
Das Zeitalter der künstlichen Intelligenz ist schon vor langer Zeit in Kraft getreten. Die Menschen haben sich an eine sofortige Identifizierung und Registrierung, eine schnellere Suche nach Transportmitteln und Routen, eine bequeme Warenauswahl und die Nutzung von KI-Diensten gewöhnt. KI wurde zu einem zuverlässigen Assistenten für Unternehmen, ersetzte Mitarbeiter und reduzierte die Fehlerwahrscheinlichkeit aufgrund des menschlichen Faktors auf Null. Routinearbeiten wurden in die Kategorie der Arbeiten verbannt, die an KI ausgelagert werden, während kreative Aufgaben von führenden Spezialisten übernommen werden.
Anwendungen und neuronale Netze, KI-Aktionsalgorithmen
KI-basierte Modelle und Algorithmen, Anwendungen und Chatbots werden von jedem der IT-Unternehmen entwickelt und nutzen maschinelles Lernen und Deep Learning zur Analyse digitaler Daten. Für anspruchsvolle Projekte werden neuronale Netze in der Wirtschaft eingesetzt. Visualisierung mit KI ist Erkennung und 3D-Computer-Vision.Zukunftsorientierte Bankanwendungen basieren häufig auf der Arbeit eines intelligenten KI-Assistenten. Von KI nach verfeinerten Kriterien durchgeführte Operationen an Börsen, Käufen, Verkäufen – Alltag. Auch die Vorauswahl von Frames nach bestimmten Indikatoren, die Erstdiagnose von Patienten und die Einrichtung von Sicherheitsmaßnahmen bei Auslösung eines bestimmten Auslösers sind Ergebnisse des KI-Denkens. Die Generierung von Texten, Bildern und Videoinhalten auf mittlerem Niveau kursiert schon seit einigen Jahren in der Gerüchteküche.
Die Analyse von FPV-Quadcopter-Bildern ist eine bequeme Möglichkeit, das Gelände in Echtzeit zu beurteilen. Es kann so konfiguriert werden, dass es direkt an ein Rechenzentrum gesendet wird, um in grundlegenden Situationen eine beschleunigte KI-gestützte Entscheidungsfindung zu ermöglichen. Die Automatisierung von Prozessen ist einer der weiteren Vorteile der KI-Implementierung.
Erkennung und Verifizierung, Diagnose und Prognose mit KI
Beispiele dafür, wie KI im Geschäftsbetrieb von Reisebüros eingesetzt werden kann, sind die Erkennung von Pässen, Versicherungen und Reisedokumenten. Die Eingabe dieser Daten in Antragsformulare oder Verträge ist mit minimalen Fehlerquoten von nur 1–5 % einfach. Die Erkennung neuronaler Netze wird trainiert, indem Fotos und Text im Raum analysiert, angepasst und überprüft und eine API-Antwort erstellt wird. Die mit RPA-Technologien erstellte Software selbst kann in jede CRM-Software oder Chatbot, User Cabinet integriert werden.Der RPA-Roboter erledigt die Routinedokumentation, erstellt Berichte und führt Vorgänge zur Festlegung der Arbeitszeiten durch. Das Training wird mit Hilfe von ML Machine Learning durchgeführt. Die Erstellung und das Training neuronaler Netze, entweder Faltungs- oder generativer Architektur, ist eine der am häufigsten verwendeten ML-Techniken. Neuronale Netze haben die Fähigkeit, Aktienhandels- und Kryptowährungspreise für die Erstellung von ICOs vorherzusagen, Diagnose von Krankheiten oder Funktionsstörungen. Wissenschaftler nutzen sie, um Vorhersagen über die Qualitätsmerkmale komponentenbasierter Medikamente zu treffen und den Zustand eines geplanten Objekts oder einer Legierung zu beurteilen.
Entscheidungsmodellierung mit Data Science
Es reicht nicht aus, Datenbanken aufzubauen und sie der KI zu zeigen: Sie müssen ihr beibringen, Situationen zu erkennen, in denen Sie schnell eine klare Antwort geben müssen. Dies sind Situationen, in denen relationale Datenbanken nicht die richtige Lösung finden können. Mit solchen Themen beschäftigen sich Data Science-Analysten. Sie sind dafür verantwortlich, die Algorithmen und die Bedingungen des mathematischen Modells zu bestimmen, unter denen es implementiert wird:- Prozessmodellierung;
- Segmentierung und Personalisierung von Kunden, Schlüsselanfragen;
- Relevanz der Angebote.
Um den Vorgang zu veranschaulichen, nehmen wir an, dass eine Person in einem Auto fährt. Er hatte einen Anruf, der einen Endorphinschub auslöste. Dadurch beschleunigte sich sein Herzschlag, aber seine Aufmerksamkeitsspanne nahm ab und es entstand der Wunsch, „schnell zu fahren“. Der Tracker an Ihrem Arm erkennt dies und übermittelt die Informationen an das KI-System des Autos. Die KI gibt eine Warnung aus – empfiehlt, die Geschwindigkeit zu reduzieren (oder tut es selbst), reduziert die Hitze in der Kabine und öffnet das Fenster.
Eine Herausforderung für die KI
KI ist einfach kein menschliches Denken. Computer erfüllen das, was der Programmierer von ihnen verlangt: Rechnen, Rechnen, Ausführen bestimmter Aktionen. Sie können die Aufgabe per Sprache oder Text festlegen, aber vorher führen Sie Regeln und Einschränkungen sowie Abhängigkeiten ein, einschließlich statistischer Abhängigkeiten. Transformationsalgorithmen sind Muster-für-Muster-Schemata: „Beschreibung“ – „Regeln“ oder „Aufgabe“ – „Lösungen“. Die Vorhersage funktioniert, wenn mehrere Situationen mit Beispielen vorgestellt werden.Betrachten Sie die folgende Aufgabe: „Schreiben Sie ein Programm in Python, um Marktplatzgewinne zu generieren. Anfangskapital 100.000 Dollar, erwarteter Gewinn 10 % der Investition, Anzahl der Waren auf dem Marktplatz 10.000, Durchschnittspreis eines Produkts 50 Dollar, Provision 3 %".
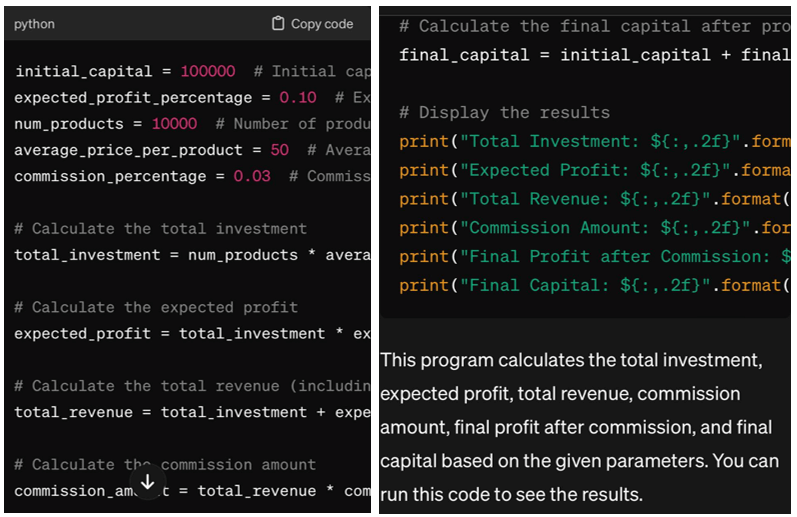
Das Ergebnis wird die oben genannte Antwort sein, die aufgrund der Einführung einer kleinen Anzahl von Indikatoren in die Problembedingungen eingeschränkt ist. Je detaillierter die Faktoren sind und je größer der Datensatz ist, desto geringer ist der Fehler in der endgültigen Lösung. Beim Training der KI gibt der Programmierer die ersten Informationen ein und markiert jedes Fragment. Wenn die Datenbank mit Kontrollmarkern akkumuliert ist, geht das Training in die Phase der Regelsuche und -überprüfung bei der Vorhersage über.
Schrittmodellierungsszenarien und -fehler
In jeder Phase wird ein vorgeschriebenes Muster gefunden und ein neues mit einem bestimmten Parameter gesucht. Wenn zum Beispiel ein Mersedes-Auto angekommen ist, dann Audi und Honda, der nächste könnte BMW oder Mitsubishi sein. Wenn keine Suche nach Mustern erforderlich ist, deaktivieren wir diese Funktion und verwenden die Lösungen der vorherigen Schritte.Ein Szenario, in dem auf die erste Markierung eine Frage und auf die nächste Markierung eine Antwort folgt, macht den Algorithmus praktisch, da er alle Fragen innerhalb dieser Grenzen der Informationsbasis beantwortet. Es ist klar, dass jeder Vorhersagealgorithmus einen Fehler enthält.
Es ist akzeptabel, wenn die Fehlergrenzen innerhalb von 5 % liegen. Das stochastische Modell ist geeignet, wenn keine Sicherheit im Bereich der Eingabe- oder Ausgabedateneingabe besteht. Eine lokale Funktion mit einwertiger Zuordnung wird durch Objektbezeichner gesteuert. Einfache Funktionen sind einparametrig, Berechnungen in ihnen erfolgen anhand von Koeffizienten, nicht jedoch anhand von Aussagen, sie sind falsch oder wahr.
Parsing-Algorithmen, Ergebnisse und Funktionen
Jeder Algorithmus ist in Schritte unterteilt: Bedingungen und Übergänge, die jeweils mit einem Ergebnisoperator, aber nicht mit einer Rückgabe enden. Der Vergleich mit einer Konstante, die einen bestimmten Punkt oder Schritt des Algorithmus darstellt, ist die Grundlage für eine kontinuierliche Vorhersage. Es kann mit der Korrelationssuche verglichen werden, bei der die Daten korrelierter Merkmale akkumuliert und zu Gruppen zusammengefasst werden. Anschließend werden auf der Grundlage der erhaltenen Basis die allgemeine Bedingung und der Abstand zwischen dem angegebenen Parameter und dem Berechnungsergebnis ausgewählt. Es sieht aus wie das:- Funktionen mit einem Parameter bilden;
- Auswahl von Teilen mit gleichen Bedingungen;
- Erstellung einer neuen Zwei-Parameter-Funktion;
- Verfeinerung der Linearität in Multiparameterbasen.
Bei der Konvertierung handelt es sich um Algorithmen zum Finden von Lösungen und zum anschließenden Erstellen von Regeln auf der Grundlage der Antworten. Manchmal ist das Ergebnis eine Rekursion mit mehreren Ebenen oder ein Fraktal. Kontrolltokens reagieren auf Anfragen und erstellen endgültige Berechnungen unter Berücksichtigung von Prozessgeschwindigkeit, Beschleunigung und Fehlern. Dennoch basieren die Algorithmen auf Statistiken.
Eigenständigkeit und Autonomie: Analyse und Entscheidungen in Einklang bringen
Es ist untypisch für einen Computer, nach einer Lösung zu suchen oder ohne Aufgabe zu recherchieren. Auch wenn der PC bedingt als menschliche Persönlichkeit programmiert ist, führt er ohne eine Aufgabe keine bestimmten Aktionen aus. Formale Logik funktioniert hier nicht, wir brauchen Mathematik und Statistik. Von der KI autonom getroffene Entscheidungen müssen analysiert werden: Wenn sie über die Grenzen von Algorithmen und Skripten hinausgehen, aber eine vorzuziehende Option darstellen, dann ist dies die Bestätigung der Richtigkeit der Entscheidung zur „Autonomie“.Prinzipien der KI:
- Die prädiktive Analyse mit der Suche nach Mustern und Trends wird auf Prognosen basierend auf Mustern und Wahrscheinlichkeiten von Ereignissen angewendet;
- Multimodalität bedeutet die gleichzeitige Verarbeitung von Informationen aus mehreren Quellen und Datentypen;
- Die multidisziplinäre Methode ähnelt der wissenschaftlichen Methode, da sie auf die Schnittstelle mehrerer Wissenschaften und ihrer Zweige abzielt, um die Leistung der KI zu verbessern.
Das maximale Analyseniveau liegt bei ASI, das dem menschlichen Denken ähnelt. Die Intelligenz von AGI liegt nahe am durchschnittlichen Niveau menschlichen Denkens. ANI ist ein typischer Darsteller, der nicht über die schriftlichen Programmaufgaben hinausgeht.
Training mit Zahlen, Erkennung und mit unvollständigen Informationen
Das Ansammeln riesiger Datenmengen erfordert ein KI-Training. Für das Maschinenformat werden lineare und multivariate Regression, Unterstützungsvektoren, Entscheidungsbaum mit Unterkategorien und KNN-Nachbarn verwendet. Reinforcement Learning umfasst Algorithmen für Roboter. Chatbot-Kommunikation ist das Ergebnis der Verwendung von Transformers nach der Verarbeitung menschlicher Sprache.Die Aufgabe von NLP ist die Text- und Audioerkennung, Übersetzung und Inhaltsgenerierung. Vor 6 Jahren entwickelten Facebook-Programmierer einen Bot auf Basis von Amazon Daten (6.000 echte Dialoge), die sich nicht von denen eines Menschen unterschieden, verhandeln und sogar betrügen konnten. Dies zeigt, dass die Aufgaben von KI in Marketingmaßnahmen und Unterhaltung vielfältig sind:
- Im Einzelhandel denken sie Algorithmen zur Ausarbeitung von Werbeaktionen und Kaufangeboten durch;
- In der Gastronomie kreieren sie Innenräume und originelle Menüs;
- In der Gaming-Branche entwickeln sie nach einer umfassenden Schulung einen idealen Geist, bestehend aus einem KI-Manager und Agentenprogrammen mit „hybrider Architektur“.
Betrachtet man beispielsweise die Libratus-Anwendung, wird deutlich, dass die KI aus mehreren Teilen besteht. Der analytische zentrale Teil interagiert mit dem zweiten Teil, der die Fehler der Gegner überwacht, und dem dritten Teil, der Fehler im eigenen Handeln analysiert. Dies ist ein Beispiel dafür, dass unvollständige Informationen verwendet werden, um eine umfassende Antwort in der Cybersicherheits-, Militär- und Verhandlungsbranche zu liefern.
Vorlagen mit korrekten Lösungen und ChatGPT-3.5-Bedienung
Vor 12 Jahren erhielten die Ökonomen Shepley und Roth den Nobelpreis für die Theorie der stabilen Verteilung. Die Lösungen der Mathematiker haben sich in der IT bestätigt: Unimodale und bimodale Verteilungstechniken funktionieren, wenn eine milliardenschwere Datenbank rekrutiert und dann in Form von Histogrammen analysiert wird. Entwickler in den Labors von OpenAI und Google, Microsoft überwachen ständig das Training der KI, schneiden falsche Lösungen ab und erstellen Vorlagen, die auf den richtigen basieren. Weltweit sind 60.000 IT-Unternehmen für KI-basierte Softwareentwicklung registriert.
ChatGPT Version 3 nutzte nur 175 Milliarden Quellen. Die bis Ende 2024 erscheinende Version 5 wird gleichzeitig Text- und audiovisuelle Inhalte generieren. Die Anzahl der Entwicklungsquellen ist 100-mal so groß wie die Datenmenge, über die ChatGPT-3 verfügt. Die erweiterte und leistungsstarke Version analysiert Daten, dient als Grundlage für Chatbots, generiert Code und führt andere virtuelle Assistentenfunktionen aus. Bisher funktioniert das 3.5-Modell so und ist fehleranfällig.
Die KI-Produkte von Google und Microsoft
Zu den bewährten KI-Anwendungen gehört DALL-E, das Bilder generiert und bearbeitet und Collagen erstellt. Whisper – ein universeller KI-Transkriptor, der Sprache erkennen und übersetzen kann. CLIP – ein Bild- und Fotoanalogisierer. Gym Library und Codex – KI-basierte Plattformen für Programmierer. Googles Liste enthält 15 ähnliche iOS-Anwendungen und Plattformen. Es stimmt, dass ihre Arbeit oft Fehler und Irrtümer aufweist.KI-Algorithmen werden in Google Fotos und YouTube verwendet, einem Übersetzer zur Verbesserung von Funktionen und zur Analyse von Daten. Der Google Bard-Chatbot ist analog zu ChatGPT, verfügt jedoch über eine eigene PaLM 2-Sprache. Dies kann gleichzeitig mit Gemini verwendet werden, das über ein hohes Maß an Generierung und Analyse verfügt. Imagen AI generiert Bilder, Generative AI ist ein Tester für generative Lernmodelle. Vertex AI hilft Wissenschaftlern bei der Datenverarbeitung, Dialogflow dient der Erstellung von Chatbots.
Zu den KI-Plattformen von Microsoft gehört die universelle Enzyklopädie Copilot, der Azure Space-Entwicklerdienst, der Bilder, Bilder und Logos sowie Image Creator-Skizzen generiert.
Großbritannien und Taiwans Foxconn nutzen KI
Im britischen HMLR-Kataster, in dem Land- und Eigentumstitel registriert werden, wird die Hälfte der Arbeit von KI erledigt. Die Überwachung der Software- und Anwendungsleistung erfolgt durch APM, daher nutzt Atlassian KI-gestützte Plattformtools, um Prozesse zu überwachen und sicherzustellen, dass keine Fehler vorliegen. Aus diesem Grund wird KI häufig zur vorbeugenden Wartung wichtiger Systeme eingesetzt und bewertet den technischen Zustand, um Ausfallzeiten und Unfälle zu verhindern.Geschäftsprognosen für ein Projekt oder einen bestimmten Geschäftsbetrieb verbessern die Genauigkeit und sparen Budget. Beispielsweise spart Foxconn, ein taiwanesischer Hersteller von Smartphone-Komponenten und Apple-Produkten, dank der Entwicklung von KI auf Basis von Amazon Forecast mehr als eine halbe Million Dollar in einer mexikanischen Fabrik ein.
Deep Learning und Schulen für KI
Programmierer und Entwickler trainieren künstliche Neuronen (Knoten), um mithilfe von Deep-Learning-Methoden Probleme zu lösen. Dazu gehören ein NLP-Algorithmus zur Verarbeitung von Sprache, Bedeutung und Ton sowie generative KI, deren Audio-, Video- und Textinhalte und Artefakte denen des Menschen ähneln. Die Rohdaten – Ressourcen mit Unterschichten – stellen die betriebliche Infrastruktur dar, auf der das Lernen stattfindet. Sie können entweder auf physischen Ressourcen oder in der Cloud gespeichert werden.Eine Art „Schulen“ für KI – Plattformen wie TensorFlow oder PyTorch. Eine in Python geschriebene Open-Source-Bibliothek Scikit-learn ist verfügbar. Für das Training werden Funktionen gebildet und Klassen gemäß dem Architekturplan der KI-Anwendung erstellt. Auf der Modellierungsebene wird die Leistung bestimmt, dann die Segmentierung nach Ebenen und die Aktivierungsfunktionalität.
Die Entwickler analysieren, wie Neuronen während der Kommunikation die Gewichte ihrer Nachbarn verändern und schätzen die Verschiebungsknoten. Vorhersage- und reale Daten sollten nicht zu stark voneinander abweichen – hierfür wird ein Vergleich mittels einer Verlustfunktion verwendet. Dabei helfen Optimierer wie Gradientenabstieg oder adaptive Gradientensequenzen unter Berücksichtigung von Minima und Maxima sowie der Änderungsgeschwindigkeit. Die KI im Bewerbungsformat dient dem Kunden statt dem Mitarbeiter.
Datensatzgenerierung, GPU- und Basismodellnutzung
Die Vielseitigkeit des GPT-Modells hängt von der Korrektheit der Promtom-Lernansätze, der Anpassung an spezifische Fragen, der Arbeit mit Datensätzen und der Rechenleistung ab. In einem Unternehmen, das KI-Modelle trainiert, gibt es einhundert oder zwei GPUs und mehr. Sie sind für die Berechnung und Verarbeitung grafischer Informationen verantwortlich und trainieren Modelle für bis zu 10–30 Tage, je nach Komplexität. Je mehr Parameter im Datensatz enthalten sind, desto höher ist der Preis.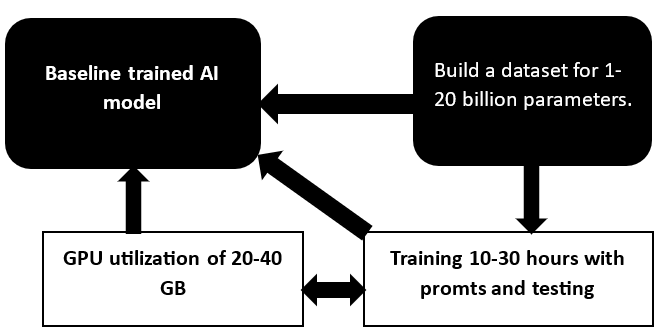
Vereinfachte Open-Source-Modelle funktionieren. Auch wenn die Einstiegshürde niedrig ist, zeigen sie in Benchmarks gute Ergebnisse. Der Preis für das Training einfacher Anwendungen auf Basis des GPT-4-Komplexes mit Google Bard oder LLaMA mit Evol-Instruct beginnt bei 500–1000 US-Dollar. Jede Basis in diesen Versionen lässt sich leicht fertigstellen und erhält eine individuelle Autorenanwendung, die besser ist als eine kostenpflichtige.
Kunden sollten sich darüber im Klaren sein, dass die Speicherkapazität für die Entwicklung vereinfachter KI-Anwendungen relativ gering ist und GPUs mit 40–80 GB Speicher erforderlich sind. Generative KI-Systeme werden auch mithilfe von Cloud-Technologien entwickelt, die auf den richtigen Diensten und Datensätzen basieren. Pipeline funktioniert in der Cloud gut, angefangen bei der Verarbeitung des Datensatzes über das Sammeln von Informationen bis hin zur Analyse der Daten. Oftmals ist das richtige Modell bereits etabliert, sodass ein Training und die Abstimmung einiger Parameter mit Adaptern erforderlich ist. Um die Informationsmenge darzustellen, beachten Sie die Faustregel: 10–15 Milliarden Parameter passen in eine 16–24 oder 40 GB große GPU.
LLM-Modell mit PEFT-Methode, vereinfachtes Szenario
Wenn ein trainiertes LLM-Modell als Basis verwendet wird, erweitert die PEFT-Methode die gewünschte Teilmenge der Parameter, lässt jedoch diejenigen, die nicht benötigt werden, in einem „eingefrorenen“ Zustand. Die Analysten des Unternehmens ermitteln im Briefing, welche Parameter den Kunden interessieren und trainieren anhand der ausgewählten Parameter. Es handelt sich um eine Teilschulung, deren Ergebnis nicht schlechter ist als eine vollständige Ausbildung. Deshalb legen IT-Spezialisten im Beratungsprozess mit dem Kunden sofort fest, ob sie ein Lösungspaket mit Anweisungen und Bedingungen generieren oder eigenständig Schulungsprogramme mit Fragen-Antwort-Paaren erstellen müssen.Das Standard-Cloud-Schulungsszenario umfasst skalierbare Cloud-Ressourcen in der Cloud, die Verwaltung von Cloud-Anbietern und die Nutzung von Standarddiensten als Schulungstools. Das ML-Entwicklungsprotokoll mit Szenarien der Quelldatengenerierung und -verarbeitung, Versionierungsexperimenten, Modellbereitstellung und -einbettung sowie der Nachverfolgung von Aktualisierungen funktioniert ohne manuelle Anpassung. Hier ist ein Beispiel einer Komplettlösung für die Plattform – eine Kombination aus JupyterHub zum Experimentieren, MLflow für die Bereitstellung und Interaktion von Data Science und Aufgaben, MLflow Deploy-Umgebung für Paketierung und Bereitstellung.
Dieses GPT-trainierte Modell beantwortet die Fragen, zu denen Informationen in den Datensatz eingegeben werden. Solche Antworten können kurz oder lang sein und spezifische Lösungen und Beispiele enthalten. Geschulte Modelle schreiben Funktionen und Programmcodes in JavaScript und Python und extrahieren bei Fragen Informationen aus Text, Datenbank oder Dokumentation.
Multimodalitätsrevolution und immersive Modellierung
Die Verfügbarkeit von KI-Modellen mit Basisinformationen vereinfacht die Schulung und den Einsatz mehrerer oder Dutzender Einheiten innerhalb einer Serviceschleife. Es ist wichtig, dass die Datensatzdaten validiert werden: Genauigkeit und Gültigkeit bestimmen die Aggregation und Integrität des Komplexes. Es wird erwartet, dass das Multimodalitätsparadigma bereits im Jahr 2024 die KI überflügeln und alle Arten von Informationen in einer einzigen Einheit verbinden wird. Die erfahrenen Entwickler sind sich dessen bewusst und bieten häufig kombinierte Lösungen an, bei denen mehrere Datenkategorien analysiert, verarbeitet und interpretiert werden.KI beginnt als AR/VR-Training zu fungieren, basierend auf dem Prinzip der immersiven Simulation. Realistische praktische Trainingsszenarien bieten praktische Erfahrungen in einer sicheren Umgebung. Für Universitäten und Hochschulen ist die virtuelle Ausbildung daher ein Schritt in Richtung Kompetenzerwerb der Studierenden während des Studiums. Darüber hinaus besteht der zusätzliche Komfort durch die Verwendung von Netflix- und TikTok-Personalisierungstechniken unter Berücksichtigung der Interessen und des Werts der Lernmaterialien sowie des Fortschritts der Schüler.
Die sich beschleunigende Entwicklung im KI-Bereich zeigt, dass benutzerfreundliche und schnell lernende Chatbots mit Anwendungen zur Generierung von Video-, Foto- und Textinhalten, zur Erkennung von Daten, zur Erstellung von Berichten und Dokumentationen, zur Suche nach Lösungen und zur Überprüfung der Funktionsfähigkeit von Objekten oder Systemen geometrisch zunehmen. KI-Anwendungen übernehmen einfache und komplexe menschliche Funktionen. Die Hauptaufgabe besteht darin, einen Lernalgorithmus richtig zu verfassen, einen Datensatz zu erstellen und Eingabeaufforderungen zu schreiben sowie Tests nach dem Lernen durchzuführen.
Die Programmierer und Entwickler des Unternehmens beherrschen diese Techniken fließend. Geben Sie die Aufgabe im Bewerbungsformular an.


