
Sin pretender cubrir todos los matices de la planificación, el desarrollo y la prueba de aplicaciones de IA, creemos que tanto los desarrolladores experimentados como los principiantes encontrarán posiciones útiles en las instrucciones y ejemplos detallados. La gama de tecnologías de aplicación basadas en el uso de redes neuronales es enorme: desde un robot informador simplificado hasta una aplicación equipada con funcionalidades para planificar el volumen de operaciones comerciales, entrega, cálculo y previsión de beneficios, control de empleados e interacción con los clientes. Algunos ejemplos exitosos de implementaciones de IA que comenzaron con una inversión mínima incluyen Grammarly y Duolingo, los servicios Waze y Canva y el editor de fotografías FaceApp.
Descripción general de las áreas de aplicación de la IA
El funcionamiento de la IA tiene lugar dentro del lecho de Procusto de varias reglas y categorías, entre ellas:- tener GPU potentes, miles de gigabytes de datos y RAM de múltiples nodos conectados en red para entrenar el modelo;
- integrar el Internet de las cosas y algoritmos para combinar información de múltiples capas en modelos de IA;
- predecir eventos, comprender situaciones paradójicas y coordinar sistemas de alta precisión;
- implementar API para generar nuevos protocolos y patrones de interacción.
El aprendizaje automático típico de ML reemplaza al operador al comienzo de la comunicación con el centro de soporte, aclarando preguntas básicas. Cuando los VCA se realizan en un formato profundo, las solicitudes se personalizan y la seguridad de los contactos aumenta gracias al reconocimiento de voz y al estado psicológico de los clientes. La automatización de tareas actuales como la búsqueda de billetes, el pedido de mercancías y la selección de puntos de ruta forma parte de las funciones de los operadores virtuales. Por este motivo, la elección de ML o VCA depende de los problemas a resolver.
Logística, valoración de clientes y captación
La cadena de suministro y la logística coordinadas por IA simplifican los negocios al mostrar la disponibilidad de existencias de los artículos, indicar las reservas, pronosticar la eficiencia y los períodos de recuperación. Este es el trabajo de aplicaciones y servicios de IA de alto nivel, con precios que comienzan en 100.000 dólares. Auditar partidas de ingresos y gastos e identificar tendencias en la segmentación de ganancias es un ejemplo de aplicación de IA en la industria financiera. La aplicación funciona de forma similar, personalizando a cada cliente y analizando la eficiencia de las ventas: las estrategias de promoción en los medios mejoran las posiciones de marketing.Las capacidades de PNL de AI proporcionan una búsqueda inicial de empleados e identifican sus habilidades profesionales. En el proceso, AI HR recomienda cambios en las descripciones de trabajo del personal si ve una asimilación progresiva de habilidades y automaticidad, lo que promueve el crecimiento profesional.
Fundamento: las tareas adecuadas y datos precisos
Las dos primeras fases de planificación de operaciones organizativas y tecnológicas para el desarrollo de una aplicación de IA son un programa fundamentalmente sólido con varios pasos. El diagrama muestra claramente que la primera parte incluye la formulación del problema, la selección de herramientas, los recursos necesarios, los costos esperados y las ganancias. El segundo paso es responsable de la formación de bases de datos validadas y precisas listas para el entrenamiento del modelo.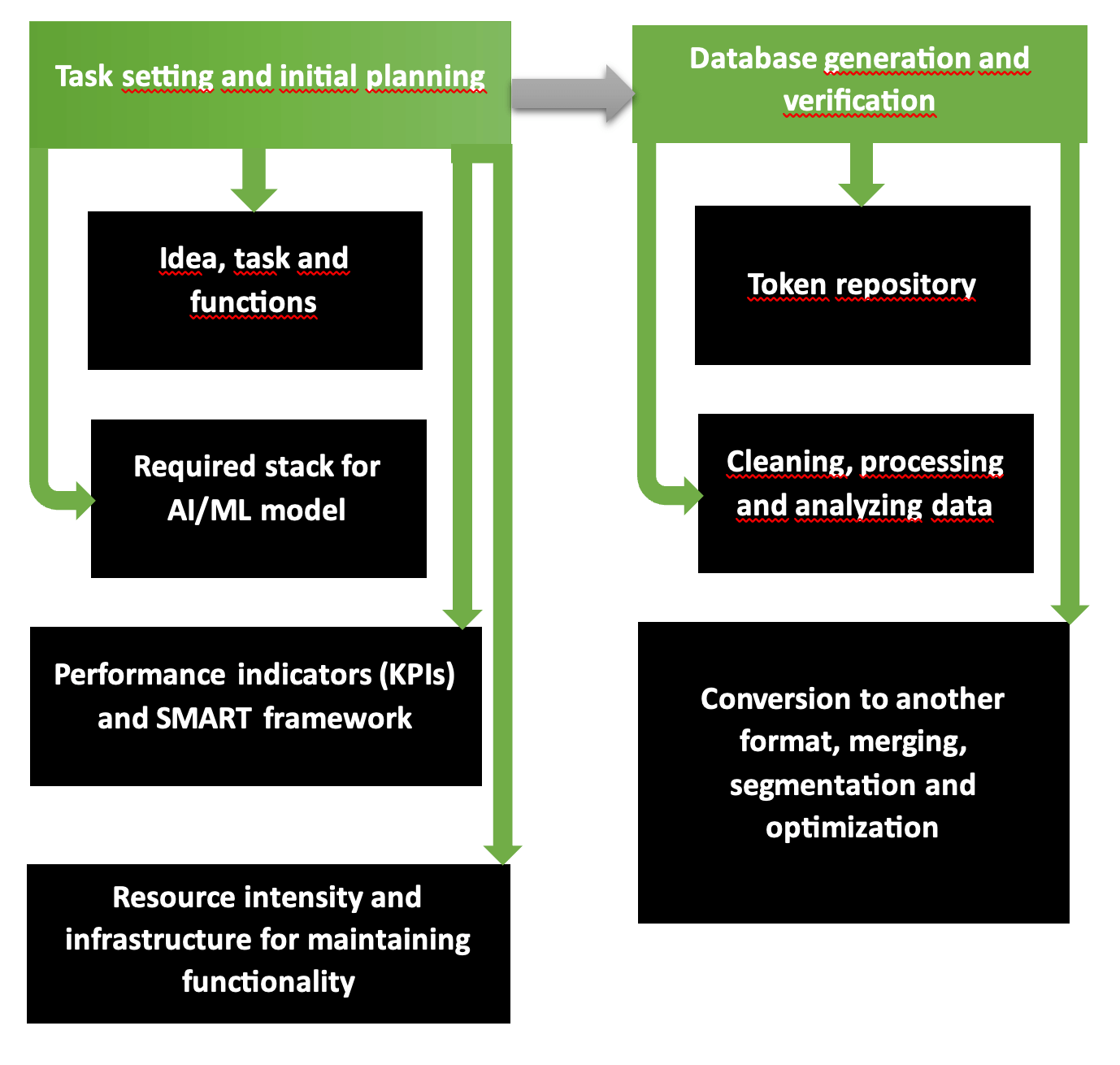
Así empieza a funcionar la empresa de desarrollo de IA de aplicaciones multiplataforma. La cadena “requisitos - objetivos - alineación de visión - estilo unificado” está pensada según la estructura SMART y categorizada paso a paso en Scrum o Agile. Los objetivos y la disponibilidad de recursos determinan qué alcance de servicios y bienes se pueden proporcionar en el modo planificado y reducirse o ampliarse en caso de escasez o abundancia de fondos.
Common Crawl, plataformas como Kaggle o AWS proporcionan bases de datos cuya precisión, informatividad, repetición y contenido libre de errores han sido verificados en caso de escasez digital y gráfica de material fuente. Para comprobar su propia base de datos, ejecute la utilidad Tibco Clarity (lanzada en 1997) o el software OpenRefine.
Mejora constante y soluciones multimodales
Python es un lenguaje de programación popular, que al mismo tiempo representa la base para la creación de aplicaciones de IA debido a la simplicidad de los comandos. Los casos de desarrolladores de productos están llenos de soluciones de inteligencia artificial para Google y Netflix, alojamiento de vídeos y plataforma de streaming. Las aplicaciones de IA deben mejorarse constantemente:- capacitarlos para analizar información sensible y confidencial;
- eliminar elementos inapropiados y espeluznantes de las fotos y vídeos generados;
- formar algoritmos con cifrado de bases de datos de clientes y empresas con las que se hayan firmado acuerdos de cooperación;
- realizar detección de anomalías en soluciones propuestas desarrolladas por IA.
El procesamiento modal de datos del tipo de acción del modelo camaleón acerca la IA al formato exclusivo de la paradoja de la reflexión humana. La autorregresión que utiliza el protocolo 34B se ha entrenado en tokens de datos de 10T, por lo que el modelo multimodal garantiza la generación de contenido e imágenes con parámetros realistas.
4D en el modelo PSG4DFormer y desarrollo en el dominio del tiempo
El aprendizaje según reglas 4D - aprendizaje basado en el tiempo - interpreta la información (datos, contenido audiovisual, vídeo) en una línea de tiempo. Dinamismo 4D es la comprensión de los procesos en curso en el tiempo. El modelo PSD-4D forma nodos volumétricos en cuyos bordes se ubican los objetos a estudiar.Posteriormente, el modelo aplicando la base de datos anotada con máscaras 4D realiza la segmentación y elabora situaciones en detalle dentro de un rango de tiempo determinado. Esto es similar al guión gráfico de una película donde el director distribuye escenas y eventos minuto a minuto. El modelo PSG4DFormer predice la creación de máscaras y su posterior desarrollo en una línea de tiempo. Estos componentes son la base para generar escenas y eventos futuros.
Pruebas antes del inicio
Las pruebas de aplicaciones se aceleran integrando el paquete Python con el marco Django. Los desarrolladores web y de Python, los ingenieros de DevOps utilizan herramientas integradas de Django para este propósito, escriben casos de prueba para pruebas unitarias y luego integran el paquete en el marco.En la biblioteca Featuretools, las características de los modelos ML se desarrollan automáticamente: para ello, las variables se seleccionan de una base de datos para convertirse en la base de la matriz de entrenamiento. Los datos en formato horario y provenientes de bases de datos relacionales se convierten en paneles de capacitación durante el proceso de generación.
Bibliotecas, plataformas y lenguajes son elementos de pila
La lista de marcos que mejoran el rendimiento de los modelos de IA incluye la biblioteca TensorFlow de código abierto y la plataforma TFX, que acelera la implementación de un proyecto terminado. Estos están perfeccionados para imágenes. El módulo PyTorch está escrito en varios lenguajes, incluido Python, una versión básica de C++ y la arquitectura CUDA diseñada para procesadores y tarjetas gráficas NVIDIA.Cuando los entornos de implementación y almacenamiento físico son escasos, se utilizan las soluciones en la nube de SageMaker, Azure y Google. Julia es uno de los nuevos lenguajes más populares para generar aplicaciones de IA: cuando se utilizan comandos escritos en Julia, más del 81% de los comandos se ejecutan de forma rápida, precisa y con errores mínimos. JavaScript y Python, R también muestran buenos resultados con más del 75% de precisión.
En la pila de aplicaciones agregamos el entorno JupyterLab, la biblioteca NumPy para matrices multidimensionales o una variante más simple de Pandas. La biblioteca Dask está diseñada para el análisis de grandes bases de datos con clusters, visualización y paralelización, integración con entornos y sistemas para reducir los costos de mantenimiento de hardware.
Características XGBoost, TensorFlow, FastAPI
XGBoost 2.0 funciona según el principio de regresión multivariante y cuantil, e incluye muchas funciones en el árbol de operaciones. La nueva funcionalidad incluye clasificación mejorada y tamaños de histograma optimizados, y la interfaz de PySpark se ha vuelto más clara. Si compara MXNet y TensorFlow, es mejor elegir la última plataforma debido a una mejor capacidad de aprendizaje, depuración y velocidad de carga de datos.Las operaciones rápidas y asíncronas de FastAPI hacen que el marco sea preferible a Django, donde en los servidores el estándar WSGI debe configurarse según el nuevo ASGI asíncrono. Debido a que la interfaz tiene 6 años, tiene una capacidad de datos limitada para tokens JWT y almacenamiento S3. Tomamos en cuenta que las bibliotecas asíncronas a menudo tienen problemas con información ilegible y a veces tenemos que escribir invocando ejecutar() después de pasar la consulta SQL y los materiales. Nota: el atributo root_path no se cambia a "/api", lo cual es un inconveniente.
Containerización, implementación y arquitectura de modelo de IA
El proceso de contenerización se inicia cuando se reúnen los componentes para crear una aplicación de IA (código y bibliotecas con frameworks). Un contenedor independiente se extrae del host y se traslada a otro entorno sin necesidad de volver a compilarlo. Docker Engine y Kubernetes son los pioneros en este segmento, el SO demandado es Linux (en la nube o local), los OCI funcionan en modo lectura, sin modificaciones. VMware y LXC están en esta lista. A veces los contenedores se almacenan en la plataforma GitHub: especialmente cuando hay trabajo conjunto en un proyecto.Las herramientas de implementación incluyen la plataforma PaaS patentada Heroku, el más sofisticado Elastic Beanstalk y Qovery, que aprovecha lo mejor de ambos recursos. Para las pruebas, utilizan:
- Selenium con tres tipos de servicios WebDriver, IDE y Grid;
- Plataforma PyTest con pruebas escalables en versiones Python 3.8+ o PyPy3;
- Langosta con pruebas de carga.
| Arquitectura modelo | Asignación | Características especiales |
| Convolucional (CNN) | Vídeos e imágenes | Identificación precisa, eliminación de ruidos y errores |
| Recurrente (RNN) | Datos digitales y lenguaje | Procesamiento de secuencia |
| Conversación general (GAN) | Generando nuevos datos e imágenes | Simulación con generación de nuevos datos, como base para el entrenamiento |
A continuación, se perfecciona con precisión el entrenamiento del modelo de IA. Si el escenario incluye requisitos elevados con parámetros precisos, el entrenamiento continúa con la observación; estas condiciones son más caras. Para encontrar artefactos y patrones en el clustering, es preferible optar por el autoentrenamiento. Para proyectos de robótica y juego en Telegram simples, refuerzo (estímulo o castigo - el "Se utiliza el método del palo y la zanahoria)".
Tiempo de desarrollo, comprobación de errores
El costo de tiempo de desarrollar, probar y ejecutar un modelo de IA se parece al diagrama. El algoritmo requiere una descripción precisa de la ejecución de la tarea, de modo que el resultado sea una nueva solución para el descubrimiento de patrones. La cadena “iteraciones-predicciones-corrección” se completa con hiperparámetros ingresados manualmente antes de iniciar la validación cruzada en subconjuntos.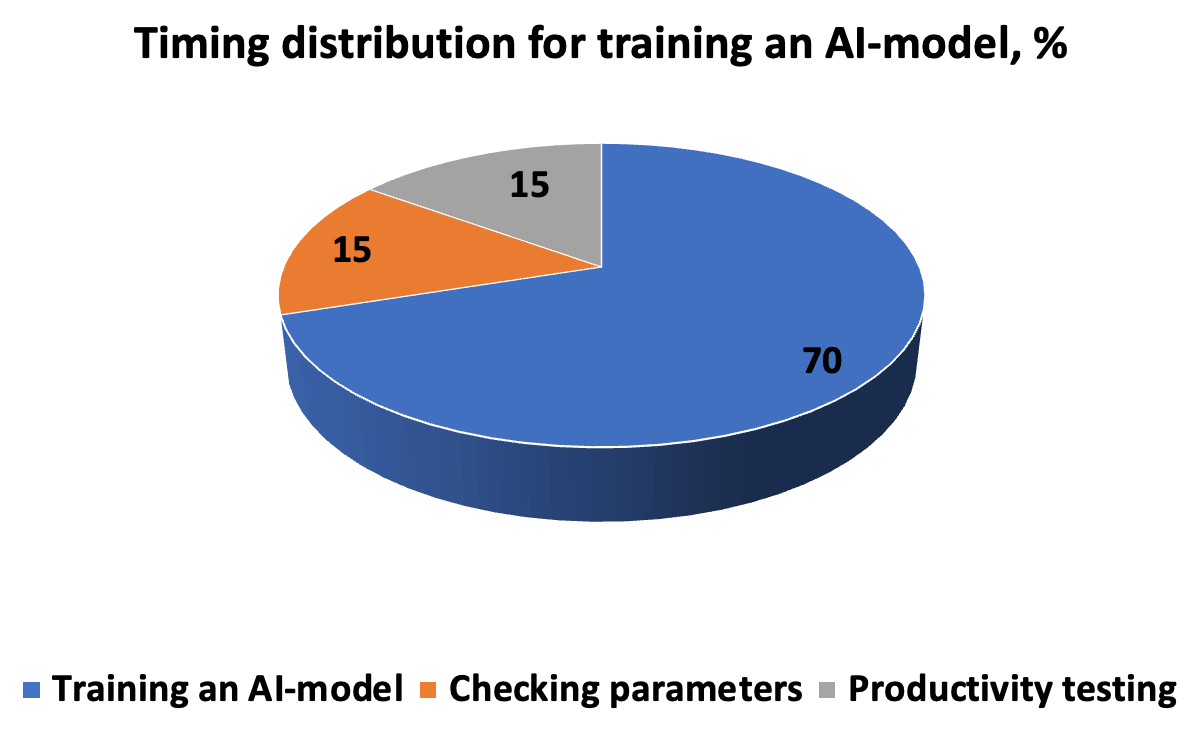
Para que el modelo funcione productivamente en escenarios del mundo real, debemos evaluar la corrección y la velocidad de respuesta. Por lo tanto, los parámetros de medición incluyen precisión y repetibilidad, métricas ROC-AUC, donde no es necesario cortar el umbral (para una base de datos desequilibrada), puntuación F, que especifica la proporción de soluciones positivas, error cuadrático medio MSE y R- coeficiente de determinación al cuadrado. Un error dentro del 5% se considera aceptable; cuando se reduce a 1 y 0,1%, el resultado se considera muy preciso.
RAG y personalización, integración backend o frontend, pruebas
El método RAG se utiliza para desarrollar modelos generativos, donde los vectores y la semántica se aproximan segmento por segmento según el contexto y la relevancia. La base de RAG es extraer información de bases de datos voluminosas y luego generarla en un modelo para obtener una respuesta precisa. El ajuste para experimentos especializados incluye la normalización (reducción a parámetros comunes) y, después de la adaptación, tokenización. Para que el modelo de IA sea productivo, la integración se realiza, según la tarea, en el backend o en el frontend. Es mejor integrar el modelo de lenguaje en la parte del servidor y trabajar con los clientes en la interfaz.En IoT, se prefiere la operación periférica en el dispositivo, ya que preserva la privacidad y proporciona un rendimiento rápido. El núcleo de IoT es la generación de datos, cuya esencia es la convergencia de la IA con la IoT. Esta sinergia fortalece la funcionalidad de las dos partes, dando origen a AIoT. Sin embargo, para mejorar el poder y la escalabilidad de la funcionalidad, es mejor aplicar tecnologías basadas en la nube utilizando protocolos API integrados. Si es importante escuchar los comentarios de los clientes (comodidad, claridad, velocidad), incorporamos una función de comentarios.
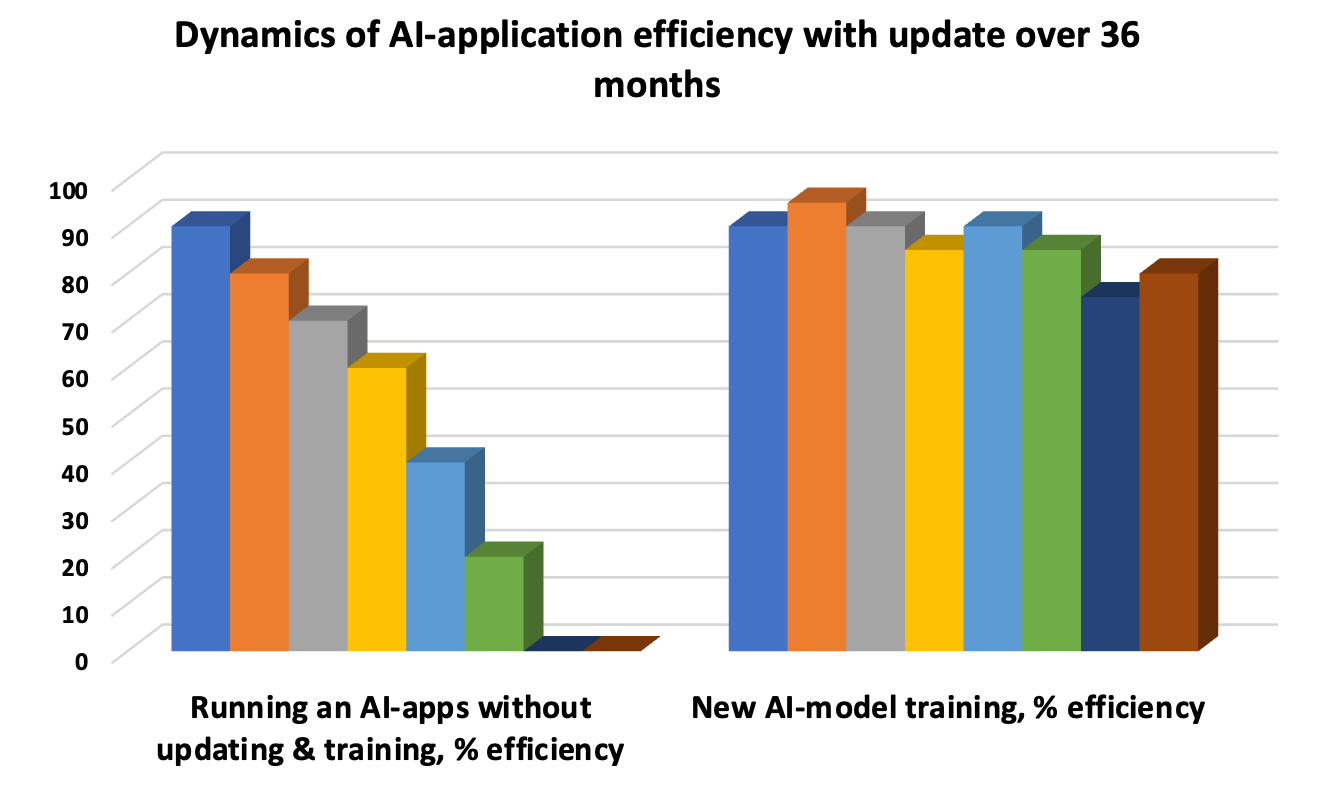
Actualizar el modelo de IA es una necesidad para evitar la "deriva" cuando los patrones subyacentes quedan obsoletos y la precisión de la respuesta disminuye. Por lo tanto, las pruebas iterativas extienden el ciclo de vida del modelo. Las pruebas unitarias automatizadas, las pruebas de integración periódicas para evaluar el desempeño agregado de funciones individuales y las pruebas de aceptación de UAT son las tres "ballenas" obligatorias de la evaluación y las pruebas de desempeño.
ZBrain: código abierto e integración perfecta
ZBrain es un ejemplo de una plataforma elaborada para la simbiosis de información y procesos empresariales con funcionalidad de IA integrada. El código fuente abierto con plantillas y memoria integrada LLM proporciona:- almacenamiento e intercambio de fiat y criptomonedas en pares, con registro de transacciones basado en blockchain;
- trabajo productivo en un panel informativo claro y detallado;
- gestión de aplicaciones multiplataforma y multiplataforma en etapas micro y macro;
- implementación de tecnologías cognitivas y soluciones orientadas a proyectos.
Claramente democratiza y simplifica la transformación de los procesos de negocio cuando los propios usuarios desarrollan e implementan modelos de IA para la lógica y los flujos de trabajo de marketing y producción sin escribir código. Por ejemplo, la perfecta integración de Flow selecciona dinámicamente los datos correctos y prepara soluciones de IA basadas en ellos.
Computación cuántica: alejarse de los cuellos de botella de Neumann y reducir los costes energéticos
La computación cuántica se utiliza para procesar grandes conjuntos de datos. Los algoritmos utilizados en las tecnologías cuánticas aceleran los procesos de aprendizaje de la IA en medicina, materiales, procesos biológicos y químicos, y reducen las emisiones de CO2 y gases de efecto invernadero. Para permitir el aprendizaje de miles de millones de parámetros, se necesitan procesadores gráficos o TPU ultrapotentes que estén diseñados para realizar varias operaciones en paralelo.Mientras tanto, se debe superar el problema del cuello de botella de Neumann (VNB) para que el procesador no pueda esperar a que la RAM proporcione acceso al proceso. El objetivo es aumentar la velocidad de recuperación y transferencia de datos desde la base de datos o el almacenamiento. Incluso la alta velocidad de los procesadores multinúcleo con 32-64 GB o más de RAM puede no justificar la inversión en capacidad cuando la transferencia de información desde la nube es limitada. Para resolver el problema de VNB, expanden el caché, introducen procesamiento multiproceso, cambian la configuración del bus, complementan la PC con variables discretas, usan memristores y computan en un entorno óptico. Además, también existe el modelado por principio de procesos biológicos como la cuantificación.
El paradigma de la IA digital en procesamiento paralelo aumenta el consumo de energía y el tiempo de los procesos de aprendizaje. Por esta razón, los qubits en superposiciones (múltiples posiciones en un período de tiempo) y en posiciones de entrelazamiento son preferibles a los bits clásicos, siempre que se preserve la estabilidad. Para la IA, las tecnologías cuánticas son mejores debido al costo reducido de desarrollo y análisis de datos en múltiples configuraciones. La "tensorización" comprime los modelos de IA y permite la implementación en dispositivos simples al tiempo que mejora la calidad de los datos sin procesar.
Reglas de ciberdefensa
Preste atención a la ciberdefensa: los algoritmos de IA identifican patrones en las actividades portadoras de amenazas, predicen posibles amenazas cibernéticas y protegen la privacidad, lo cual es un imperativo legal y ético. Las normas GDPR y CCPA, al igual que otros protocolos de defensa, deben respetarse garantizando:- anonimizar a los clientes y garantizar que no haya lagunas para que terceros puedan identificarlos;
- diferenciar puntos sensibles en datos de pasaportes, correos electrónicos, números de teléfono y otros documentos que no pueden divulgarse;
- análisis conjunto de segmentos de información en dos o tres sistemas desconectados, sin revelar la base completa.
El envenenamiento de patrones (introducción de elementos maliciosos) en la IA y la presencia de vulnerabilidades adversas conducen a una clasificación errónea. Es por eso que un enfoque holístico debe incluir principios de protección desde la etapa de desarrollo hasta las pruebas y la implementación para minimizar los desafíos y riesgos.
Trabajo de IA: experto y PNL, mediante algoritmos genéticos y creatividad
Se identificaron las características clave del entrenamiento de IA cuando el objetivo es resolver tareas a nivel experto, guiados por el razonamiento y el análisis de una base de datos empírica multimillonaria con una consideración visual de situaciones específicas. Por ejemplo, el índice de vegetación NDVI se utiliza para determinar el nivel de crecimiento de la vegetación. Pero hay matices: una cosa es cuando en la vegetación crecen cereales o cultivos de semillas oleaginosas, y otra cuando se trata de malas hierbas. La IA de la aplicación debería poder distinguir por color qué crece mejor y dar una respuesta. Del mismo modo, reconozca el tipo de rostro, los parámetros lineales de la figura para obtener recomendaciones sobre la elección de cosméticos o ropa para su vestimenta.El principio de PNL se introduce en los algoritmos al planificar el trabajo de la IA como psicólogo: se analiza el habla natural y se aclara el estado de ánimo psicoemocional del paciente. Luego, las preguntas se responden con una respuesta generada que se acerca al sonido y la entonación humanos. También existen algoritmos genéticos, cuando se crean bots para resolver millones de problemas y luego se cortan los peores, dejando los mejores. La combinación de desarrollos exitosos y la posterior generación de nuevos modelos adaptados y probados, basados en los predecesores y en una serie de iteraciones, conduce a una solución completa del problema.
El desarrollo de programas de IA debe ser un enfoque creativo. Por ejemplo, puedes crear un chatbot con la forma de un animal o un pájaro divertido, un elfo divertido o una planta enérgica, o algo pragmático como un bot de arbitraje para operar. Quienes leen a Kurt Vonnegut recuerdan la historia de una supercomputadora que adquirió el pensamiento humano. Por lo tanto, si el personaje pronuncia líneas, utilizando la comunicación previa, da consejos y breves comunicados de prensa sobre nuevos productos, los clientes amarán y se acostumbrarán a la IA, confiarán. El crecimiento de las ventas será de al menos un 10-20%.
MVP, CRISP-DM y tarifas
El primer paso después de desarrollar e implementar IA en una aplicación es lanzar un MVP con análisis y soporte, mejora de funcionalidad y pruebas permanentes. Si una empresa planea mantener una aplicación de IA durante 10 a 20 años, se requieren actualizaciones periódicas trimestrales de las bases de datos y pruebas de diferentes tipos, según la metodología CRISP-DM.Para identificar costos financieros y de tiempo, comuníquese con Merehead con su tarea y preguntas. El coste de crear una IA comienza en 20.000 dólares. El tiempo de desarrollo de aplicaciones para aplicaciones de complejidad media con cadenas lógicas de tres a cinco niveles es el doble y el precio alcanza los 100.000 dólares. Para proyectos matemáticos complicados con análisis experto y una precisión del 99,9 % en las respuestas: hasta 500 000$. Desarrollamos una hoja de ruta del proyecto y planificamos los resultados de rentabilidad esperados antes de comenzar a trabajar.


