność i zapewnia szybką wydajność. U podstaw IoT leży generowanie danych, którego istotą jest konwergencja AI z IoT. Ta synergia zwiększa funkcjonalność obu części, dając początek AIoT. Aby jednak zwiększyć moc i skalowalność funkcjonalności, lepiej zastosować technologie oparte na chmurze, korzystając z wbudowanych protokołów API. Jeśli ważne jest, aby usłyszeć opinie klientów (wygoda, przejrzystość, szybkość), wbudowaliśmy funkcję informacji zwrotnej.
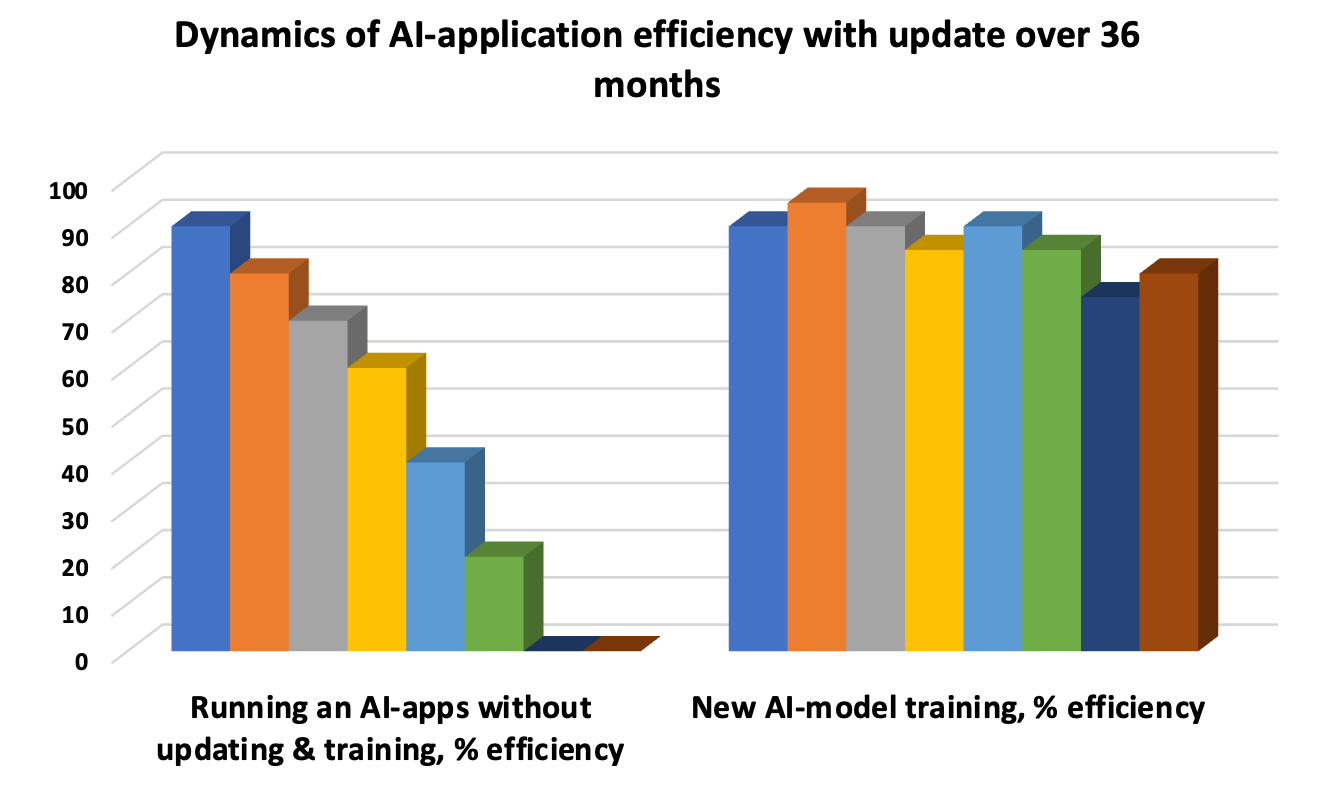
Aktualizacja modelu AI jest koniecznością, aby uniknąć „dryftu”, gdy leżące u jego podstaw wzorce staną się nieaktualne, a dokładność reakcji spadnie. Dlatego testowanie iteracyjne wydłuża cykl życia modelu. Zautomatyzowane testy jednostkowe, okresowe testy integracyjne w celu oceny łącznej wydajności poszczególnych funkcji oraz testy akceptacyjne UAT to trzy obowiązkowe „wieloryby” oceny wydajności i testowania.
ZBrain – open source i płynna integracja
ZBrain jest przykładem rozbudowanej platformy symbiozy procesów i informacji przedsiębiorstwa z wbudowaną funkcjonalnością AI. Otwarty kod źródłowy z szablonami i zintegrowanymi z pamięcią LLM zapewnia:- przechowywanie i wymiana walut fiducjarnych i kryptowalut w parach, z rejestracją transakcji w oparciu o blockchain;
- produktywna praca nad przejrzystym i szczegółowym infopanelem;
- zarządzanie aplikacjami wieloplatformowymi i wieloplatformowymi na etapach mikro i makro;
- wdrażanie technologii kognitywnych i rozwiązań projektowych.
Wyraźnie demokratyzuje i upraszcza transformację procesów biznesowych, gdy użytkownicy sami opracowują i wdrażają modele AI na potrzeby logiki marketingowej i produkcyjnej oraz przepływów pracy bez pisania kodu. Przykładowo płynna integracja Flow dynamicznie wybiera właściwe dane i na ich podstawie przygotowuje rozwiązania AI.
Obliczenia kwantowe: pozbycie się wąskich gardeł Neumanna i zmniejszenie kosztów energii
Obliczenia kwantowe służą do przetwarzania dużych zbiorów danych. Algorytmy stosowane w technologiach kwantowych przyspieszają procesy uczenia się AI w medycynie, materiałach, procesach biologicznych i chemicznych oraz redukują emisję CO2 i gazów cieplarnianych. Aby umożliwić uczenie się miliardów parametrów, potrzebne są ultrawydajne procesory graficzne lub TPU, które są zaprojektowane do wykonywania kilku równoległych operacji.Tymczasem należy przezwyciężyć problem wąskiego gardła Neumanna (VNB), aby procesor nie mógł czekać, aż pamięć RAM zapewni dostęp do procesu. Celem jest zwiększenie szybkości pobierania i przesyłania danych z bazy danych lub magazynu. Nawet duża prędkość procesorów wielordzeniowych z 32-64 GB lub więcej pamięci RAM może nie uzasadniać inwestycji w pojemność, gdy transfer informacji z chmury jest ograniczony. Aby rozwiązać problem VNB, rozszerzają pamięć podręczną, wprowadzają przetwarzanie wielowątkowe, zmieniają konfigurację magistrali, uzupełniają komputer PC o zmienne dyskretne, wykorzystują memrystory i wykonują obliczenia w środowisku optycznym. Ponadto istnieje również modelowanie procesów biologicznych, takich jak kwantyzacja.
Paradygmat cyfrowej AI w przetwarzaniu równoległym zwiększa zużycie energii i czas procesów uczenia się. Z tego powodu kubity w superpozycjach (wiele pozycji w jednym okresie czasu) i pozycjach splątania są lepsze niż klasyczne bity, pod warunkiem zachowania stabilności. W przypadku AI technologie kwantowe są lepsze ze względu na obniżone koszty rozwoju i analizy danych w wielu konfiguracjach. „Tensoryzacja” kompresuje modele AI i umożliwia wdrożenie na prostych urządzeniach, poprawiając jednocześnie jakość surowych danych.
Zasady cyberobrony
Zwróć uwagę na cyberobronę – algorytmy AI identyfikują wzorce w działaniach niosących zagrożenia, przewidują potencjalne cyberzagrożenia i chronią prywatność, co jest imperatywem prawnym i etycznym. Przepisy RODO i CCPA, podobnie jak inne protokoły obronne, muszą być przestrzegane, gwarantując:- anonimizacja klientów i zapewnienie, że nie będzie luk umożliwiających osobom trzecim ich identyfikację;
- rozróżnianie wrażliwych punktów w danych paszportowych, e-mailach, numerach telefonów i innych dokumentach, których nie można ujawnić;
- wspólna analiza segmentów informacyjnych w dwóch lub trzech niepowiązanych systemach, bez ujawniania pełnej bazy.
Zatruwanie wzorców (wprowadzenie szkodliwych elementów) do sztucznej inteligencji, obecność przeciwstawnych luk prowadzi do błędnej klasyfikacji. Dlatego też podejście całościowe powinno obejmować zasady ochrony od etapu projektowania po testowanie i wdrożenie, aby zminimalizować wyzwania i ryzyko.
Praca AI: ekspert i NLP, algorytmy genetyczne i kreatywność
Zidentyfikowano kluczowe cechy szkolenia AI w przypadku, gdy celem jest rozwiązywanie zadań na poziomie eksperckim, kierując się rozumowaniem i analizą wielomilionowej bazy empirycznej z wizualnym uwzględnieniem konkretnych sytuacji. Na przykład wskaźnik wegetacji NDVI służy do określenia poziomu wzrostu roślinności. Są jednak niuanse – co innego, gdy we roślinności rosną zboża lub rośliny oleiste, a co innego, gdy są to chwasty. Sztuczna inteligencja w aplikacji powinna być w stanie rozróżnić kolorem to, co rośnie lepiej i dać odpowiedź. Podobnie - rozpoznaj typ twarzy, parametry liniowe sylwetki, aby uzyskać zalecenia dotyczące doboru kosmetyków lub ubrań do stylizacji.Zasada NLP jest wprowadzana do algorytmów przy planowaniu pracy AI jako psychologa – analizowana jest naturalna mowa i wyjaśniany jest nastrój psycho-emocjonalny pacjenta. Następnie na pytania udzielana jest wygenerowana odpowiedź zbliżona do ludzkiego dźwięku i intonacji. Istnieją również algorytmy genetyczne, gdy tworzone są boty, które rozwiązują miliony problemów, a następnie te najgorsze są usuwane, pozostawiając najlepsze. Połączenie udanych osiągnięć i późniejszej generacji nowych, dostosowanych i przetestowanych modeli, opartych na poprzednikach i szeregu iteracji, prowadzi do całkowitego rozwiązania problemu.
Rozwój programu AI powinien być podejściem kreatywnym. Możesz na przykład stworzyć chatbota w postaci zabawnego zwierzęcia lub ptaka, zabawnego elfa lub porywającej rośliny lub czegoś pragmatycznego, jak stworzyć NFT do sprzedaży. Ci, którzy czytali Kurta Vonneguta, pamiętają historię o superkomputerze, który nabył ludzkie myślenie. Dlatego też, jeśli postać będzie wypowiadać kwestie, wykorzystując poprzednią komunikację, udzielać wskazówek i krótkich informacji prasowych na temat nowych produktów, klienci pokochają sztuczną inteligencję i przyzwyczają się do niej, zaufają. Wzrost sprzedaży wyniesie co najmniej 10-20%.
MVP, CRISP-DM i stawki
Pierwszym krokiem po opracowaniu i wdrożeniu AI w aplikacji jest uruchomienie MVP z analizą i wsparciem, poprawą funkcjonalności i ciągłymi testami. Jeśli firma planuje utrzymanie aplikacji AI przez 10-20 lat, wymagane są regularne kwartalne aktualizacje baz danych, testowanie różnymi typami, zgodnie z metodologią CRISP-DM.Aby zidentyfikować koszty finansowe i czasowe, skontaktuj się z Merehead ze swoim zadaniem i pytaniami: rozwój sztucznej inteligencji koszt zaczyna się od 20 000 dolarów i trwa do jednej czwartej czasu. Czas tworzenia aplikacji dla aplikacji o średniej złożoności z łańcuchami logicznymi na trzech do pięciu poziomach jest dwukrotnie dłuższy, a cena sięga 100 000 dolarów. W przypadku skomplikowanych projektów matematycznych z analizą ekspercką i dokładnością odpowiedzi na poziomie 99,9% - do 500 000 USD. Przed rozpoczęciem prac opracujmy harmonogram projektu i zaplanujmy oczekiwane rezultaty rentowności.


