
Возникновение новых технологий стимулирует рост во всех сферах IT, в том числе - машинном обучении. Разработчики проводят большой объем работы, чтобы создать примерный прогноз тенденций глубокого обучения и нейронных сетей на 2024 год.
Тот, кто заведомо понимает тренды в 2024 году, опережает своих конкурентов на несколько шагов вперед. Это дает возможность создавать проект с учетом перспектив и будущего машинного обучения, чтобы соответствовать стандартам этой сферы.
Команда Merehead также провела собственный анализ, и предоставила вам наиболее точные результаты. Продолжайте читать эту статью, чтобы подготовиться к новым нарративам и сделать 2024 год лучшим в вашей карьере.
Что такое глубокое обучение?
Глубокое обучение - это область машинного обучения, в котором нейронные сети и алгоритмы, созданные на основе человеческого мозга, обучаются с помощью больших объемов данных.
Подобно тому, как мы учимся на собственном опыте, алгоритм глубокого обучения многократно выполняет задачу, каждый раз немного поправляя ее для улучшения результата.
Модели глубокого обучения успешно решают такие задачи, как:
- распознавание изображений и речи
- обработка естественного языка
- системы рекомендаций
Тенденции глубокого обучения в 2024 году могут увеличить количество значительных достижений и прорывов, обусловленных наличием больших массивов данных, вычислительных ресурсов и усовершенствованных алгоритмов.
Как формировались тренды глубокого обучения?
Понимание того, как формировались тренды глубокого обучения в прошлом, может дать нам лучшее представление о том, что мы можем ожидать от этой сферы в будущем. Специально для этого наша команда провела детальный анализ, чтобы как можно точнее спрогнозировать ситуацию в 2024 году.

- Доступность больших массивов данных. Наличие крупномасштабных помеченных наборов данных, таких как ImageNet для компьютерного зрения или Common Crawl для обработки естественного языка, стало решающим фактором для обучения моделей глубокого обучения.
- Увеличение вычислительной мощности. Наличие высокопроизводительных графических процессоров (GPU) и специализированного оборудования, такого как TPU (Tensor Processing Units), позволило исследователям и практикам обучать модели глубокого обучения в больших масштабах и более быстрыми темпами.
- Поиск нейронной архитектуры. Алгоритмы NAS в сочетании с вычислительными ресурсами позволили исследователям автоматически находить новые и оптимизированные сетевые архитектуры для решения соответствующих задач.
Тренды глубокого обучения и нейронных сетей в 2024
В этом разделе вы найдете наиболее вероятные тенденции глубокого обучения и нейронных сетей в 2024 году, следуя которым сможете улучшить процесс машинного обучения в целом. Дочитайте эту статью до конца, чтобы построить вектор разработки в ИИ в ближайшее время.Достижения в области проектирования архитектур
В 2024 году можно ожидать продолжения поиска новых архитектур нейронных сетей. Исследователи сосредоточатся на разработке архитектур, решающих такие конкретные задачи, как:- повышение эффективности использования памяти
- улучшение работы с последовательными данными
- повышение интерпретируемости

{kind=link}
С ростом сложности моделей глубокого обучения, все большее внимание будет уделяться разработке более эффективных и масштабируемых архитектур. Исследователи будут стремиться снизить вычислительные требования и объем памяти моделей без ущерба для их производительности.
Это позволит развертывать модели глубокого обучения на устройствах с ограниченными ресурсами, в пограничных вычислительных средах и крупномасштабных распределенных системах.
Улучшение интерпретируемости и объяснимости
По мере усложнения моделей глубокого обучения, понимание и интерпретация их процессов приобретают решающее значение. В 2024 году будут предприняты усилия по разработке таких методов, как:- визуализация и объяснения внутренних представлений глубокого обучения
- важность признаков и границ принятия решений

{kind=link}
Этические соображения и нормативные требования будут определять интеграцию объясняемости в систему глубокого обучения. Исследователи будут работать над созданием фреймворков и методологий, позволяющих моделям давать объяснения или обоснования своих предсказаний.
Это поможет повысить доверие и прозрачность систем глубокого обучения, особенно в таких критически важных областях, как здравоохранение, финансы и автономные системы.
Интеграция глубокого обучения с другими технологиями
Модели глубокого обучения будут все чаще сочетаться с технологиями AR и VR для создания иммерсивного опыта и интеллектуальных виртуальных сред. Данная интеграция позволит создавать такие приложения, как:- распознавание и отслеживание объектов в реальном времени
- понимание происходящего и взаимодействие с учетом контекста в AR и VR
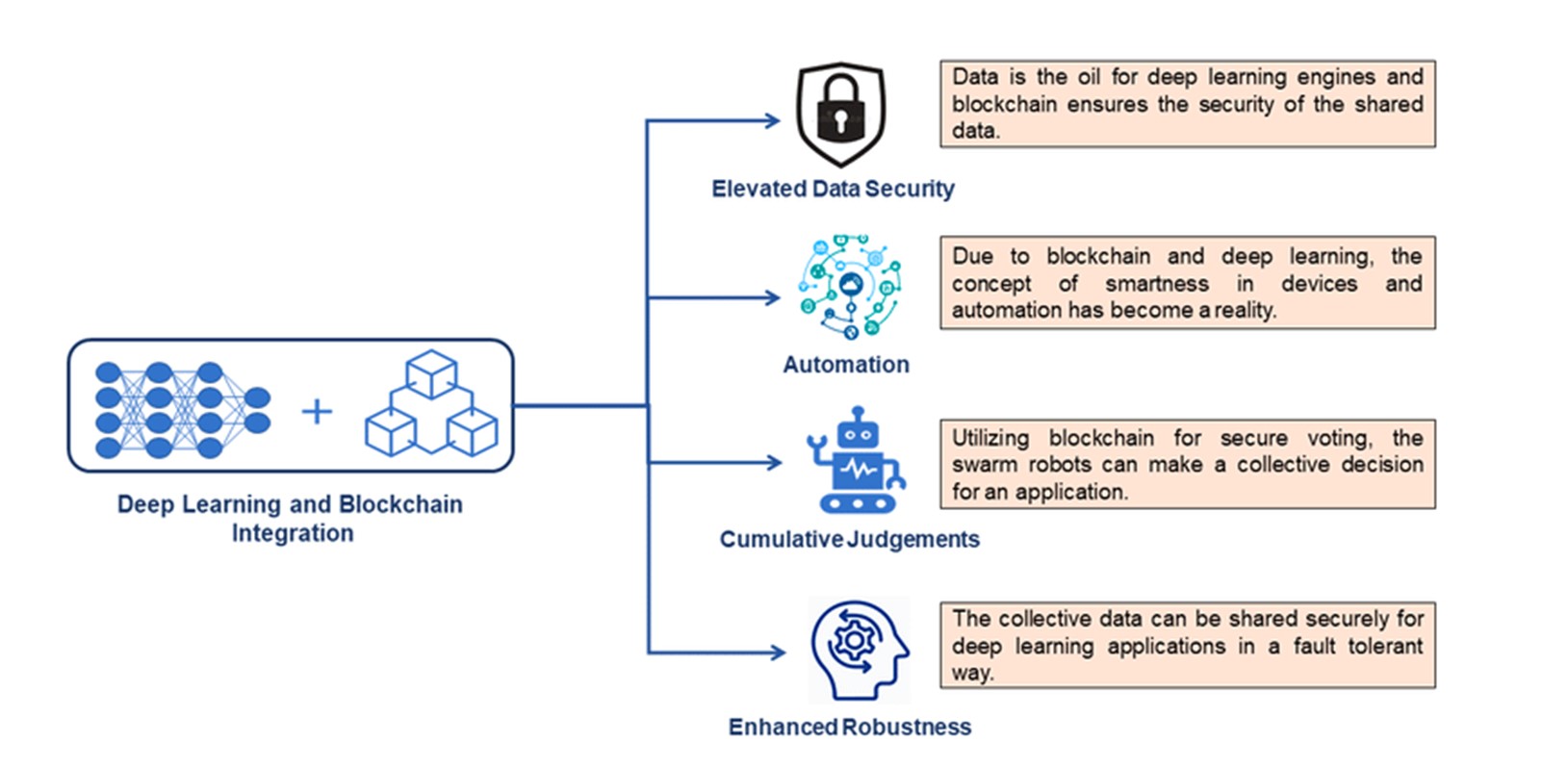
- децентрализация
- безопасный обмен и хранение данных
- прозрачность и конфиденциальность
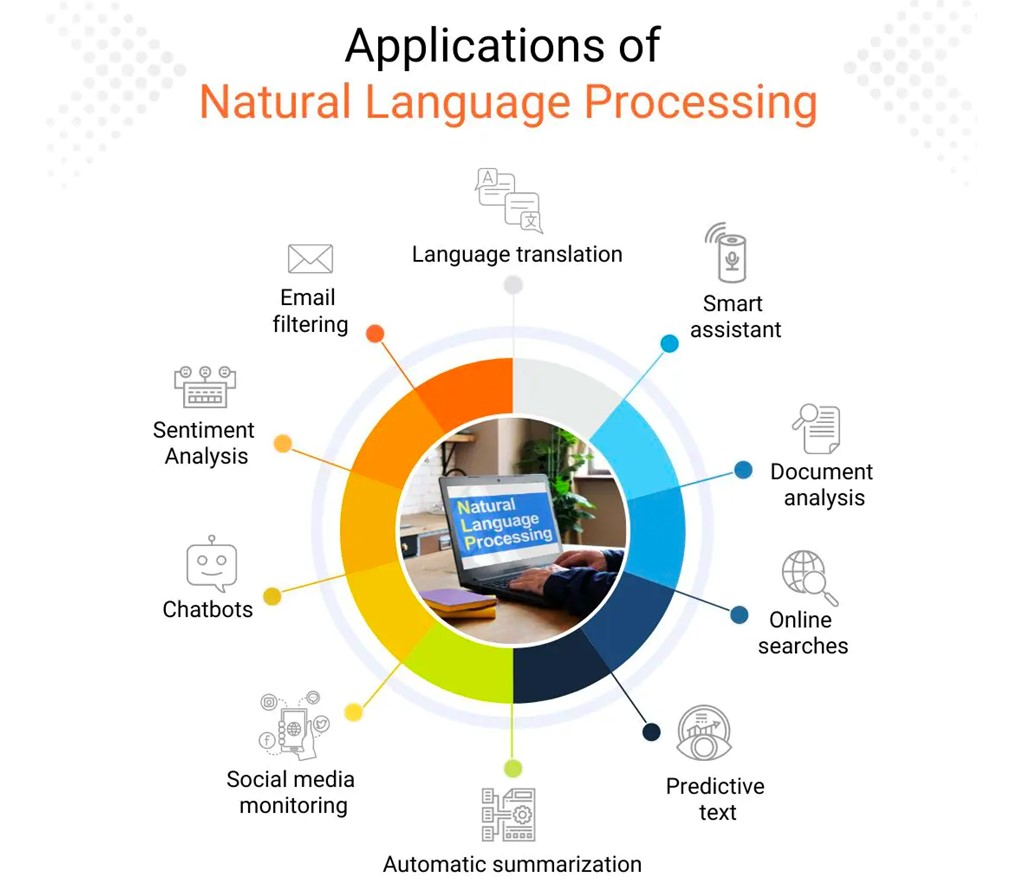
Расширение возможностей обработки естественного языка
В 2024 году обработка естественного языка продолжит развиваться, причем основное внимание будет уделяться совершенствованию моделей понимания языка и его генерации. Это включает в себя:- улучшение понимания контекста
- более точное улавливание нюансов и тонкостей языка
- разработку моделей, способных генерировать более связный и контекстуально релевантный текст
{kind=link}
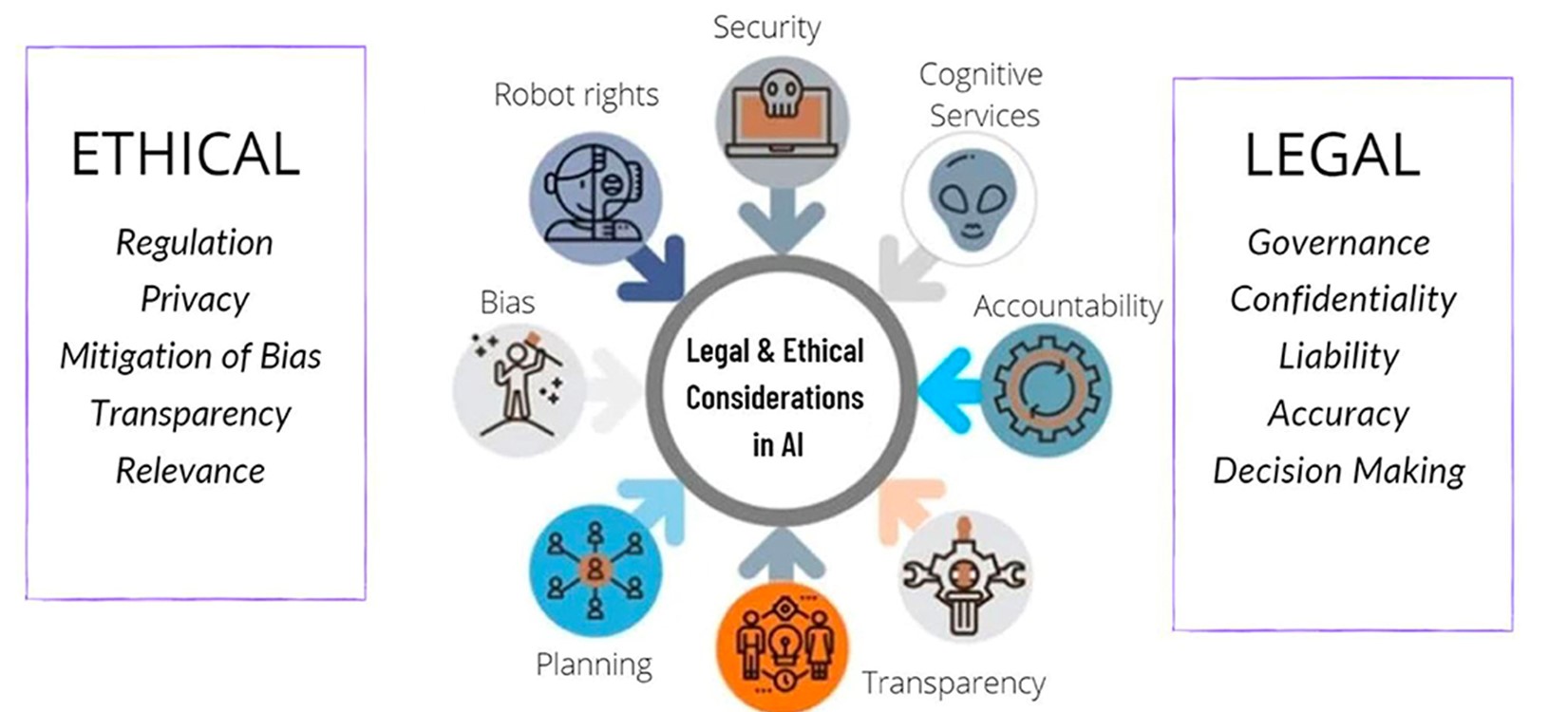
Повышенное внимание к этическим аспектам
По мере распространения технологий глубокого обучения все большее внимание будет уделяться разработке и внедрению этических принципов и правил. Это будет включать в себя:- соображения справедливости
- прозрачность
- регуляцию
- уменьшения предвзятости в моделях и приложениях глубокого обучения
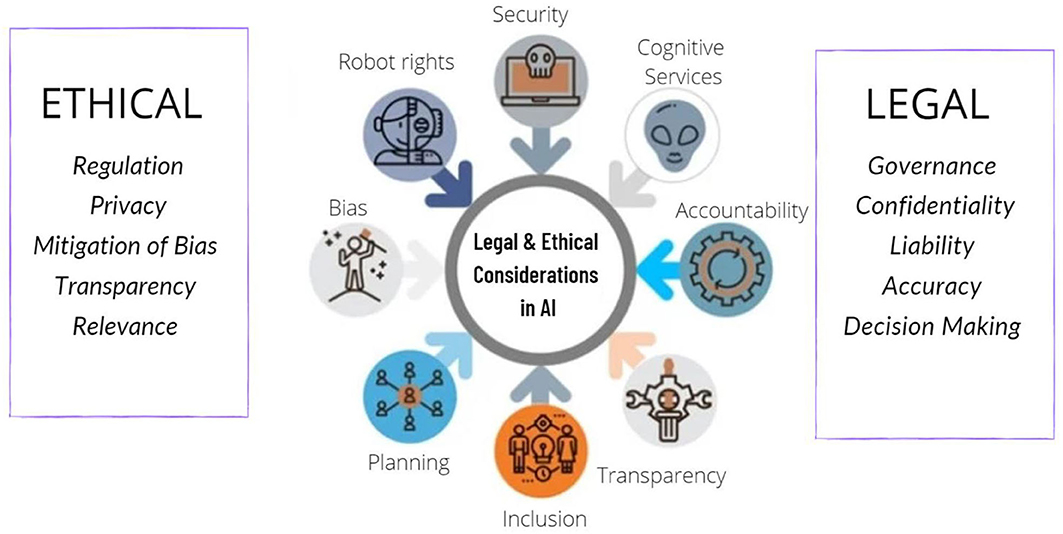{kind=link}
- финансы
- уголовное правосудие
- здравоохранение
Интеграция гибридных моделей
Интеграция гибридных моделей - это процесс объединения различных типов, моделей и архитектур глубокого обучения для использования их индивидуальных преимуществ и повышения общей производительности.Подобные тренды в 2024 году способствуют масштабированию, популярности и созданию более эффективных подходов в этой области. Гибридные модели дополняют друг друга для решения сложных задач и достижения лучших результатов.

{kind=link}
- Сложение моделей. Этот подход предполагает обучение нескольких моделей глубокого обучения независимо друг от друга и последующее объединение их результатов в виде кластера. Каждая модель может иметь различную архитектуру или быть обучена на различных подмножествах данных.
- Предварительно обученные модели и тонкая настройка. Эти модели обладают общими визуальными характеристиками, которые могут быть перенесены на новую задачу. Тонкая настройка или их адаптация позволяет эффективно использовать изученные представления и ускорить сходимость.
- Объединение архитектур. Различные архитектуры глубокого обучения могут быть объединены для использования их уникальных характеристик. Например, объединение рекуррентной нейронной сети (RNN) и сверточной нейронной сети (CNN) позволяет модели улавливать пространственные и временные зависимости в последовательных данных.
Часто приходится проводить эксперименты и тонкую настройку, чтобы найти оптимальное сочетание моделей и методов, позволяющих эффективно решить конкретную задачу и повысить производительность.
Глубокое обучение на основе нейронауки
Глубокое обучение на основе нейронауки - это тип ML, в котором для обучения искусственных нейронных сетей используются данные нейронаучных экспериментов. Это позволяет исследователям разрабатывать модели, которые основаны на работе человеческого мозга.
Она предполагает использование принципов и концепций, основанных на изучении мозга и нейронных систем, для улучшения архитектуры, алгоритмов и общей производительности моделей глубокого обучения.
Рассмотрим несколько ключевых аспектов глубокого обучения на основе нейронауки:
- Архитектура нейронных сетей. Технология направлена на разработку архитектур нейронных сетей, которые отражают различные структуры связей, наблюдаемые в мозге. Например, конволюционные нейронные сети вдохновлены иерархической обработкой данных в зрительной коре, а рекуррентные нейронные сети - рекуррентными связями в мозге.
- Алгоритмы обучения. Нейронаука дает представление о том, как мозг обучается и обрабатывает информацию. Включая эти принципы в алгоритмы глубокого обучения, исследователи стремятся повысить его эффективность.
- Когнитивные и поведенческие аспекты. Понимание того, как мозг воспринимает, обрабатывает и взаимодействует с окружающей средой, может помочь в разработке моделей глубокого обучения для таких задач, как распознавание образов, понимание естественного языка или обучение с подкреплением.
Используя достижения нейронауки, исследователи стремятся разработать более биологически обоснованные, эффективные, интерпретируемые и человекоподобные модели глубокого обучения.
ViT
Vision Transformer (ViT) - это архитектура глубокого обучения, которая применяет модель Transformer, первоначально созданную для задач обработки естественного языка. Она представляет собой отход от традиционных сверточных нейронных сетей, поскольку использует механизмы самонаблюдения для улавливания дальних зависимостей и контекстной информации в изображениях.
Основная идея этой архитектуры заключается в том, чтобы рассматривать изображение как последовательность патчей и применять модель Transformer для их обработки.
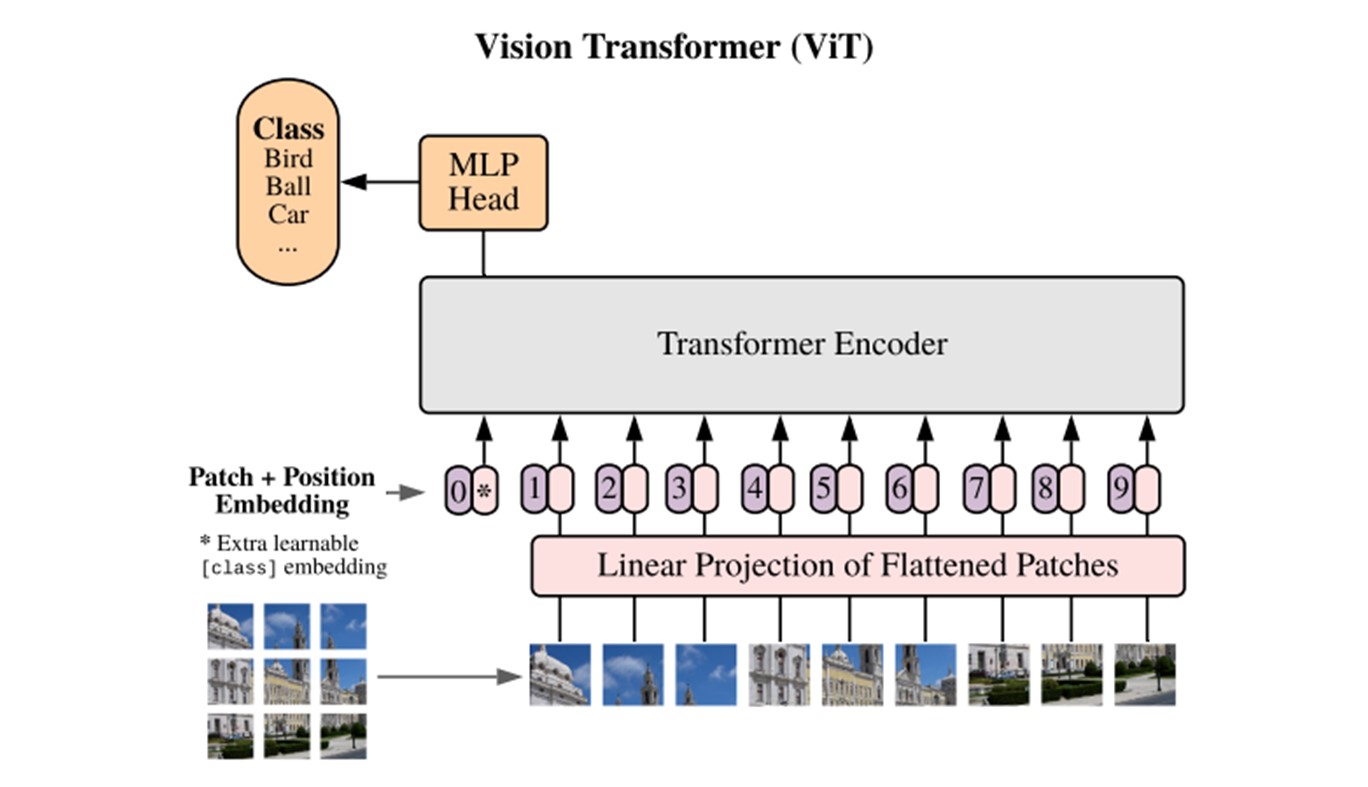
{kind=link}
- Встраивание патчей. Входное изображение разбивается на сетку непересекающихся патчей фиксированного размера. Затем каждый патч линейно проецируется на вектор встраивания, имеющий меньшую размерность. Это позволяет модели обрабатывать изображение как последовательность вкраплений.
- Позиционное кодирование. Позиционное кодирование представляет собой относительное или абсолютное положение каждого фрагмента на изображении, что позволяет модели понимать пространственные отношения между ними.
- Трансформаторный кодер. Вкрапления патчей вместе с позиционным кодированием поступают в стек слоев трансформаторного кодера. Каждый его слой состоит из многоголовочных механизмов самовнушения и нейронных сетей с прямолинейным движением. Это позволяет посещать различные участки изображения и улавливать зависимости по всему пространству.
Как и тренды нейронных сетей в 2024 году, подобные архитектуры глубокого обучения могут значительно ускорить развитие новых IT-решений. Если вы хотите создать технологичный продукт, используя глубокое обучение, Merehead - ваш лучший выбор!
Самоконтролируемое обучение
Самоконтролируемое обучение - это парадигма, при которой модель учится извлекать значимые представления или признаки из немаркированных данных без необходимости в явных метках, предоставляемых человеком.
В отличие от контролируемого обучения, в котором модели обучаются на помеченных данных, содержащих "истинные" аннотации, самоконтролируемое обучение использует внутреннюю структуру. С помощью немаркированных данных, модель учится улавливать высокоуровневую семантическую информацию и полезные представления, которые могут быть перенесены в последующие задачи.

{kind=link}
- Предварительное обучение. В процессе предварительного обучения, модель учится извлекать из входных данных значимые представления или признаки, пытаясь решить вспомогательную задачу.
- Тонкая настройка. Тонкая настройка позволяет модели адаптировать и специализировать полученные представления к конкретной задаче. Этот этап помогает перенести знания, полученные в ходе самоконтролируемого обучения, на решение конкретной задачи.
- компьютерное зрение
- обработку естественного языка
- распознавание речи
Кроме того, самообучение способствует формированию надежных представлений, которые отражают релевантную информацию из распределения данных. Это приводит к повышению производительности при решении последующих задач.
Высокоэффективные модели NLP
Высокоэффективные модели NLP - это продвинутая модель, которая разработана для достижения современной производительности при решении различных задач обработки естественного языка.
Команда Merehead подготовила список лучших высокопроизводительные моделей NLP, которые смогут задать тенденции глубокого обучения в 2024 году. Среди них:
- Модели на основе трансформаторов. Трансформаторные модели, такие как "Transformer" и его разновидности, например BERT, GPT и RoBERTa, значительно продвинулись в области NLP.
- Предварительно обученные языковые модели. Такие модели, как GPT, BERT и XLNet, предварительно обучаются на огромных объемах текстовых данных с помощью подходов, основанных на неконтролируемом или самоконтролируемом обучении. Они обеспечивают глубокое понимание языка и могут быть тонко настроены для решения конкретных задач NLP.
- Конволюционные нейронные сети (CNN). Такие модели, как CNN Кима и CNN Юн Кима, используют конволюционные операции для улавливания локальных и композиционных признаков текста, достигая конкурентоспособной производительности в таких задачах, как классификация текстов и анализ настроения.
Как правило, они обучаются на больших наборах данных, как маркированных, так и немаркированных, чтобы уловить разнообразные языковые паттерны и добиться лучшего обобщения.
Глубокое обучение Cистемы 2
В 2019 году на конференции по системам обработки нейронной информации (NeurIPS 2019) Йошуа Бенжио, один из трех пионеров глубокого обучения, выступил с программной речью, которая пролила свет на возможный переход глубокого обучения Cистемы 1 к Cистеме 2.

Две системы мышления. Источник.
- Система 1. Быстрое, интуитивное и автоматическое принятие решений, часто опирающееся на эвристику и прошлый опыт.
- Система 2. Медленное, обдуманное и аналитическое принятие решений, которое требует сознательных усилий и рассуждений.
- ручную тонкую настройку
- обширный анализ поведения модели
- более активное вмешательство человека в процесс обучения
Использование граничного интеллекта
Ожидается, что граничный интеллект позволит максимально эффективно перенести вычисления в глубоком обучением из облака на периферию. Это даст возможность создавать различные распределенные интеллектуальные сервисы с низкой задержкой и высокой надежностью.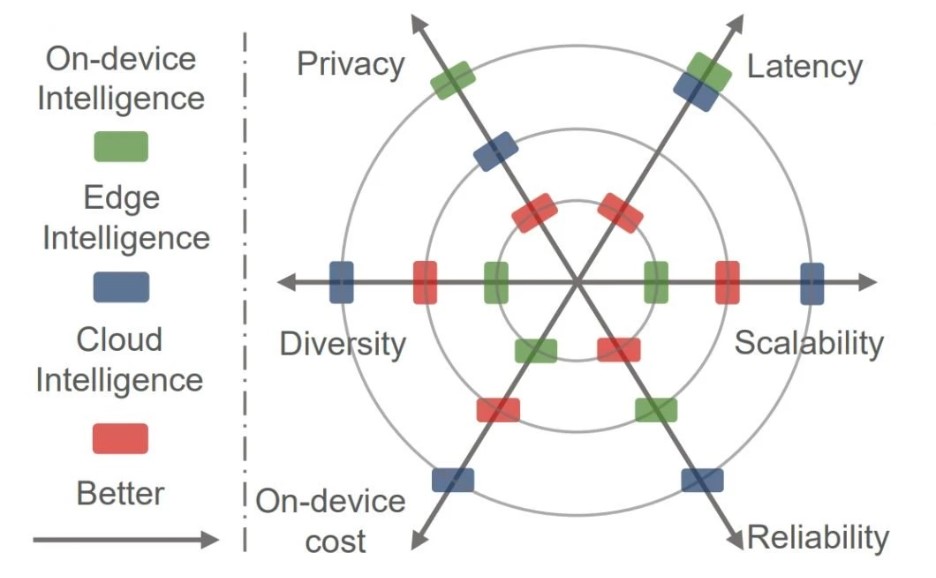
Сравнение возможностей облачных, приборных и граничных интеллектуальных систем. Источник.
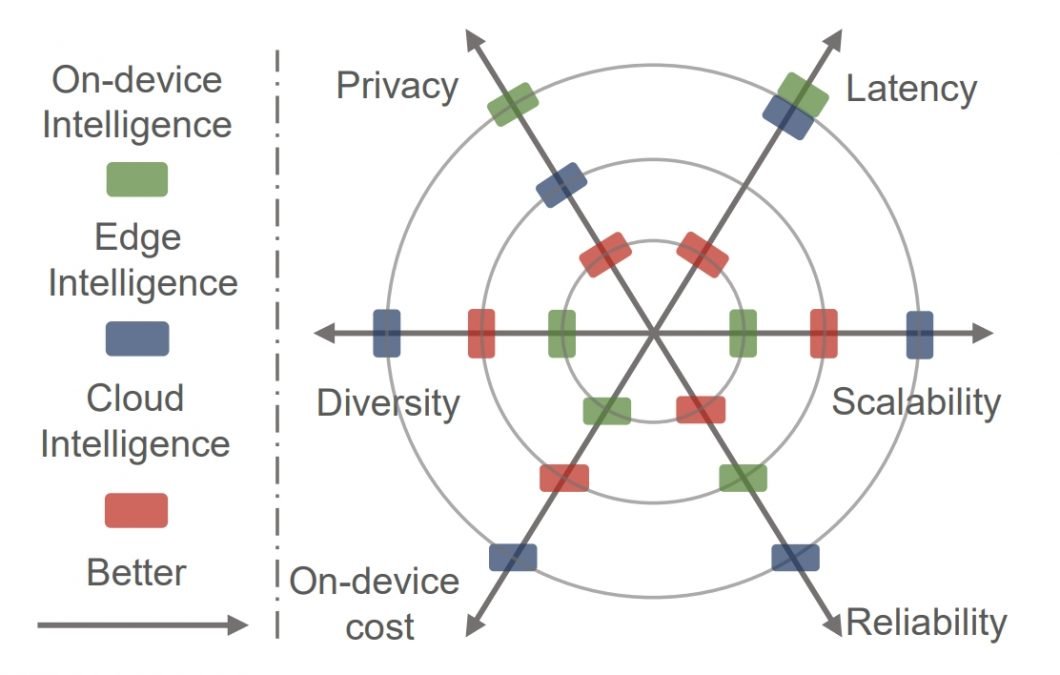{kind=link}
- Низкая задержка. Сервисы глубокого обучения развертываются в непосредственной близости от запрашивающих их пользователей. Это значительно снижает задержки и затраты на отправку данных в облако для их обработки.
- Сохранение конфиденциальности. Конфиденциальность повышается, поскольку исходные данные, необходимые для работы сервисов глубокого обучения, хранятся локально на пограничных устройствах или на устройствах самих пользователей, а не в облаке.
- Функциональность в автономном режиме. Развертывание на периферии позволяет пограничным устройствам работать автономно даже при отключении от облака. Это обеспечивает непрерывность функционирования и предотвращает перебои в обслуживании при отключении сети.
- Повышение надежности. Децентрализованная и иерархическая вычислительная архитектура обеспечивает более надежные вычисления в области глубокого обучения.
- Масштабируемость глубокого обучения. Благодаря более богатым данным и сценариям применения пограничные вычисления могут способствовать широкому распространению глубокого обучения в различных отраслях и стимулировать внедрение ИИ.
Заключение
Высокий спрос на создание продуктов на основе искусственного интеллекта создает необходимость в лучших решениях в области глубокого и машинного обучения. Тот, кто лучше подготовился к наступающим тенденциям имеет большие шансы завоевать рынок и любовь пользователей.Если вы хотите создать решение в сфере глубокого или машинного обучения, а также искусственного интеллекта и блокчейна - вы в правильном месте. Merehead имеет более 90 успешных проектов за 6 лет работы, а 83% наших клиентов становятся постоянными, продолжая получать преимущества от сотрудничества с нами.
Создайте свой лучший проект вместе с командой опытных профессионалов. Свяжитесь с нами прямо сейчас!