
Виникнення нових технологій стимулює зростання у всіх сферах IT, зокрема - машинному навчанні. Розробники проводять великий обсяг роботи, щоб створити приблизний прогноз тенденцій глибокого навчання і нейронних мереж на 2024 рік.
Той, хто свідомо розуміє тренди нейронних мереж і глибокого навчання у 2024 році, випереджає своїх конкурентів на кілька кроків уперед. Це дає можливість створювати проект з урахуванням перспектив і майбутнього машинного навчання, щоб відповідати стандартам цієї сфери.
Команда Merehead також провела власний аналіз, і надала вам найбільш точні результати. Продовжуйте читати цю статтю, щоб підготуватися до нових наративів і зробити 2024 рік найкращим у вашій кар'єрі.
Що таке глибоке навчання?
Глибоке навчання - це галузь машинного навчання, у якій нейронні мережі та алгоритми, створені на основі людського мозку, навчаються за допомогою великих обсягів даних.
Подібно до того, як ми вчимося на власному досвіді, алгоритм глибокого навчання багаторазово виконує задачу, щоразу трохи підправляючи її для поліпшення результату.
Моделі глибокого навчання успішно вирішують такі завдання, як:
- розпізнавання зображень і мови
- обробка природної мови
- системи рекомендацій
Серед уже відомих архітектур глибокого навчання можна відзначити згорткові нейронні мережі (CNN) для аналізу зображень, рекурентні нейронні мережі (RNN) для послідовного опрацювання даних і трансформаторні моделі для розуміння природної мови.
Тенденції глибокого навчання у 2024 році можуть збільшити кількість значних досягнень і проривів, зумовлених наявністю великих масивів даних, обчислювальних ресурсів і вдосконалених алгоритмів.
Як формувалися тренди глибокого навчання?
Розуміння того, як формувалися тренди глибокого навчання в минулому, може дати нам краще уявлення про те, що ми можемо очікувати від цієї сфери в майбутньому. Спеціально для цього наша команда провела детальний аналіз, щоб якомога точніше спрогнозувати ситуацію у 2024 році.

Головні тренди глибокого навчання у 2023 році.
Тенденції розвитку глибокого навчання формувалися під впливом цілої низки факторів, включаючи:
- Доступність великих масивів даних. Наявність великомасштабних помічених наборів даних, таких як ImageNet для комп'ютерного зору або Common Crawl для опрацювання природної мови, стала вирішальним фактором для навчання моделей глибокого навчання.
- Збільшення обчислювальної потужності. Наявність високопродуктивних графічних процесорів (GPU) і спеціалізованого обладнання, такого як TPU (Tensor Processing Units), дала змогу дослідникам і практикам навчати моделі глибокого навчання у більших масштабах і швидшими темпами.
- Пошук нейронної архітектури. Алгоритми NAS у поєднанні з обчислювальними ресурсами дали змогу дослідникам автоматично знаходити нові та оптимізовані мережеві архітектури для розв'язання відповідних задач .
Ці фактори сприяли швидкому зростанню і розвитку напрямків глибокого навчання. Це призвело до прориву в таких задачах, як розпізнавання зображень і мови, розуміння природної мови, генеративне моделювання і навчання з підкріпленням.
Тренди глибокого навчання та нейронних мереж у 2024
У цьому розділі ви знайдете найвірогідніші тенденції глибокого навчання та нейронних мереж у 2024 році, дотримуючись яких зможете поліпшити процес машинного навчання загалом. Дочитайте цю статтю до кінця, щоб побудувати вектор розробки в ШІ найближчим часом.
Досягнення в галузі проєктування архітектур
У 2024 році можна очікувати продовження пошуку нових архітектур нейронних мереж. Дослідники зосередяться на розробленні архітектур, що вирішують такі конкретні задачі, як:
- підвищення ефективності використання пам'яті
- поліпшення роботи з послідовними даними
- підвищення інтерпретованості
Ці дослідження можуть призвести до відкриття нових архітектур, що перевершують наявні моделі в різних галузях і задачах.

Базова архітектура моделей глибокого навчання. Джерело.
{kind=link}
Зі зростанням складності моделей глибокого навчання дедалі більшу увагу приділятимуть розробленню більш ефективних архітектур, які можна масштабувати. Дослідники прагнутимуть знизити обчислювальні вимоги та обсяг пам'яті моделей без шкоди для їхньої продуктивності.
Це дасть змогу розгортати моделі глибокого навчання на пристроях з обмеженими ресурсами, у прикордонних обчислювальних середовищах і великомасштабних розподілених системах.
Покращення інтерпретованості та зрозумілості
У міру ускладнення моделей глибокого навчання, розуміння та інтерпретація їхніх процесів набувають вирішального значення. У 2024 році буде докладено зусиль для розроблення таких методів, як:
- візуалізація та пояснення внутрішніх уявлень глибокого навчання
- важливість ознак і меж прийняття рішень
Ці методи зможуть підвищити інтерпретованість моделей глибокого навчання, а також забезпечать більш ефективні способи взаємодії розробників з технологією.

Пояснюваність моделі порівняно з її продуктивністю. Джерело.
{kind=link}
Етичні міркування та нормативні вимоги визначатимуть інтеграцію пояснюваності в систему глибокого навчання. Дослідники працюватимуть над створенням фреймворків і методологій, що дають змогу моделям давати пояснення або обґрунтування своїх прогнозів.
Це допоможе підвищити довіру і прозорість систем глибокого навчання, особливо в таких критично важливих галузях, як охорона здоров'я, фінанси та автономні системи.
Інтеграція глибокого навчання з іншими технологіями
Моделі глибокого навчання будуть все частіше поєднуватися з технологіями AR і VR для створення імерсивного досвіду та інтелектуальних віртуальних середовищ. Ця інтеграція дасть змогу створювати такі додатки, як:
- розпізнавання і відстеження об'єктів у реальному часі
- розуміння того, що відбувається, і взаємодія з урахуванням контексту в AR і VR
Об'єднання глибокого навчання і блокчейна також набиратиме обертів у 2024 році. Цьому сприяє активний процес регуляції блокчейна в традиційний сектор фінансів, медицини, поставок тощо.
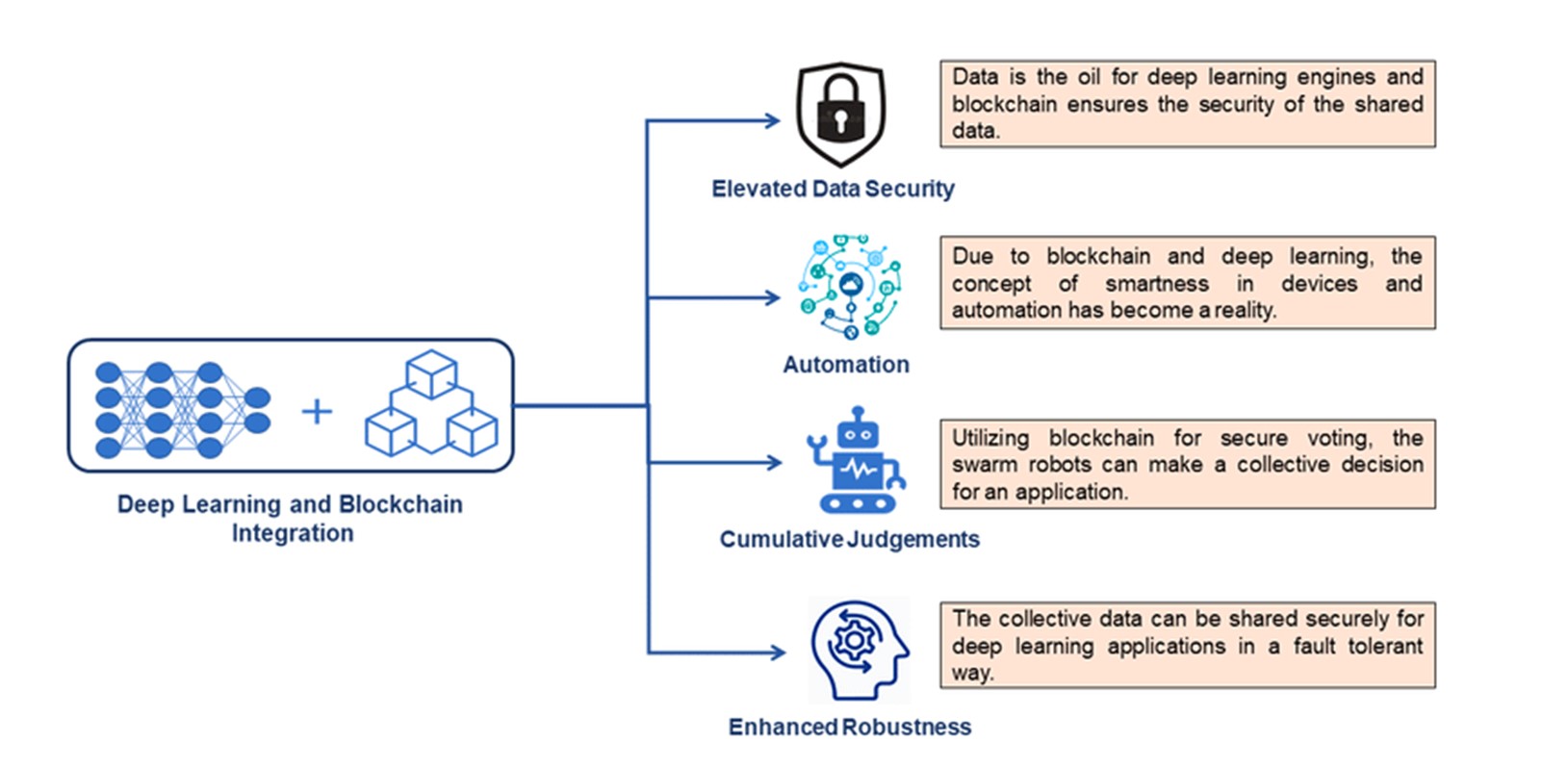
Переваги інтеграції глибокого навчання та блокчейну. Джерело.
Технологія блокчейн надасть інженерам глибокого навчання такі переваги, як:
- децентралізація
- безпечний обмін і зберігання даних
- прозорість і конфіденційність
Інтеграція дасть змогу використовувати спільні моделі глибокого навчання, федеративні підходи до навчання і стимулювати обмін даними, зберігаючи при цьому приватність і право власності.
Розширення можливостей обробки природної мови
У 2024 році обробка природної мови продовжить розвиватися, причому основна увага приділятиметься вдосконаленню моделей розуміння мови та її генерації. Це включає в себе:
- поліпшення розуміння контексту
- більш точне вловлювання нюансів і тонкощів мови
- розробку моделей, здатних генерувати більш зв'язний і контекстуально релевантний текст
Моделі глибокого навчання вдосконалюватимуться для поліпшення можливостей аналізу настроїв, що дасть змогу точніше розуміти емоції, думки та наміри, виражені в тексті.
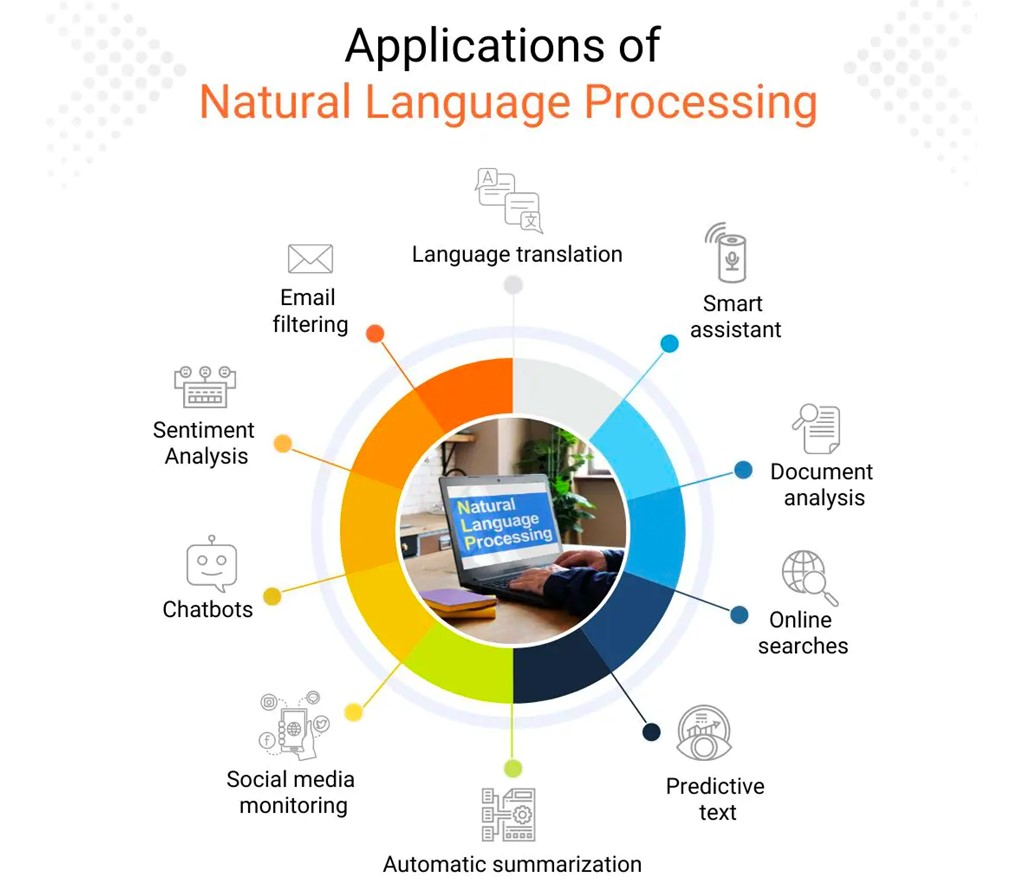
Додатки обробки природної мови. Джерело.
{kind=link}
Крім того, буде докладено зусиль для поліпшення здатності моделей розуміти контекст у розмові, що дасть змогу створювати досконаліші чат-боти, діалогові системи та мовні асистенти.
Підвищена увага до етичних аспектів
У міру поширення технологій глибокого навчання дедалі більша увага приділятиметься розробці та впровадженню етичних принципів і правил. Це включатиме в себе:
- міркування справедливості
- прозорість
- регуляцію
- зменшення упередженості в моделях і додатках глибокого навчання
Дослідники і практики будуть прагнути до зниження упередженості та забезпечення справедливості в моделях глибокого навчання. Буде докладено зусиль для розроблення методів, що дають змогу виявляти й усувати упередженість у навчальних даних, інтерпретувати рішення моделі та забезпечувати справедливі результати для різних демографічних груп.
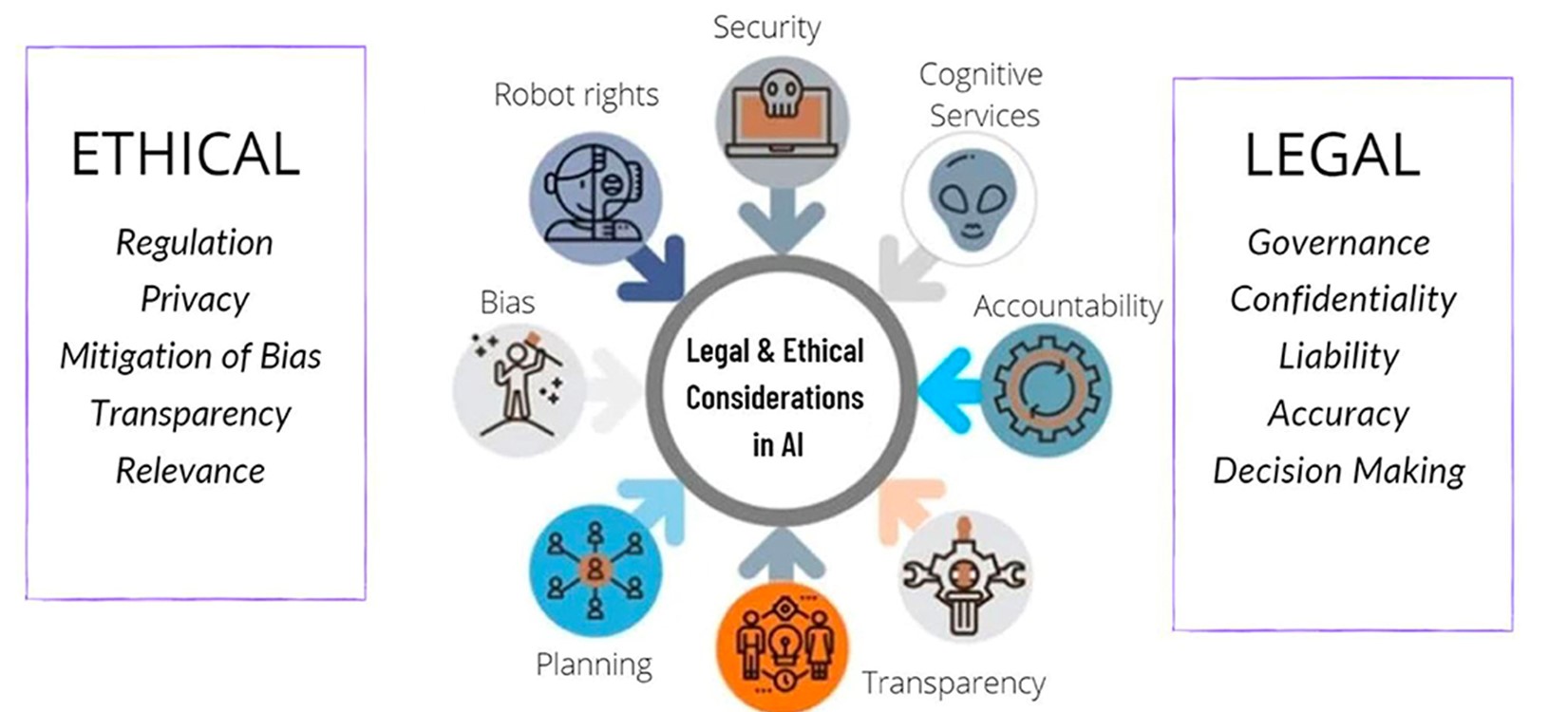
Етичні аспекти застосування штучного інтелекту в охороні здоров'я. Джерело.
{kind=link}
Це матиме вирішальне значення в таких галузях, як:
- фінанси
- кримінальне правосуддя
- охорона здоров'я
А також у всіх сферах, де необ'єктивні рішення можуть мати значні наслідки для суспільства.
Інтеграція гібридних моделей
Інтеграція гібридних моделей - це процес об'єднання різних типів, моделей та архітектур глибокого навчання для використання їхніх індивідуальних переваг і підвищення загальної продуктивності.
Подібні тенденції глибокого навчання у 2024 році сприяють масштабуванню, популярності та створенню більш ефективних підходів у цій галузі. Гібридні моделі доповнюють одна одну для вирішення складних завдань і досягнення кращих результатів.

Архітектура мультимодальної гібридної глибокої нейронної мережі. Джерело.
{kind=link}
Розглянемо кілька прикладів інтеграції гібридних моделей у глибокому навчанні:
- Додавання моделей. Цей підхід передбачає навчання декількох моделей глибокого навчання незалежно одна від одної і подальше об'єднання їхніх результатів у вигляді кластера. Кожна модель може мати різну архітектуру або бути навчена на різних підмножинах даних.
- Попередньо навчені моделі та тонке налаштування. Ці моделі мають загальні візуальні характеристики, які можуть бути перенесені на нове завдання. Тонке налаштування або їхня адаптація дає змогу ефективно використовувати вивчені уявлення і прискорити збіжність.
- Об'єднання архітектур. Різні архітектури глибокого навчання можуть бути об'єднані для використання їхніх унікальних характеристик. Наприклад, об'єднання рекурентної нейронної мережі (RNN) і згорткової нейронної мережі (CNN) дає змогу моделі вловлювати просторові та часові залежності в послідовних даних.
Інтеграція гібридних моделей у глибокому навчанні вимагає ретельного врахування поставленої задачі, характеристик наявних моделей, а також ресурсів і обмежень системи.
Часто доводиться проводити експерименти і тонке налаштування, щоб знайти оптимальне поєднання моделей і методів, що дають змогу ефективно розв'язати конкретне завдання і підвищити продуктивність.
Глибоке навчання на основі нейронауки
Глибоке навчання на основі нейронауки - це тип ML, у якому для навчання штучних нейронних мереж використовуються дані нейронаукових експериментів. Це дає змогу дослідникам розробляти моделі, які засновані на роботі людського мозку.
Вона передбачає використання принципів і концепцій, заснованих на вивченні мозку і нейронних систем, для поліпшення архітектури, алгоритмів і загальної продуктивності моделей глибокого навчання.
Розглянемо кілька ключових аспектів глибокого навчання на основі нейронауки:
- Архітектура нейронних мереж. Технологія спрямована на розробку архітектур нейронних мереж, які відображають різні структури зв'язків, що спостерігаються в мозку. Наприклад, конволюційні нейронні мережі натхненні ієрархічним опрацюванням даних у зоровій корі, а рекурентні нейронні мережі - рекурентними зв'язками в мозку.
- Алгоритми навчання. Нейронаука дає уявлення про те, як мозок навчається і обробляє інформацію. Включаючи ці принципи в алгоритми глибокого навчання, дослідники прагнуть підвищити його ефективність.
- Когнітивні та поведінкові аспекти. Розуміння того, як мозок сприймає, обробляє і взаємодіє з навколишнім середовищем, може допомогти в розробці моделей глибокого навчання для таких завдань, як розпізнавання образів, розуміння природної мови або навчання з підкріпленням.
Глибоке навчання на основі нейронауки - це міждисциплінарна галузь, яка долає розрив між нейронаукою і глибоким навчанням.
Використовуючи досягнення нейронауки, дослідники прагнуть розробити більш біологічно обґрунтовані, ефективні, інтерпретовані та людиноподібні моделі глибокого навчання.
ViT
Vision Transformer (ViT) - це архітектура глибокого навчання, яка застосовує модель Transformer, спочатку створену для завдань обробки природної мови. Вона являє собою відхід від традиційних згорткових нейронних мереж, оскільки використовує механізми самоспостереження для вловлювання далеких залежностей і контекстної інформації в зображеннях.
Основна ідея цієї архітектури полягає в тому, щоб розглядати зображення як послідовність патчів і застосовувати модель Transformer для їх обробки.
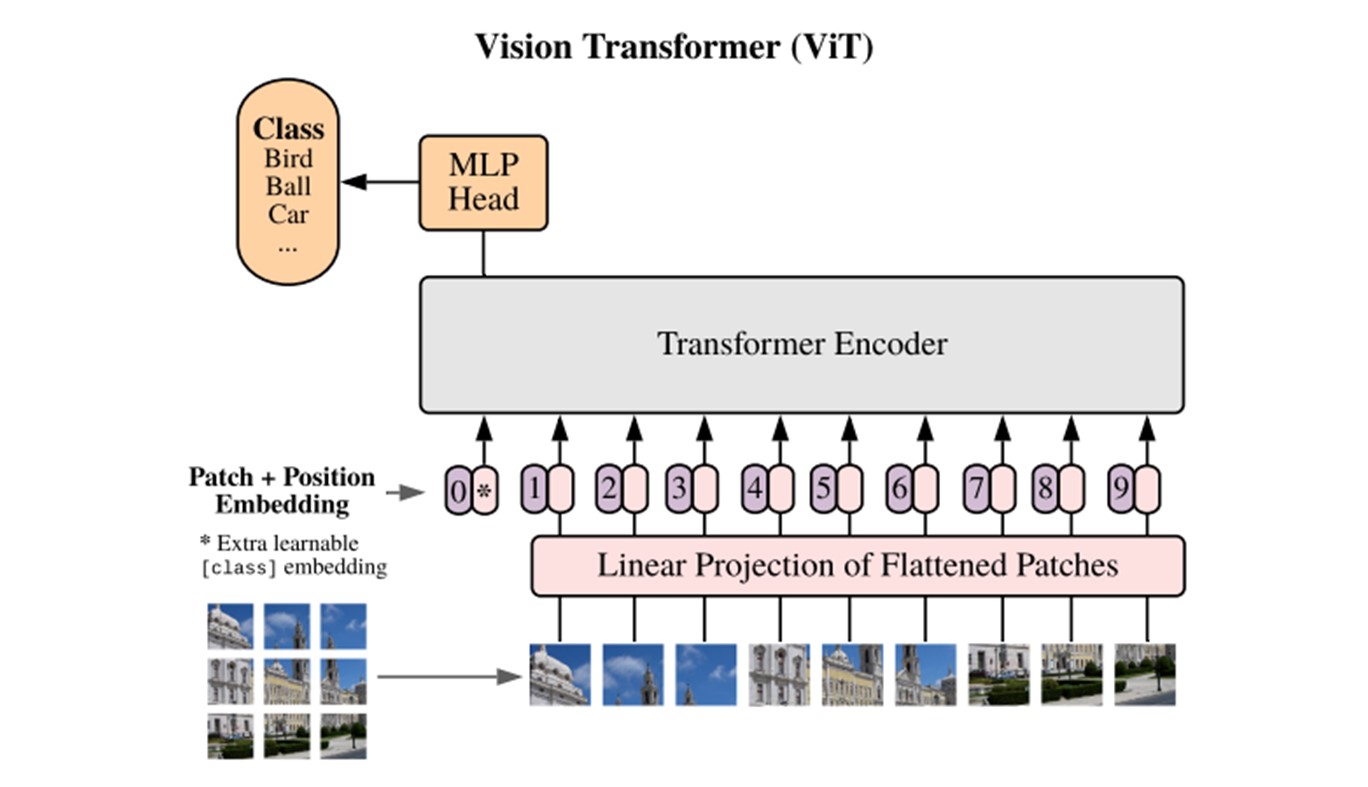
Пояснення Vision Transformer. Джерело.
{kind=link}
Нижче наведено базові компоненти архітектури ViT:
- Інтегрування патчів. Вхідне зображення розбивається на сітку патчів фіксованого розміру, що не перетинаються. Потім кожен патч лінійно проєктується на вектор вбудовування, що має меншу розмірність. Це дає змогу моделі обробляти зображення як послідовність вкраплень.
- Позиційне кодування. Позиційне кодування являє собою відносне або абсолютне положення кожного фрагмента на зображенні, що дозволяє моделі розуміти просторові відносини між ними.
- Трансформаторний кодер. Вкраплення патчів разом із позиційним кодуванням надходять у стек шарів трансформаторного кодера. Кожен його шар складається з багатоголових механізмів самонавіювання та нейронних мереж із прямолінійним рухом. Це дає змогу відвідувати різні ділянки зображення і вловлювати залежності по всьому простору.
Vision Transformer показав чудову продуктивність у низці завдань комп'ютерного зору, включно з класифікацією та сегментацією зображень, а також виявленням об'єктів.
Як і тренди нейронних мереж у 2024 році, подібні архітектури глибокого навчання можуть значно прискорити розвиток нових IT-рішень. Якщо ви хочете створити технологічний продукт, використовуючи глибоке навчання, Merehead - ваш найкращий вибір!
Самоконтрольоване навчання
Самоконтрольоване навчання - це парадигма, за якої модель навчається витягувати значущі уявлення або ознаки з немаркованих даних без необхідності в явних мітках, що надаються людиною.
На відміну від контрольованого навчання, в якому моделі навчаються на позначених даних, що містять "справжні" анотації, самоконтрольоване навчання використовує внутрішню структуру. За допомогою немаркованих даних, модель вчиться вловлювати високорівневу семантичну інформацію і корисні уявлення, які можуть бути перенесені в наступні завдання.

Принцип роботи самоконтрольованого забезпечення. Джерело.
{kind=link}
Процес самонавчання зазвичай включає такі етапи:
Попереднє навчання. У процесі попереднього навчання, модель вчиться витягувати з вхідних даних значущі уявлення або ознаки, намагаючись вирішити допоміжне завдання.
Тонке налаштування. Тонке налаштування дає змогу моделі адаптувати і спеціалізувати отримані уявлення до конкретного завдання. Цей етап допомагає перенести знання, отримані під час самоконтрольованого навчання, на вирішення конкретного задачі.
Самоконтрольоване навчання привертає значну увагу і має успіх у різних галузях глибокого навчання, включно з:
- комп'ютерний зір
- оброблення природної мови
- розпізнавання мови
До основних переваг самоконтрольованого навчання належить можливість використання великих обсягів немаркованих даних, що знижує залежність від дорогих і трудомістких зусиль з маркування.
Крім того, самонавчання сприяє формуванню надійних уявлень, які відображають релевантну інформацію з розподілу даних. Це призводить до підвищення продуктивності під час вирішення подальших завдань.
Високоефективні моделі NLP
Високоефективні моделі NLP - це просунута модель, яку розроблено для досягнення сучасної продуктивності під час розв'язання різноманітних завдань обробки природної мови.
Команда Merehead підготувала список найкращих високопродуктивних моделей NLP, які зможуть задати тенденції глибокого навчання у 2024 році. Серед них:
- Моделі на основі трансформаторів. Трансформаторні моделі, такі як "Transformer" і його різновиди, як-от BERT, GPT і RoBERTa, значно просунулися в галузі NLP.
- Попередньо навчені мовні моделі. Такі моделі, як GPT, BERT і XLNet, попередньо навчаються на величезних обсягах текстових даних за допомогою підходів, заснованих на неконтрольованому або самоконтрольованому навчанні. Вони забезпечують глибоке розуміння мови і можуть бути тонко налаштовані для вирішення конкретних задач NLP.
- Конволюційні нейронні мережі (CNN). Такі моделі, як CNN Кіма і CNN Юн Кіма, використовують конволюційні операції для вловлювання локальних і композиційних ознак тексту, досягаючи конкурентоспроможної продуктивності в таких завданнях, як класифікація текстів і аналіз настрою.
Навчання моделям глибокого навчання у 2024 році в цій галузі вимагає значних обчислювальних ресурсів, включно з потужними графічними процесорами або спеціалізованим обладнанням, наприклад TPU.
Як правило, вони навчаються на великих наборах даних, як маркованих, так і немаркованих, щоб вловити різноманітні мовні патерни і домогтися кращого узагальнення.
Глибоке навчання Системи 2
У 2019 році на конференції з систем обробки нейронної інформації (NeurIPS 2019) Йошуа Бенжіо, один із трьохпіонерів глибокого навчання, виступив із програмною промовою, яка пролила світло на можливий перехід глибокого навчання Системи 1 до Системи 2.

Дві системи мислення. Джерело.
Терміни "Система 1" і "Система 2" були популяризовані психологом Деніелом Канеманом у його книжці 2011 року "Мислення, швидке і повільне". Вони використовуються для позначення двох різних режимів мислення в людському пізнанні, а саме:
- Система 1. Швидке, інтуїтивне й автоматичне ухвалення рішень, що часто спирається на евристику та минулий досвід.
- Система 2. Повільне, обдумане й аналітичне ухвалення рішень, що потребує свідомих зусиль і міркувань.
Система 2 передбачає більш зважене ухвалення рішень під час розроблення та реалізації моделей глибокого навчання, що включає в себе:
- ручне тонке налаштування
- великий аналіз поведінки моделі
- більш активне втручання людини в процес навчання
Глибоке навчання Системи 2 все ще перебуває на ранніх стадіях, однак якщо воно стане реальністю, це зможе розв'язати деякі з ключових проблем нейронних мереж, включно з узагальненням поза розподілом, причинно-наслідковим висновком, надійним трансферним навчанням і маніпулюванням символами.
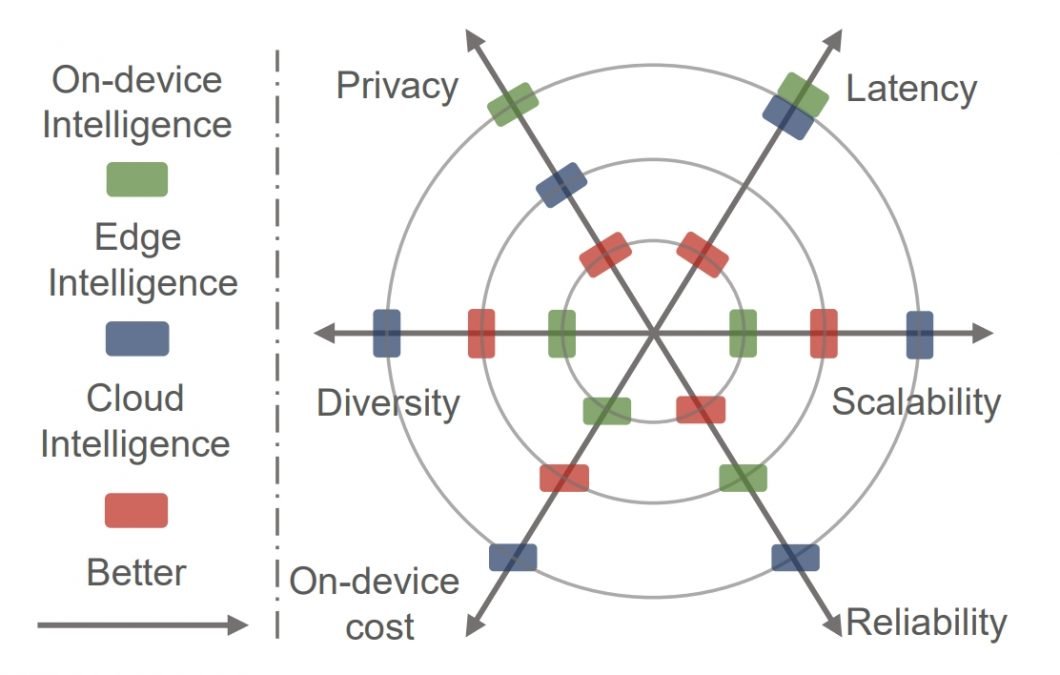
Використання граничного інтелекту
Очікується, що граничний інтелект дасть змогу максимально ефективно перенести обчислення в глибокому навчанні з хмари на периферію. Це дасть можливість створювати різні розподілені інтелектуальні сервіси з низькою затримкою та високою надійністю.
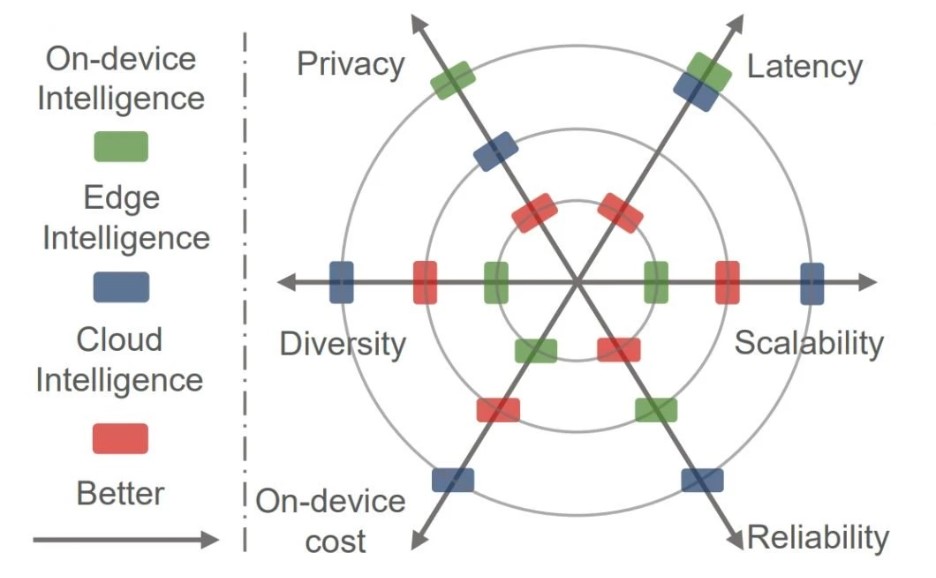
Порівняння можливостей хмарних, приладових і граничних інтелектуальних систем. Джерело.
{kind=link}
Переваги розгортання глибокого навчання на периферії полягають у такому:
- Низька затримка. Сервіси глибокого навчання розгортаються в безпосередній близькості від користувачів, які їх запитують. Це значно знижує затримки і витрати на відправлення даних у хмару для їх обробки.
- Збереження конфіденційності. Конфіденційність підвищується, оскільки вихідні дані, необхідні для роботи сервісів глибокого навчання, зберігаються локально на прикордонних пристроях або на пристроях самих користувачів, а не в хмарі.
- Функціональність в автономному режимі. Розгортання на периферії дає змогу прикордонним пристроям працювати автономно навіть у разі відключення від хмари. Це забезпечує безперервність функціонування і запобігає перебоям в обслуговуванні під час відключення мережі.
- Підвищення надійності. Децентралізована та ієрархічна обчислювальна архітектура забезпечує більш надійні обчислення в області глибокого навчання.
- Масштабованість глибокого навчання. Завдяки багатшим даним і сценаріям застосування прикордонні обчислення можуть сприяти широкому поширенню глибокого навчання в різних галузях і стимулювати впровадження ШІ.
Об'єднання ШІ та граничних обчислень може задати нові тенденції глибокого навчання у 2024 році. Це значно спростить роботу продуктів у цій ніші, а також надасть більш сприятливий ґрунт для монетизації та масштабованості технології.
Висновок
Високий попит на створення продуктів на основі штучного інтелекту створює необхідність у найкращих рішеннях у сфері глибокого і машинного навчання. Той, хто краще підготувався до наступаючих тенденцій, має більші шанси завоювати ринок і любов користувачів.
Якщо ви хочете створити рішення у сфері глибокого або машинного навчання, а також штучного інтелекту та блокчейну - ви в правильному місці. Merehead має понад 90 успішних проектів за 6 років роботи, а 83% наших клієнтів стають постійними, продовжуючи отримувати переваги від співпраці з нами.
Створіть свій найкращий проект разом із командою досвідчених професіоналів. Зв'яжіться з нами просто зараз!