
Non pretendiamo di coprire tutte le sfumature della pianificazione, dello sviluppo e del test delle applicazioni AI, riteniamo che sia gli sviluppatori esperti che i principianti troveranno posizioni utili nelle istruzioni e negli esempi di lunga durata. La gamma di tecnologie applicative basate sull'utilizzo delle reti neurali è enorme: da un bot informatore semplificato ad un'applicazione dotata di funzionalità per la pianificazione del volume delle operazioni commerciali, la consegna, il calcolo e la previsione dei profitti, il controllo dei dipendenti e l'interazione con i clienti. Alcuni esempi di successo di implementazioni di intelligenza artificiale iniziate con un investimento minimo includono Grammarly e Duolingo, i servizi Waze e Canva e l’editor di foto FaceApp.
Panoramica delle aree di applicazione dell'IA
Il funzionamento dell’intelligenza artificiale avviene all’interno del letto di Procuste di diverse regole e categorie, tra cui:- avere GPU potenti, migliaia di gigabyte di dati e RAM da più nodi collegati in rete per addestrare il modello;
- incorporamento dell'Internet delle cose e algoritmi per combinare informazioni provenienti da più livelli in modelli di intelligenza artificiale;
- prevedere eventi, comprendere situazioni paradossali e coordinare sistemi ad alta precisione;
- implementare API per generare nuovi protocolli e modelli di interazione.
Il tipico machine learning ML sostituisce l'operatore all'inizio della comunicazione con il centro di supporto, chiarendo le domande di base. Quando i VCA vengono coinvolti in un formato profondo, le richieste vengono personalizzate e la sicurezza dei contatti aumenta grazie al riconoscimento vocale e allo stato psicologico dei clienti. L'automazione delle attività attuali come la ricerca di biglietti, l'ordinazione di merci, la selezione dei punti di passaggio fa parte delle funzioni degli operatori virtuali. Per questo motivo la scelta tra ML o VCA dipende dalle problematiche da risolvere.
Logistica, valutazione dei clienti e reclutamento
La catena di fornitura e la logistica coordinate dall'intelligenza artificiale semplificano il business mostrando la disponibilità in magazzino degli articoli, indicando le riserve, prevedendo l'efficienza e i periodi di rimborso. Questo è il lavoro di applicazioni e servizi di intelligenza artificiale di alto livello, con prezzi che partono da 100.000 dollari. Il controllo delle voci di ricavo e di spesa e l’identificazione delle tendenze nella segmentazione degli utili sono un esempio di applicazione dell’intelligenza artificiale nel settore finanziario. L'applicazione funziona in modo simile, personalizzando ciascun cliente e analizzando l'efficienza delle vendite: le strategie di promozione sui media migliorano le posizioni di marketing.Le funzionalità PNL dell'intelligenza artificiale forniscono la ricerca iniziale dei dipendenti e l'identificazione delle loro competenze professionali. Nel processo, AI HR raccomanda modifiche alle descrizioni delle mansioni del personale se vede una progressiva assimilazione e automatismo delle competenze, che promuove la crescita della carriera.
Fondamenti: compiti giusti e dati accurati
Le prime due fasi per la pianificazione delle operazioni organizzative e tecnologiche per lo sviluppo di un'applicazione AI sono un programma fondamentalmente valido con diversi passaggi. Il diagramma mostra chiaramente che la prima parte comprende la formulazione del problema, la selezione degli strumenti, le risorse richieste, i costi attesi e i profitti. La seconda fase è responsabile della formazione di database validati e accurati, pronti per l'addestramento del modello.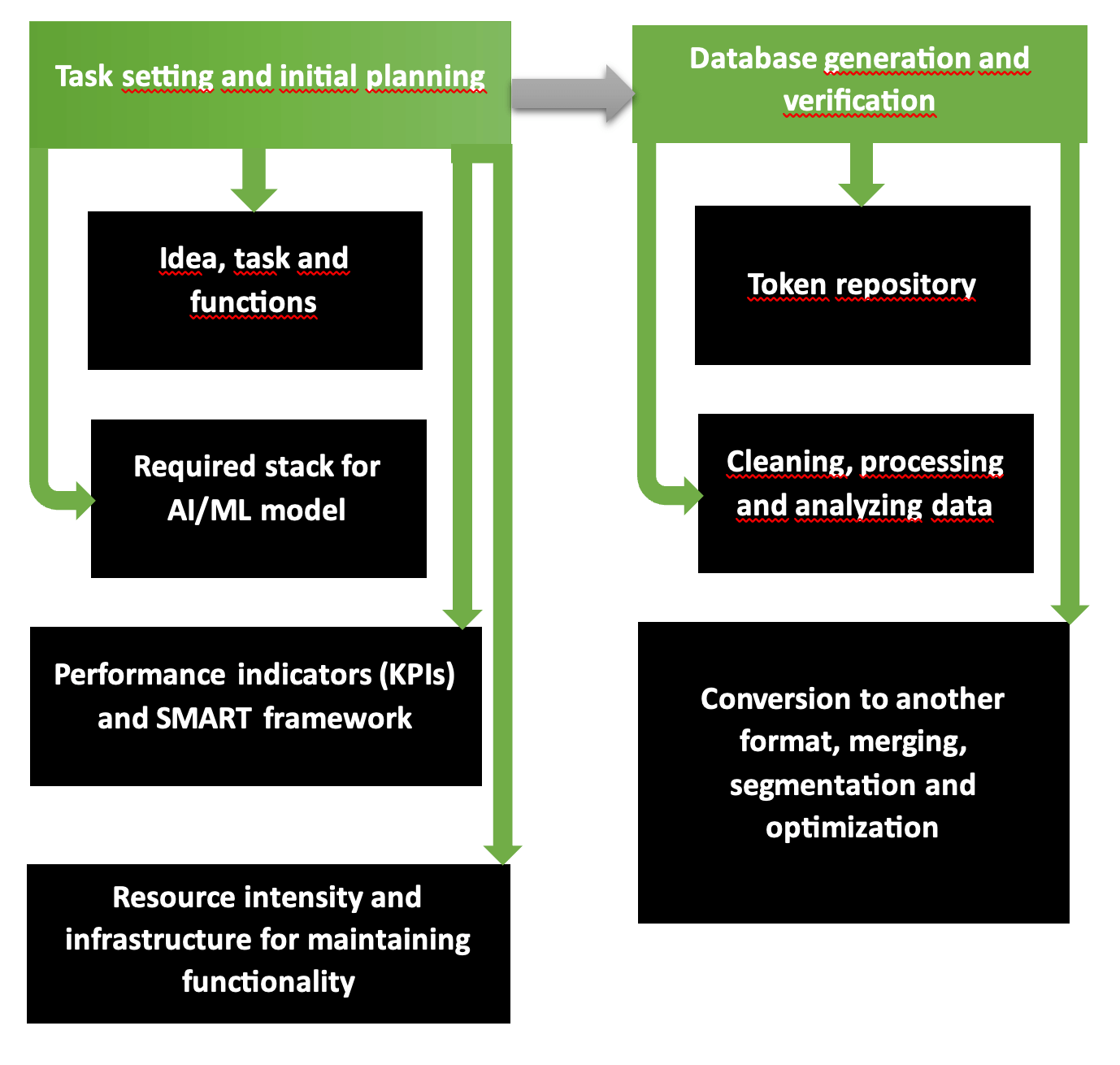
Ecco come inizia a funzionare società di sviluppo AI di applicazioni multipiattaforma. La catena "requisiti - obiettivi - allineamento della visione - stile unificato" è pensata secondo la struttura SMART e categorizzata passo dopo passo in Scrum o Agile. Gli obiettivi e la disponibilità delle risorse determinano quale ambito di servizi e beni può essere fornito nella modalità pianificata e ridotto o ampliato in caso di scarsità o abbondanza di fondi.
Common Crawl, piattaforme come Kaggle o AWS forniscono database di cui è stata verificata l'accuratezza, l'informatività, la ripetizione e il contenuto privo di errori in caso di scarsità digitale e grafica del materiale originale. Per controllare il tuo database, esegui l'utilità Tibco Clarity (lanciata nel 1997) o il software OpenRefine.
Miglioramento costante e soluzioni multimodali
Python è un linguaggio di programmazione popolare, che allo stesso tempo rappresenta la base per la creazione di applicazioni AI grazie alla semplicità dei comandi. I casi degli sviluppatori di prodotti sono pieni di soluzioni AI per Google e Netflix, hosting di video e sito di Streaming. Le applicazioni IA devono essere costantemente migliorate:- addestrarli ad analizzare informazioni sensibili e riservate;
- rimuovere elementi inappropriati e inquietanti dalle foto e dai video generati;
- formare algoritmi con crittografia dei database di clienti e aziende con cui sono stati firmati accordi di collaborazione;
- eseguire il rilevamento di anomalie sulle soluzioni proposte sviluppate dall'intelligenza artificiale.
L’elaborazione modale dei dati del tipo di azione del modello camaleonte avvicina l’intelligenza artificiale al formato esclusivo del paradosso della riflessione umana. L'autoregressione utilizzando il protocollo 34B è stata addestrata su token di dati 10T, quindi il modello multimodale garantisce la generazione di contenuti e immagini con parametri realistici.
4D nel modello PSG4DFormer e sviluppo nel dominio del tempo
L'apprendimento secondo le regole 4D - apprendimento basato sul tempo - interpreta le informazioni (dati, contenuti audiovisivi, video) su una sequenza temporale. Dinamismo 4D è la comprensione dei processi in corso nel tempo. Il modello PSD-4D forma nodi volumetrici sui bordi dei quali si trovano gli oggetti da studiare.Successivamente il modello applicando il database annotato con maschere 4D esegue la segmentazione ed elabora in dettaglio le situazioni entro un certo intervallo temporale. È simile allo storyboard di un film in cui il regista distribuisce scene ed eventi minuto per minuto. Il modello PSG4DFormer prevede la creazione di maschere e il successivo sviluppo su una sequenza temporale. Tali componenti sono la base per generare scene ed eventi futuri.
Test prima dell'avvio
Il test delle applicazioni viene accelerato integrando il pacchetto Python con il framework Django. Gli sviluppatori Python e web, gli ingegneri DevOps utilizzano gli strumenti Django integrati per questo scopo, scrivono casi di test per test unitari e quindi incorporano il pacchetto nel framework.Nella libreria Featuretools, le funzionalità per i modelli ML vengono sviluppate automaticamente: a questo scopo, le variabili vengono selezionate da un database per diventare la base per la matrice di addestramento. I dati in formato orario e provenienti da database relazionali diventano pannelli di formazione durante il processo di generazione.
Librerie, piattaforme e linguaggi sono elementi stack
L'elenco dei framework che migliorano le prestazioni dei modelli AI include la libreria open source TensorFlow e la piattaforma TFX, che accelera l'implementazione di un progetto finito. Questi sono affinati per le immagini. Il modulo PyTorch è scritto in diversi linguaggi, tra cui Python, una versione base di C++ e l'architettura CUDA progettata per processori e schede grafiche NVIDIA.Quando gli ambienti fisici di archiviazione e distribuzione sono scarsi, vengono utilizzate le soluzioni cloud SageMaker, Azure e Google. Julia è uno dei nuovi linguaggi più popolari per la generazione di applicazioni IA: quando si utilizzano comandi scritti in Julia, oltre l'81% dei comandi viene eseguito in modo rapido, accurato e con errori minimi. Anche JavaScript e Python, R mostrano buoni risultati con una precisione superiore al 75%.
Nello stack dell'applicazione aggiungiamo l'ambiente JupyterLab, la libreria NumPy per array multidimensionali o una variante più semplice Pandas. La libreria Dask è progettata per l'analisi di database di grandi dimensioni con cluster, visualizzazione e parallelizzazione, integrazione con ambienti e sistemi per ridurre i costi di manutenzione dell'hardware.
Caratteristiche XGBoost, TensorFlow, FastAPI
XGBoost 2.0 funziona secondo il principio della regressione multivariata e quantile, includendo molte funzionalità nell'albero delle operazioni. La nuova funzionalità include una classificazione migliorata e dimensioni degli istogrammi ottimizzate e l'interfaccia PySpark è diventata più chiara. Se si confronta MXNet e TensorFlow, è meglio scegliere quest'ultima piattaforma per via della migliore capacità di apprendimento, debug e velocità di caricamento dei dati.Le operazioni asincrone e veloci FastAPI rendono il framework preferibile a Django, dove sui server lo standard WSGI deve essere configurato sul nuovo ASGI asincrono. Poiché l'interfaccia ha 6 anni, ha una capacità dati limitata per i token JWT e lo spazio di archiviazione S3. Teniamo conto del fatto che le librerie asincrone spesso hanno problemi con informazioni illeggibili e talvolta dobbiamo eseguire scritture invocandoexecute() dopo aver passato la query SQL e i materiali. Nota: l'attributo root_path non viene modificato in "/api", il che è scomodo.
Containerizzazione, distribuzione e architettura del modello AI
Il processo di containerizzazione viene avviato quando vengono riuniti i componenti per la creazione di un'applicazione AI (codice e librerie con framework). Un contenitore autonomo viene estratto dall'host e trasferito in un altro ambiente senza ricompilazione. Docker Engine e Kubernetes sono i pionieri di questo segmento, il sistema operativo richiesto è Linux (cloud o locale), gli OCI funzionano in modalità lettura, senza modifiche. VMware e LXC sono in questo elenco. Talvolta i contenitori vengono archiviati sulla piattaforma GitHub: soprattutto quando si lavora insieme su un progetto.Gli strumenti di distribuzione includono la piattaforma PaaS proprietaria Heroku, la più sofisticata Elastic Beanstalk e Qovery, che sfrutta il meglio di entrambe le risorse. Per i test, usano:
- Selenium con tre tipi di servizi WebDriver, IDE e Grid;
- Piattaforma PyTest con test scalabili su versioni Python 3.8+ o PyPy3;
- Locust con prove di carico.
| Architettura modello | Compito | Funzioni speciali |
| Convoluzionale (CNN) | Video e immagini | Identificazione accurata, eliminazione di rumore ed errori |
| Ricorrente (RNN) | Dati digitali e linguaggio | Elaborazione della sequenza |
| Conversatorio generale (GAN) | Generazione di nuovi dati e immagini | Simulazione con generazione di nuovi dati, come base per la formazione |
Successivamente, l'addestramento del modello AI viene perfezionato in filigrana. Se lo scenario prevede requisiti elevati con parametri precisi, la formazione continua con l'osservazione: tali condizioni sono più costose. Per trovare artefatti e modelli nel clustering, è preferibile optare per l'autoapprendimento. Per progetti di robotica e semplici gioco su Telegram, rinforzo (incoraggiamento o punizione - il "viene utilizzato il metodo “bastone e carota").
Tempistiche di sviluppo, controllo degli errori
Il costo in termini di tempo per lo sviluppo, il test e l'esecuzione di un modello di intelligenza artificiale assomiglia a quello riportato nel diagramma. L'algoritmo richiede una descrizione accurata dell'esecuzione dell'attività, in modo che il risultato sia una nuova soluzione per l'individuazione dei modelli. La catena “iterazioni-previsioni-correzione” è completata da iperparametri immessi manualmente prima di avviare la convalida incrociata nei sottoinsiemi.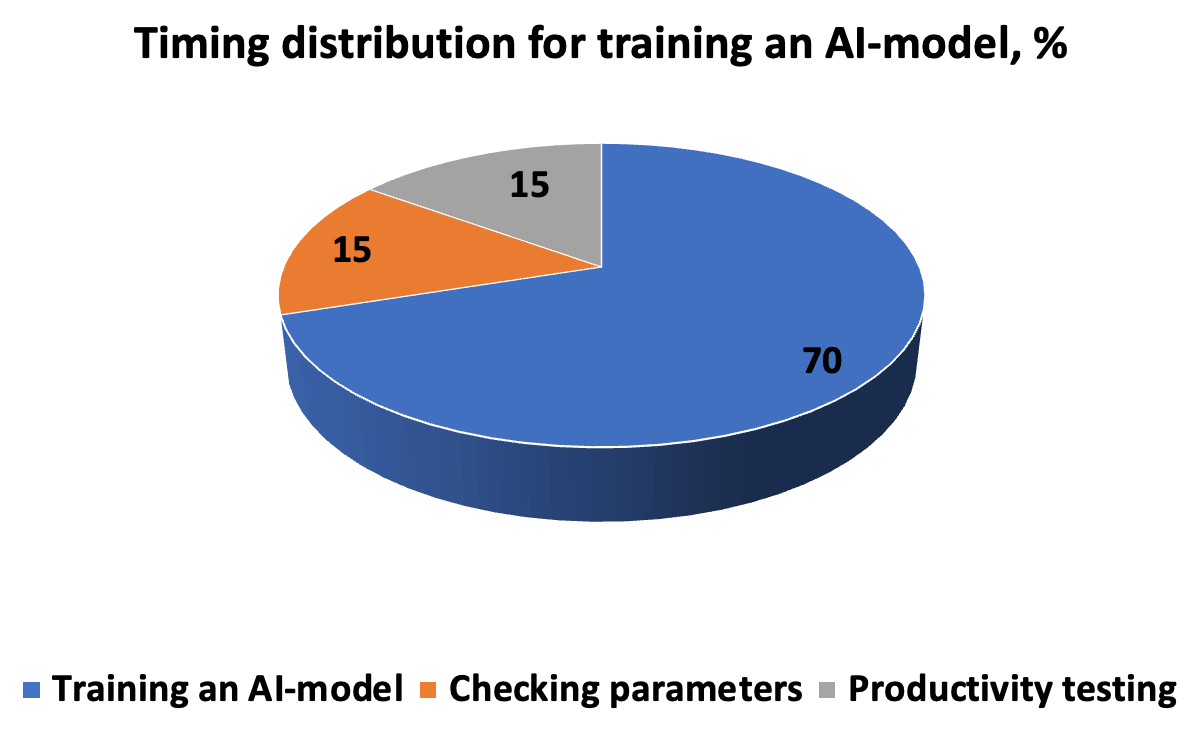
Affinché il modello possa funzionare in modo produttivo negli scenari del mondo reale, dobbiamo valutare la correttezza e la velocità di risposta. Pertanto, i parametri di misurazione includono precisione e ripetibilità, metriche ROC-AUC, dove non è necessario tagliare la soglia (per un database non bilanciato), punteggio F, che specifica la proporzione di soluzioni positive, errore quadratico medio MSE e R- coefficiente quadrato di determinazione. Un errore entro il 5% è considerato accettabile; quando ridotto a 1 e 0,1%, il risultato è considerato altamente accurato.
RAG e personalizzazione, integrazione backend o frontend, test
Il metodo RAG viene utilizzato per sviluppare modelli generativi, in cui vettori e semantica vengono approssimati segmento per segmento in base al contesto e alla rilevanza. La base del RAG è estrarre informazioni da voluminosi database e quindi generarle in un modello per ottenere una risposta accurata. La messa a punto per esperimenti specializzati include la normalizzazione (riduzione a parametri comuni) e, dopo l'adattamento, tokenizzazione. Per rendere produttivo il modello AI, l’integrazione avviene, a seconda dell’attività, nel backend o nel frontend. È meglio integrare il modello linguistico nella parte server e lavorare con i client nell'interfaccia.Nell'IoT, è preferibile il funzionamento periferico del dispositivo in quanto preserva la privacy e fornisce prestazioni veloci. Al centro dell’IoT c’è la generazione di dati, la cui essenza è la convergenza dell’intelligenza artificiale con l’IoT. Questa sinergia rafforza la funzionalità delle due parti, dando vita all’AIoT. Tuttavia, per aumentare la potenza e la scalabilità della funzionalità, è meglio applicare tecnologie basate su cloud utilizzando protocolli API incorporati. Se è importante ascoltare il feedback dei clienti (convenienza, chiarezza, velocità), integriamo una funzione di feedback.
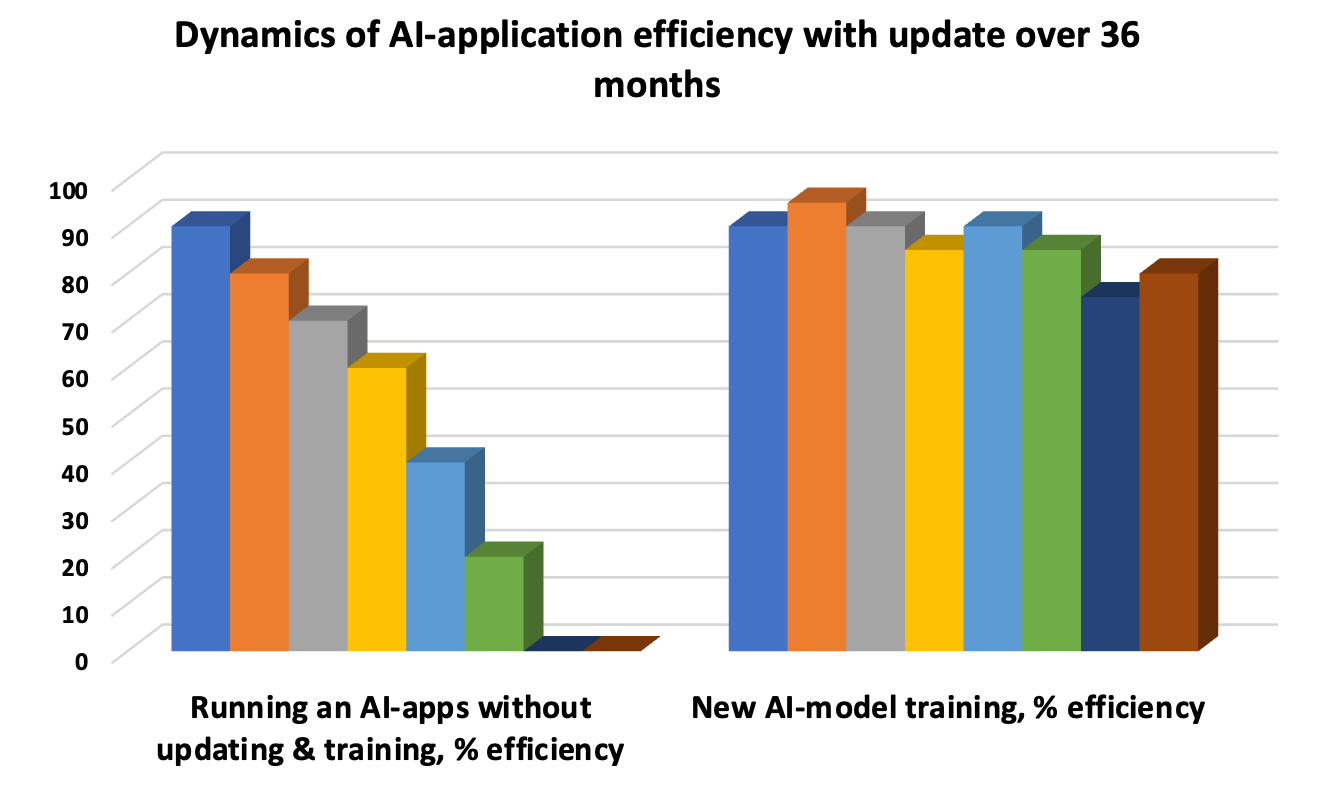
L’aggiornamento del modello di intelligenza artificiale è una necessità per evitare la “deriva” quando i modelli sottostanti diventano obsoleti e l’accuratezza della risposta diminuisce. Pertanto, il test iterativo estende il ciclo di vita del modello. Test unitari automatizzati, test di integrazione periodici per valutare le prestazioni aggregate delle singole funzioni e test di accettazione UAT sono le tre "balene" obbligatorie per la valutazione e il test delle prestazioni.
ZBrain: open source e integrazione perfetta
ZBrain è un esempio di piattaforma elaborata per la simbiosi di processi aziendali e informazioni con funzionalità AI incorporata. Il codice open source con modelli e LLM integrati in memoria fornisce:- archiviazione e scambio di fiat e criptovaluta in coppia, con registrazione delle transazioni basata su blockchain;
- lavoro produttivo su un pannello informativo chiaro e dettagliato;
- gestione di applicazioni multipiattaforma e multipiattaforma in fase micro e macro;
- implementazione di tecnologie cognitive e soluzioni orientate al progetto.
Democratizza e semplifica chiaramente la trasformazione dei processi aziendali quando gli utenti stessi sviluppano e distribuiscono modelli di intelligenza artificiale per logiche e flussi di lavoro di marketing e produzione senza scrivere codice. Ad esempio, la perfetta integrazione di Flow seleziona dinamicamente i dati giusti e prepara soluzioni AI basate su di essi.
Calcolo quantistico: allontanarsi dai colli di bottiglia di Neumann e ridurre i costi energetici
L’informatica quantistica viene utilizzata per elaborare grandi quantità di dati. Gli algoritmi utilizzati nelle tecnologie quantistiche accelerano i processi di apprendimento dell’intelligenza artificiale in medicina, materiali, processi biologici e chimici e riducono le emissioni di CO2 e di gas serra. Per consentire l'apprendimento su miliardi di parametri, sono necessari processori grafici o TPU ultra potenti progettati per eseguire diverse operazioni parallele.Nel frattempo, il problema del collo di bottiglia Neumann (VNB) deve essere superato in modo che il processore non possa aspettare che la RAM fornisca l'accesso al processo. L'obiettivo è aumentare la velocità di recupero e trasferimento dei dati dal database o dall'archivio. Anche l'elevata velocità dei processori multi-core con 32-64 GB o più di RAM potrebbe non giustificare l'investimento in capacità quando il trasferimento di informazioni dal cloud è limitato. Per risolvere il problema VNB, espandono la cache, introducono l'elaborazione multithread, modificano la configurazione del bus, integrano il PC con variabili discrete, utilizzano memristor e computano in un ambiente ottico. Inoltre esiste anche la modellazione in base al principio dei processi biologici come la quantizzazione.
Il paradigma dell’intelligenza artificiale digitale nell’elaborazione parallela aumenta il consumo di energia e il tempo dei processi di apprendimento. Per questo motivo, i qubit in sovrapposizione (posizioni multiple in un periodo di tempo) e in posizioni di entanglement sono preferibili ai bit classici, a condizione che venga preservata la stabilità. Per l’intelligenza artificiale, le tecnologie quantistiche sono migliori grazie ai costi ridotti di sviluppo e analisi dei dati in più configurazioni. La “tensorizzazione” comprime i modelli di intelligenza artificiale e consente l’implementazione su dispositivi semplici, migliorando al tempo stesso la qualità dei dati grezzi.
Regole di difesa informatica
Prestare attenzione alla difesa informatica: gli algoritmi di intelligenza artificiale identificano modelli nelle attività che portano minacce, prevedono potenziali minacce informatiche e proteggono la privacy, che è un imperativo legale ed etico. Le normative GDPR e CCPA, come gli altri protocolli di difesa, devono essere rispettate garantendo:- anonimizzare i clienti e garantire che non vi siano scappatoie per identificarli da parte di terzi;
- differenziare i punti sensibili nei dati del passaporto, e-mail, numeri di telefono e altri documenti che non possono essere divulgati;
- analisi congiunta di segmenti informativi in due o tre sistemi disconnessi, senza rivelare la base completa.
Pattern-avvelenamento (introduzione di elementi dannosi) nell'intelligenza artificiale, la presenza di vulnerabilità avversarie porta a classificazioni errate. Questo è il motivo per cui un approccio olistico dovrebbe includere principi di protezione dalla fase di sviluppo fino al test e all’implementazione per ridurre al minimo le sfide e i rischi.
Il lavoro dell'intelligenza artificiale: esperto e PNL, attraverso algoritmi genetici e creatività
Identificazione delle caratteristiche chiave della formazione sull'intelligenza artificiale nel caso in cui l'obiettivo sia risolvere compiti a livello di esperto, guidati dal ragionamento e dall'analisi di database empirici multimilionari con considerazione visiva di situazioni specifiche. Ad esempio, l’indice di vegetazione NDVI viene utilizzato per determinare il livello di crescita della vegetazione. Ma ci sono delle sfumature: una cosa è quando la vegetazione coltiva cereali o semi oleosi, un'altra quando si tratta di erbacce. L'intelligenza artificiale nell'app dovrebbe essere in grado di distinguere in base al colore ciò che cresce meglio e dare una risposta. Allo stesso modo: riconoscere il tipo di viso, i parametri lineari della figura per consigli sulla scelta di cosmetici o vestiti per gli abiti.Il principio della PNL viene introdotto negli algoritmi durante la pianificazione del lavoro dell'IA come psicologo: viene analizzato il linguaggio naturale e viene chiarito l'umore psico-emotivo del paziente. Quindi alle domande viene data una risposta generata che si avvicina al suono e all'intonazione umana. Esistono anche gli algoritmi genetici, quando si creano bot per risolvere milioni di problemi e poi si eliminano i peggiori, lasciando i migliori. La combinazione di sviluppi di successo e la successiva generazione di nuovi modelli adattati e testati, basati sui predecessori e su una serie di iterazioni, porta ad una soluzione completa del problema.
Lo sviluppo di programmi di intelligenza artificiale dovrebbe essere un approccio creativo. Ad esempio, puoi creare un chatbot sotto forma di un animale o un uccello divertente, un elfo divertente o una pianta vivace o qualcosa di pragmatico come un bot di arbitraggio per il trading. Coloro che leggono Kurt Vonnegut ricordano la storia di un supercomputer che ha acquisito il pensiero umano. Pertanto, se il personaggio darà voce alle battute, utilizzando la comunicazione precedente, fornirà suggerimenti e brevi comunicati stampa sui nuovi prodotti, i clienti adoreranno e si abitueranno all'intelligenza artificiale, si fideranno. La crescita delle vendite sarà almeno del 10-20%.
MVP, CRISP-DM e tariffe
Il primo passo dopo lo sviluppo e l'implementazione dell'intelligenza artificiale in un'applicazione è lanciare un MVP con analisi e supporto, miglioramento delle funzionalità e test permanenti. Se l'azienda prevede di mantenere un'applicazione AI per 10-20 anni, sono necessari aggiornamenti trimestrali regolari dei database, test di diversa tipologia, secondo la metodologia CRISP-DM.Per identificare i costi finanziari e di tempo, contatta Merehead con le tue attività e domande. Quindi, quanto costa creare un'intelligenza artificiale per una semplice app? Il costo di sviluppo dell’intelligenza artificiale parte da $ 20.000 e nel tempo ne richiede fino a un quarto. Il tempo di sviluppo delle applicazioni per applicazioni di media complessità con catene logiche da tre a cinque livelli è doppio e il prezzo raggiunge i 100.000 dollari. Per progetti matematici complicati con analisi di esperti e precisione delle risposte del 99,9% - fino a $ 500.000. Sviluppiamo una roadmap del progetto e pianifichiamo i risultati di redditività attesi prima di iniziare i lavori.


