
Sans prétendre couvrir toutes les nuances de la planification, du développement et du test des applications d’IA, nous pensons que les développeurs expérimentés et les débutants trouveront des positions utiles dans les instructions détaillées et les exemples. La gamme de technologies d'application basées sur l'utilisation des réseaux de neurones est immense: d'un robot informateur simplifié à une application dotée de fonctionnalités pour planifier le volume des opérations commerciales, la livraison, le calcul et la prévision des bénéfices, le contrôle des employés et l'interaction avec les clients. Quelques exemples réussis de mise en œuvre de l'IA qui ont démarré avec un investissement minimal incluent Grammarly et Duolingo, les services Waze et Canva et l'éditeur de photos FaceApp.
Présentation des domaines d'application de l'IA
Le fonctionnement de l’IA s’effectue au sein du lit de Procuste de plusieurs règles et catégories, notamment:- disposer de GPU puissants, de milliers de gigaoctets de données et de RAM provenant de plusieurs nœuds mis en réseau pour entraîner le modèle;
- intégrer l'Internet des objets et des algorithmes pour combiner des informations provenant de plusieurs couches dans des modèles d'IA;
- prédire les événements, comprendre les situations paradoxales et coordonner des systèmes de haute précision;
- implémenter des API pour générer de nouveaux protocoles et modèles d'interaction.
L'apprentissage automatique ML typique remplace l'opérateur au début de la communication avec le centre d'assistance, clarifiant les questions de base. Lorsque les VCA interviennent dans un format approfondi, les demandes sont personnalisées et la sécurité des contacts est accrue grâce à la reconnaissance vocale et à l'état psychologique des clients. L'automatisation des tâches courantes comme la recherche de billets, la commande de marchandises, la sélection de waypoints fait partie des fonctions des opérateurs virtuels. Pour cette raison, le choix du ML ou du VCA dépend des problèmes à résoudre.
Logistique, évaluation client et recrutement
La chaîne d'approvisionnement et la logistique coordonnées par l'IA simplifient les affaires en affichant la disponibilité des stocks d'articles, en indiquant les réserves, en prévoyant l'efficacité et les délais de récupération. C'est l'œuvre d'applications et de services d'IA de haut niveau, dont les prix commencent à 100 000 $. L'audit des éléments de revenus et de dépenses, l'identification des tendances en matière de segmentation des bénéfices sont un exemple d'application de l'IA dans le secteur financier. L'application fonctionne de manière similaire, personnalisant chaque client et analysant l'efficacité des ventes: les stratégies de promotion médiatique améliorent les positions marketing.Les capacités PNL d'AI permettent une recherche initiale d'employés et d'identifier leurs compétences professionnelles. Dans la foulée, AI HR recommande des modifications aux descriptions de poste du personnel si elle constate une assimilation progressive des compétences et une automaticité, ce qui favorise l’évolution de carrière.
Fondation: les bonnes tâches et des données précises
Les deux premières phases de planification des opérations organisationnelles et technologiques pour le développement d’une application d’IA constituent un programme fondamentalement solide comportant plusieurs étapes. Le diagramme montre clairement que la première partie comprend la formulation du problème, la sélection des outils, les ressources requises, les coûts et les bénéfices attendus. La deuxième étape est responsable de la formation de bases de données validées et précises, prêtes pour la formation du modèle.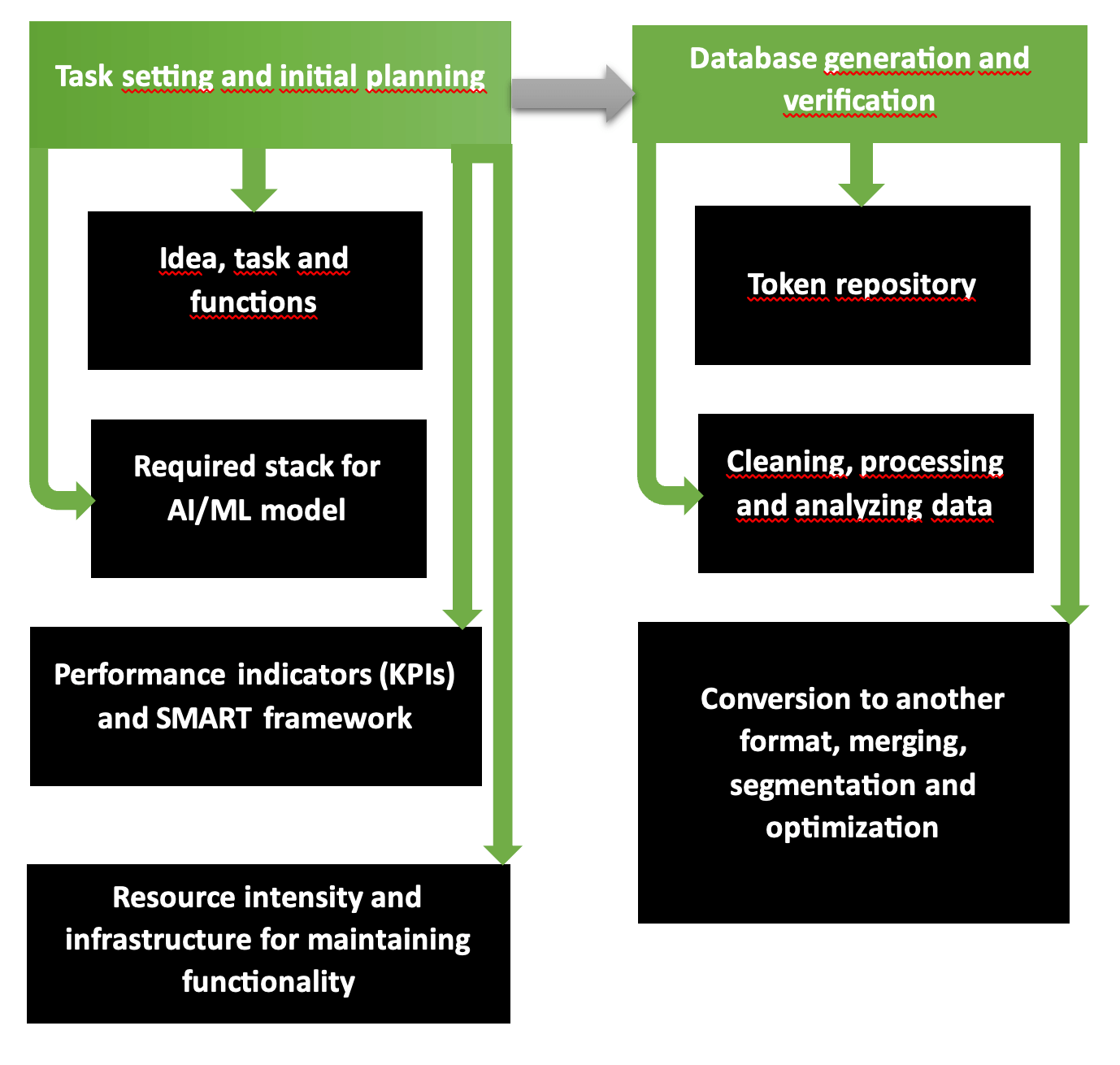
C'est ainsi que la agence intelligence artificielle d'applications multiplateformes commence à fonctionner. La chaîne « exigences – objectifs – alignement vision – style unifié » est pensée selon la structure SMART et catégorisée étape par étape en Scrum ou Agile. Les objectifs et la disponibilité des ressources déterminent l'étendue des services et des biens qui peuvent être fournis selon le mode planifié et réduits ou élargis en cas de pénurie ou d'abondance de fonds.
Common Crawl, des plateformes comme Kaggle ou AWS fournissent des bases de données dont l'exactitude, le caractère informatif, la répétition et le contenu sans erreur ont été vérifiés en cas de pénurie numérique et graphique du matériel source. Pour vérifier votre propre base de données, exécutez l'utilitaire Tibco Clarity (lancé en 1997) ou le logiciel OpenRefine.
Amélioration constante et solutions multimodales
Python est un langage de programmation populaire, qui constitue en même temps la base de la création d'applications d'IA en raison de la simplicité des commandes. Les cas des développeurs de produits regorgent de solutions d'IA pour Google et Netflix, d'hébergement vidéo et plateforme de streaming. Les applications d’IA doivent être constamment améliorées:- les former à analyser les informations sensibles et confidentielles;
- supprimez les éléments inappropriés et effrayants des photos et vidéos générées;
- créer des algorithmes avec chiffrement des bases de données des clients et des entreprises avec lesquelles des accords de coopération ont été signés;
- effectuer une détection des anomalies sur les solutions proposées développées par l'IA.
Le traitement modal des données de type action du modèle caméléon rapproche l’IA du format paradoxal exclusif de la réflexion humaine. L'autorégression utilisant le protocole 34B a été entraînée sur des jetons de données 10T, de sorte que le modèle multimodal garantit la génération de contenu et d'images avec des paramètres réalistes.
4D dans le modèle PSG4DFormer et développement dans le domaine temporel
Apprendre selon les règles 4D - apprentissage basé sur le temps - interprète les informations (données, contenus audiovisuels, vidéo) sur une timeline. Dynamism 4D est la compréhension des processus en cours dans le temps. Le modèle PSD-4D forme des nœuds volumétriques sur les bords desquels se situent les objets à étudier.Ensuite, le modèle en appliquant la base de données annotée avec des masques 4D effectue une segmentation et élabore les situations en détail dans une certaine plage de temps. Ceci est similaire au storyboard d'un film où le réalisateur distribue les scènes et les événements minute par minute. Le modèle PSG4DFormer prédit la création de masques et leur développement ultérieur sur une chronologie. Ces composants constituent la base de la génération de scènes et d'événements futurs.
Test avant le démarrage
Les tests d'applications sont accélérés en intégrant le package Python au framework Django. Les développeurs Python et Web, les ingénieurs DevOps utilisent à cet effet les outils Django intégrés, écrivent des cas de test pour les tests unitaires, puis intègrent le package dans le framework.Dans la bibliothèque Featuretools, les fonctionnalités des modèles ML sont développées automatiquement: à cet effet, les variables sont sélectionnées dans une base de données pour devenir la base de la matrice de formation. Les données au format temporel et issues de bases de données relationnelles deviennent des panneaux de formation lors du processus de génération.
Les bibliothèques, les plateformes et les langages sont des éléments de pile
La liste des frameworks qui améliorent les performances des modèles d'IA comprend la bibliothèque open source TensorFlow et la plateforme TFX, qui accélère le déploiement d'un projet terminé. Ceux-ci sont perfectionnés pour les images. Le module PyTorch est écrit en plusieurs langages, dont Python, une version de base de C++, et l'architecture CUDA conçue pour les processeurs et cartes graphiques NVIDIA.Lorsque les environnements de stockage et de déploiement physiques sont rares, les solutions cloud SageMaker, Azure et Google sont utilisées. Julia est l'un des nouveaux langages les plus populaires pour générer des applications d'IA: lors de l'utilisation de commandes écrites dans Julia, plus de 81 % des commandes sont exécutées rapidement, avec précision et avec un minimum d'erreurs. JavaScript et Python, R affichent également de bons résultats avec une précision de plus de 75 %.
Dans la pile d'applications, nous ajoutons l'environnement JupyterLab, la bibliothèque NumPy pour les tableaux multidimensionnels ou une variante plus simple Pandas. La bibliothèque Dask est conçue pour l'analyse de grandes bases de données avec des clusters, la visualisation et la parallélisation, l'intégration avec des environnements et des systèmes afin de réduire les coûts de maintenance matérielle.
Fonctionnalités XGBoost, TensorFlow, FastAPI
XGBoost 2.0 fonctionne sur le principe de régression multivariée et quantile, incluant de nombreuses fonctionnalités dans l'arbre des opérations. La nouvelle fonctionnalité inclut un classement amélioré et des tailles d'histogramme optimisées, et l'interface PySpark est devenue plus claire. Si vous comparez MXNet et TensorFlow, il est préférable de choisir cette dernière plate-forme en raison de sa meilleure capacité d'apprentissage, de débogage et de vitesse de chargement des données.Les opérations FastAPI asynchrones et rapides rendent le framework préférable à Django, où sur les serveurs, la norme WSGI doit être configurée sur le nouveau ASGI asynchrone. L'interface ayant 6 ans, sa capacité de données est limitée pour les jetons JWT et le stockage S3. Nous tenons compte du fait que les bibliothèques asynchrones ont souvent des problèmes avec des informations illisibles et que nous devons parfois effectuer des écritures en appelant execute() après avoir transmis la requête SQL et les matériaux. Remarque: l'attribut root_path n'est pas remplacé par « /api », ce qui n'est pas pratique.
Conteneurisation, déploiement et architecture de modèle d'IA
Le processus de conteneurisation démarre lorsque les composants permettant de créer une application d'IA sont réunis (code et bibliothèques avec frameworks). Un conteneur autonome est extrait de l'hôte et porté vers un autre environnement sans recompilation. Docker Engine et Kubernetes sont les pionniers de ce segment, l'OS demandé est Linux (cloud ou local), les OCI fonctionnent en lecture, sans modification. VMware et LXC figurent sur cette liste. Les conteneurs sont parfois stockés sur la plateforme GitHub: notamment lorsqu'il y a un travail commun sur un projet.Les outils de déploiement incluent la plate-forme PaaS propriétaire Heroku, Elastic Beanstalk, plus sophistiqué, et Qovery, qui tire le meilleur parti des deux ressources. Pour les tests, ils utilisent:
- Selenium avec trois types de services WebDriver, IDE et Grid;
- Plateforme PyTest avec tests évolutifs sur les versions Python 3.8+ ou PyPy3;
- Criquet avec tests de charge.
| Architecture du modèle | Devoir | Fonctionnalités spéciales |
| Convolutionnel (CNN) | Vidéo et images | Identification précise, élimination du bruit et des erreurs |
| Récurrent (RNN) | Données numériques et langage | Traitement des séquences |
| Conversation générale (GAN) | Générer de nouvelles données et images | Simulation avec génération de nouvelles données, comme bases de formation |
Ensuite, la formation du modèle d’IA est affinée en filigrane. Si le scénario comprend des exigences élevées avec des paramètres précis, la formation se poursuit par l'observation - de telles conditions sont plus coûteuses. Pour retrouver des artefacts et des motifs en clustering, il est préférable d’opter pour l’auto-formation. Pour les projets en robotique et simple jeu en Télégramme, le renforcement (encouragement ou punition - le "méthode de la carotte et du bâton) est utilisée".
Calendrier de développement, vérification des erreurs
Le coût en temps nécessaire au développement, aux tests et à l'exécution d'un modèle d'IA ressemble à ce diagramme. L'algorithme nécessite une description précise de l'exécution des tâches, afin que le résultat soit une nouvelle solution pour la découverte de modèles. La chaîne « itérations-prédictions-correction » est complétée par des hyperparamètres saisis manuellement avant de lancer la validation croisée en sous-ensembles.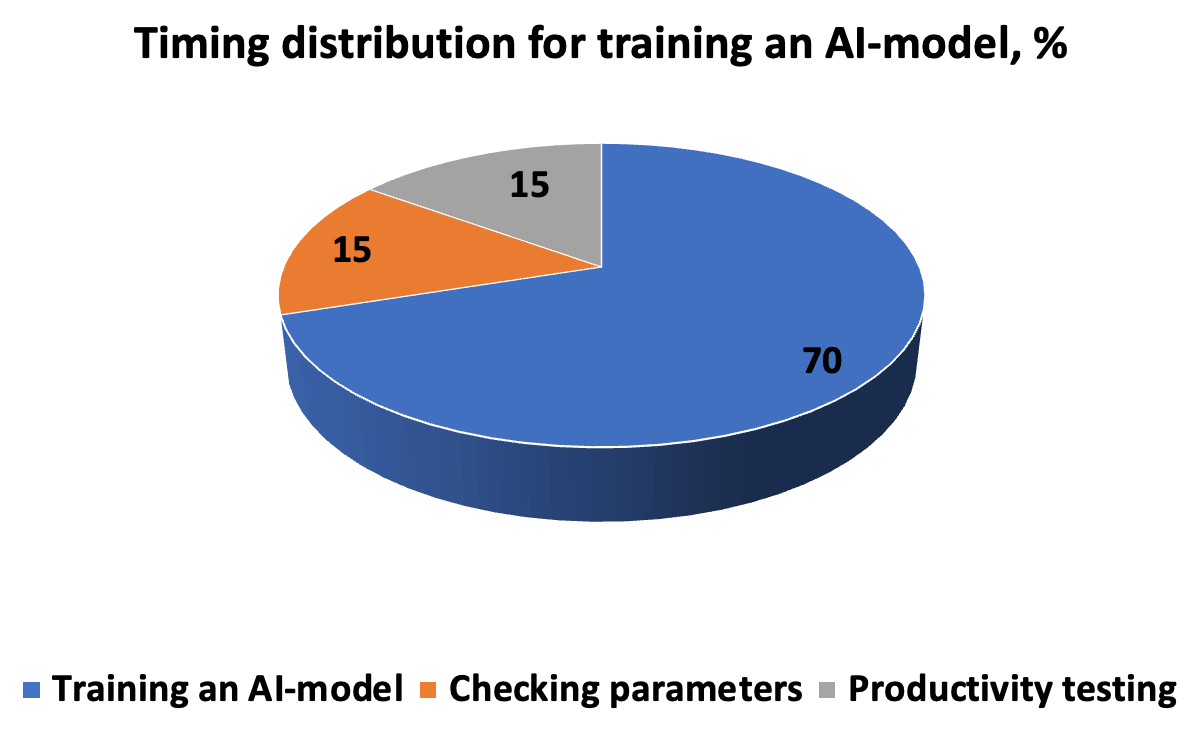
Pour que le modèle fonctionne de manière productive dans des scénarios du monde réel, nous devons évaluer l'exactitude et la rapidité de réponse. Par conséquent, les paramètres de mesure incluent la précision et la répétabilité, les métriques ROC-AUC, où il n'est pas nécessaire de couper le seuil (pour une base de données déséquilibrée), le score F, spécifiant la proportion de solutions positives, l'erreur quadratique moyenne MSE et R- coefficient de détermination au carré. Une erreur inférieure à 5 % est considérée comme acceptable; lorsqu'il est réduit à 1 et 0,1 %, le résultat est considéré comme très précis.
RAG et personnalisation, intégration backend ou frontend, tests
La méthode RAG est utilisée pour développer des modèles génératifs, dans lesquels les vecteurs et la sémantique sont approximés segment par segment en fonction du contexte et de la pertinence. La base de RAG est d’extraire des informations de bases de données volumineuses, puis de les générer dans un modèle pour obtenir une réponse précise. Le réglage fin des expériences spécialisées comprend la normalisation (réduction à des paramètres communs) et, après adaptation, tokenisation. Pour rendre le modèle d'IA productif, l'intégration se fait, selon la tâche, dans le backend ou le frontend. Il est préférable d'intégrer le modèle de langage dans la partie serveur et de travailler avec les clients - dans l'interface.Dans l'IoT, le fonctionnement périphérique sur l'appareil est préféré car il préserve la confidentialité et offre des performances rapides. Au cœur de l’IoT se trouve la génération de données, dont l’essence est la convergence de l’IA avec l’IoT. Cette synergie renforce les fonctionnalités des deux parties, donnant naissance à l'AIoT. Cependant, pour améliorer la puissance et l'évolutivité des fonctionnalités, il est préférable d'appliquer des technologies basées sur le cloud à l'aide de protocoles API intégrés. S'il est important d'entendre les commentaires des clients (commodité, clarté, rapidité), nous intégrons une fonction de feedback.
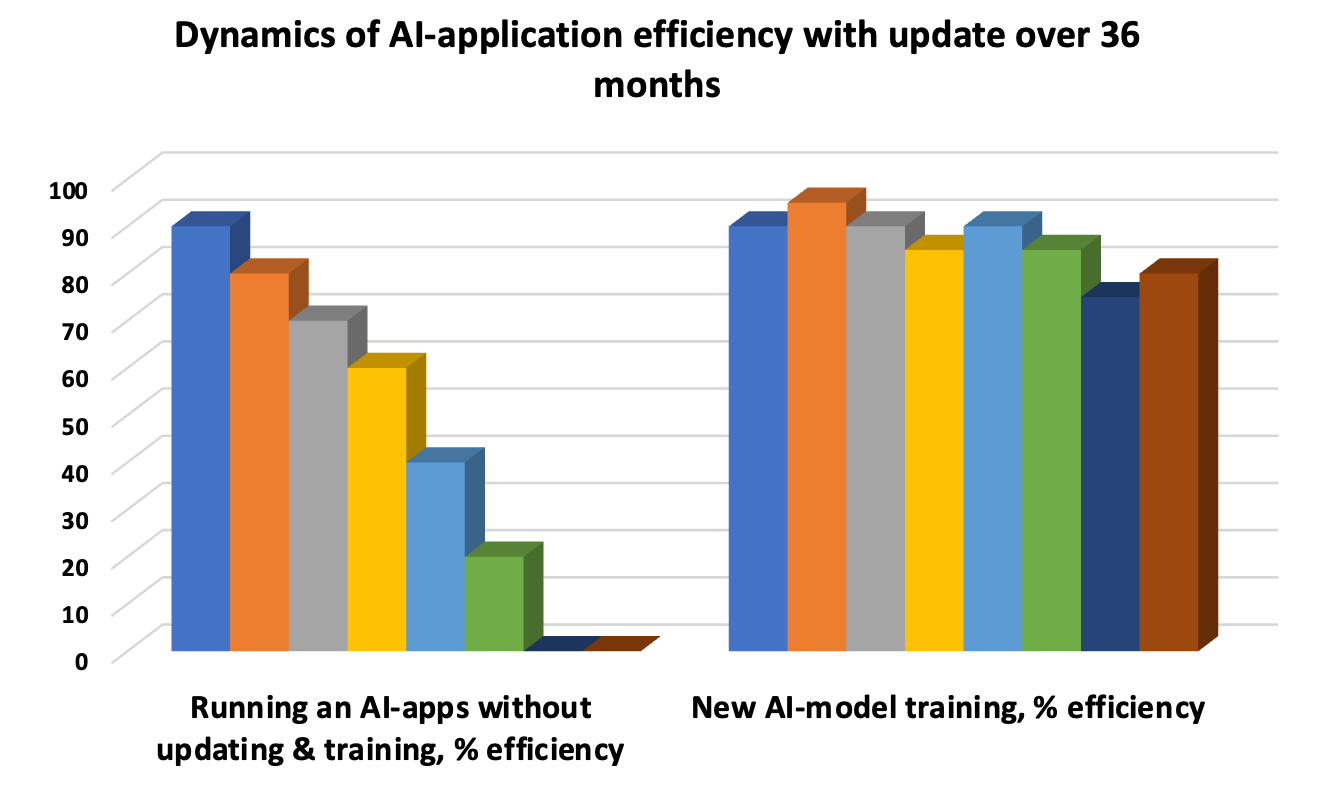
La mise à jour du modèle d’IA est une nécessité pour éviter la « dérive » lorsque les modèles sous-jacents deviennent obsolètes et que la précision de la réponse diminue. Par conséquent, les tests itératifs prolongent le cycle de vie du modèle. Les tests unitaires automatisés, les tests d'intégration périodiques pour évaluer les performances globales des fonctions individuelles et les tests d'acceptation UAT sont les trois «baleines» obligatoires de l'évaluation et des tests de performances.
ZBrain - open source et intégration transparente
ZBrain est un exemple de plate-forme élaborée pour la symbiose des processus et des informations d'entreprise avec des fonctionnalités d'IA intégrées. Le code open source avec des modèles et des LLM intégrés à la mémoire fournissent:- stockage et échange de monnaie fiduciaire et de crypto-monnaie par paires, avec enregistrement des transactions basé sur la blockchain;
- travail productif sur un panneau d'informations clair et détaillé;
- gestion des applications multiplateformes et multiplateformes aux étapes micro et macro;
- mise en œuvre de technologies cognitives et de solutions orientées projet.
Il démocratise et simplifie clairement la transformation des processus métier lorsque les utilisateurs développent et déploient eux-mêmes des modèles d'IA pour la logique et les flux de travail de marketing et de production sans écrire de code. Par exemple, l'intégration transparente de Flow sélectionne dynamiquement les bonnes données et prépare des solutions d'IA basées sur celles-ci.
Informatique quantique: s'affranchir des goulots d'étranglement de Neumann et réduire les coûts énergétiques
L'informatique quantique est utilisée pour traiter de grands ensembles de données. Les algorithmes utilisés dans les technologies quantiques accélèrent les processus d’apprentissage de l’IA dans les domaines de la médecine, des matériaux, des processus biologiques et chimiques, et réduisent les émissions de CO2 et de gaz à effet de serre. Pour permettre l’apprentissage de milliards de paramètres, il faut des processeurs graphiques ou TPU ultra-puissants, conçus pour effectuer plusieurs opérations parallèles.Pendant ce temps, le problème du goulot d'étranglement de Neumann (VNB) doit être surmonté afin que le processeur ne puisse pas attendre que la RAM donne accès au processus. L’objectif est d’augmenter la vitesse de récupération et de transfert des données depuis la base de données ou le stockage. Même la vitesse élevée des processeurs multicœurs dotés de 32 à 64 Go ou plus de RAM peut ne pas justifier l'investissement en capacité lorsque le transfert d'informations depuis le cloud est limité. Pour résoudre le problème du VNB, ils étendent le cache, introduisent un traitement multithread, modifient la configuration du bus, complètent le PC avec des variables discrètes, utilisent des memristors et calculent dans un environnement optique. Par ailleurs, il existe également une modélisation par principe de processus biologiques comme la quantification.
Le paradigme de l'IA numérique dans le traitement parallèle augmente la consommation d'énergie et le temps des processus d'apprentissage. Pour cette raison, les qubits en superpositions (positions multiples dans une même période) et en positions d'intrication sont préférables aux bits classiques, à condition que la stabilité soit préservée. Pour l’IA, les technologies quantiques sont meilleures en raison du coût réduit de développement et d’analyse des données dans plusieurs configurations. La « tensorisation » compresse les modèles d'IA et permet le déploiement sur des appareils simples tout en améliorant la qualité des données brutes.
Règles de cyberdéfense
Faites attention à la cyberdéfense: les algorithmes d'IA identifient les modèles d'activités porteuses de menaces, prédisent les cybermenaces potentielles et protègent la vie privée, ce qui constitue un impératif juridique et éthique. Les réglementations RGPD et CCPA, comme les autres protocoles de défense, doivent être respectées en garantissant:- anonymiser les clients et garantir qu'il n'existe aucune faille permettant à des tiers de les identifier;
- différencier les points sensibles dans les données de passeport, les e-mails, les numéros de téléphone et autres documents qui ne peuvent pas être divulgués;
- Analyse conjointe de segments d'informations dans deux ou trois systèmes déconnectés, sans divulguer la base complète.
L’empoisonnement de modèles (introduction d’éléments malveillants) dans l’IA, la présence de vulnérabilités adverses conduisent à une mauvaise classification. C'est pourquoi une approche holistique doit inclure des principes de protection depuis la phase de développement jusqu'aux tests et au déploiement afin de minimiser les défis et les risques.
Travail d'IA: expert et PNL, par algorithmes génétiques et créativité
Identifier les caractéristiques clés de la formation en IA dans le cas où l'objectif est de résoudre des tâches au niveau expert, guidé par le raisonnement et l'analyse d'une base de données empirique de plusieurs millions de dollars avec une considération visuelle de situations spécifiques. Par exemple, l’indice de végétation NDVI est utilisé pour déterminer le niveau de croissance de la végétation. Mais il y a des nuances: c'est une chose lorsque la végétation produit des céréales ou des oléagineux, et une autre lorsqu'il s'agit de mauvaises herbes. L'IA de l'application devrait être capable de distinguer par couleur ce qui pousse le mieux et de donner une réponse. De même, reconnaissez le type de visage, les paramètres linéaires de la silhouette pour obtenir des recommandations sur le choix des produits cosmétiques ou des vêtements pour les tenues.Le principe de la PNL est introduit dans les algorithmes lors de la planification du travail de l'IA en tant que psychologue: la parole naturelle est analysée et l'humeur psycho-émotionnelle du patient est clarifiée. Ensuite, les questions reçoivent une réponse générée par une réponse proche du son et de l'intonation humains. Il existe également des algorithmes génétiques, lorsque des robots sont créés pour résoudre des millions de problèmes, puis les pires sont supprimés, laissant les meilleurs. La combinaison de développements réussis et de la génération ultérieure de nouveaux modèles adaptés et testés, basés sur les prédécesseurs et un certain nombre d'itérations, conduit à une solution complète du problème.
Le développement de programmes d’IA doit être une approche créative. Par exemple, vous pouvez créer un chatbot sous la forme d'un animal ou d'un oiseau amusant, d'un elfe amusant ou d'une plante spirituelle, ou de quelque chose de pragmatique comme un bot d'arbitrage pour le trading. Ceux qui lisent Kurt Vonnegut se souviennent de l'histoire d'un superordinateur qui a acquis la pensée humaine. Par conséquent, si le personnage exprime des lignes, en utilisant la communication précédente, donne des conseils et de courts communiqués de presse sur les nouveaux produits, les clients adoreront et s'habitueront à l'IA et feront confiance. La croissance des ventes sera d'au moins 10 à 20%.
MVP, CRISP-DM et tarifs
La première étape après le développement et la mise en œuvre de l'IA dans une application consiste à lancer un MVP avec analyse et support, amélioration des fonctionnalités et tests permanents. Si l'entreprise envisage de maintenir une application d'IA pendant 10 à 20 ans, des mises à jour trimestrielles régulières des bases de données et des tests par différents types, selon la méthodologie CRISP-DM, sont nécessaires.Pour identifier les coûts financiers et temporels, contactez Merehead avec votre tâche et vos questions: Coût de développement de l'IA commence à partir de 20 000$ et prend jusqu'à un quart en termes de temps. Le temps de développement d'applications pour des applications de complexité moyenne avec des chaînes logiques de trois à cinq niveaux est deux fois plus long et le prix atteint 100 000$. Pour des projets mathématiques complexes avec une analyse experte et une précision des réponses de 99,9% - jusqu'à 500 000$. Développons une feuille de route du projet et planifions les résultats de rentabilité attendus avant de commencer les travaux.


