







Company
About us
Merehead is a blockchain software development company that helps businesses create and grow in the cryptocurrency industry. We develop innovative and secure solutions for startups, fintech companies, and large enterprises.
For over 10 years, we have been building reliable blockchain products—from P2P platforms and payment gateways to banking applications and DeFi ecosystems. By leveraging cutting-edge technologies, we ensure security, scalability, and high performance.
Our main advantage is deep expertise and a proven track record in implementing complex blockchain projects. We help our clients optimize processes, reduce costs, and enhance competitiveness by delivering customized technologies for business growth and expansion.

Solutions
Custom & Scalable
We specialize mainly in financial projects, especially using blockchain technologies and
AI integration into mobile or web applications.
Crypto Exchanges
P2P Platforms
Crypto Banks
Trading Bots
Forex Platforms
Binary Options
Tokenization Assets

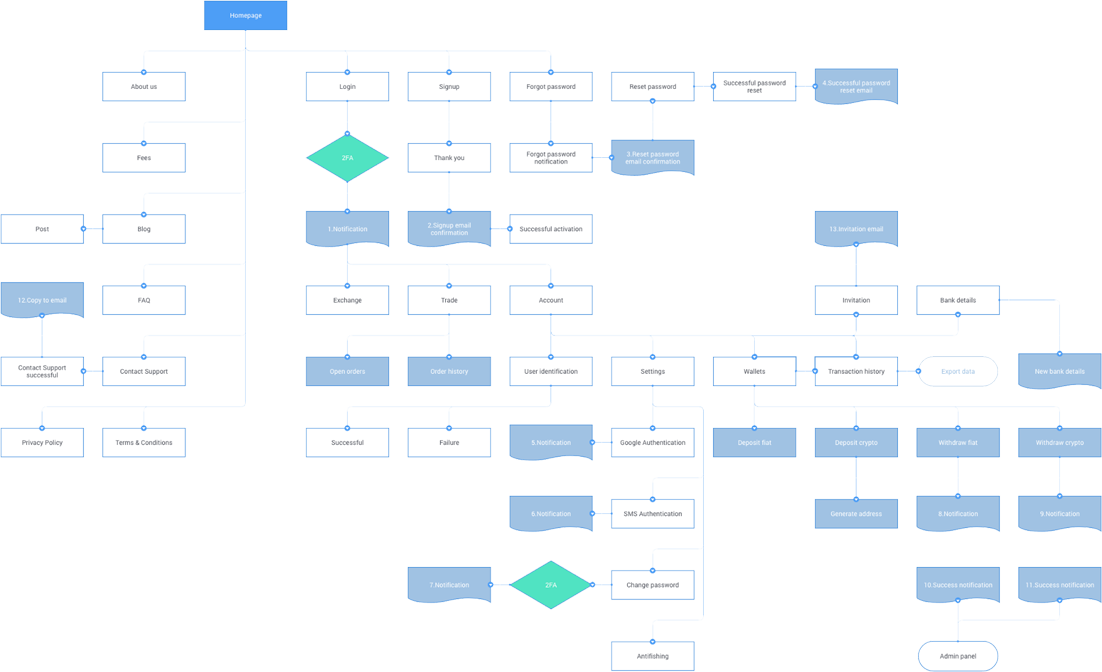
Process
Key process of project launch
The path from an idea to a full-fledged launch and reliable support of your project
Why Merehead?
Trustworthiness and expertise
Merehead has been successfully developing projects
in the fields of DeFi, NFT, crypto exchanges, wallets,
financial and blockchain platforms since 2015.



Reviews
What people say!
Why do our clients trust us?
We approach each project with the utmost responsibility, starting from the very first stage — developing a business idea and platform concept. This approach allows us to accurately identify key needs and lay down a strategically verified technical solution.
Developing digital products is a complex and multifaceted process, often associated with new challenges. Since 2015, we have accumulated extensive experience in creating scalable solutions in the field of blockchain and cryptocurrencies, which allows us to effectively cope with even the most complex tasks.

Results
How do we work
Merehead is a team of experts in developing financial blockchain platforms. We provide comprehensive services: from UX/UI design and smart contract creation to product launch and long-term support.

FAQ
Have questions in mind?
Answers to the most frequently asked questions from our clients

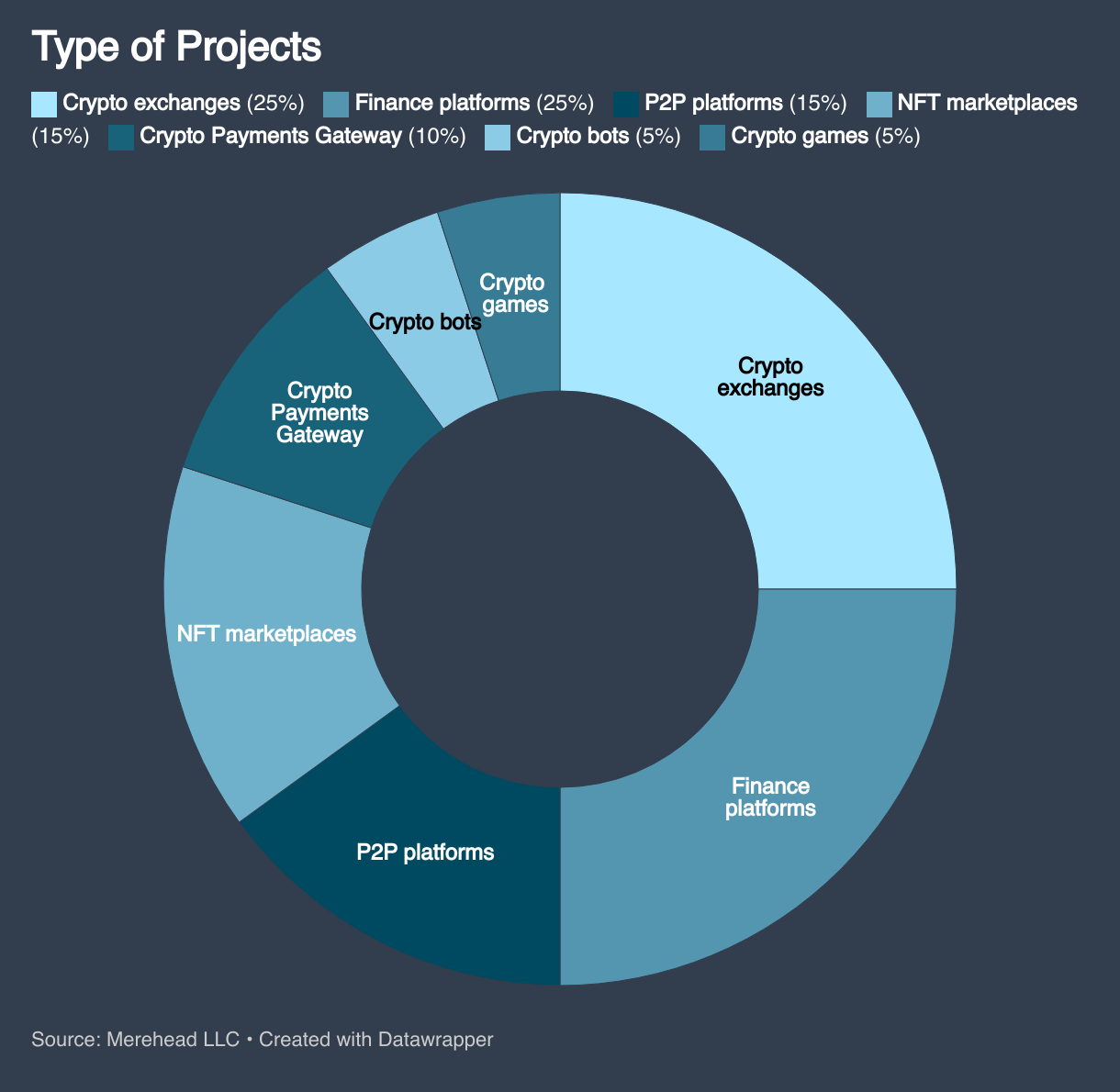
Portfolio
Case studies
Projects developed by our team

The key advantage of the platform is a unique voting mechanism using its own token, allowing holders to receive free coins in new listings.
The team developed a token based on a smart contract, integrated a trading module with automatic order matching, an internal node for deposits and withdrawals.
The key focus is on an advanced graphical system that provides deep technical analysis and intuitive visualization of trading operations. The solution is ideal for traders who prefer working with advanced tools and flexible trading logic.
The platform architecture includes three key modules: the main site, the trader's dashboard and the affiliate program management system with wide customization options. This allows you to effectively work with both private users and partners under the CPA model.
The platform is designed with an eye on scaling and integrating new financial instruments, including futures trading.


One of the key features is the presence of a smart contract factory, which provides automatic generation of a unique contract for each property. This simplifies asset management and increases the level of investment transparency.
The platform includes all the standard functions of the marketplace, as well as tools for managing financial flows, including the collection and distribution of funds. Investors can top up their balance and participate in investment rounds, receiving dividends after the commissioning of properties.
The interface is designed with an emphasis on convenience - an intuitive design and logical structure allow both experienced users and those who are new to investing in tokenized real estate to quickly get used to it.
News & Articles
Latest blog posts
Articles that have recently been added to our blog

