
Wir erheben nicht den Anspruch, alle Nuancen der Planung, Entwicklung und Prüfung von KI-Anwendungen abzudecken, sind jedoch der Meinung, dass sowohl erfahrene Entwickler als auch Anfänger in den ausführlichen Anleitungen und Beispielen nützliche Informationen finden werden. Die Palette der Anwendungstechnologien, die auf der Verwendung neuronaler Netze basieren, ist riesig: von einem vereinfachten Informanten-Bot bis hin zu einer Anwendung, die mit Funktionen zur Planung des Handelsvolumens, der Lieferung, der Berechnung und Prognose von Gewinnen, der Kontrolle von Mitarbeitern und der Interaktion mit Kunden ausgestattet ist. Einige erfolgreiche Beispiele für KI-Implementierungen, die mit minimalen Investitionen begonnen haben, sind Grammarly und Duolingo, die Dienste Waze und Canva sowie der Fotoeditor FaceApp.
Übersicht über die Anwendungsbereiche der KI
Die Funktionsweise der KI erfolgt innerhalb des Prokrustesbetts mehrerer Regeln und Kategorien, darunter:- Verfügung über leistungsstarke GPUs, Tausende Gigabyte an Daten und RAM von mehreren vernetzten Knoten zum Trainieren des Modells;
- Einbettung des Internets der Dinge und Algorithmen zum Kombinieren von Informationen aus mehreren Schichten in KI-Modelle;
- Vorhersage von Ereignissen, Verständnis paradoxer Situationen und Koordination hochpräziser Systeme;
- Implementierung von APIs zum Generieren neuer Protokolle und Interaktionsmuster.
Typisches ML-Maschinenlernen ersetzt den Operator zu Beginn der Kommunikation mit dem Supportcenter und klärt grundlegende Fragen. Wenn VCAs in einem tiefen Format eingebunden sind, werden Anfragen personalisiert und die Kontaktsicherheit dank der Spracherkennung und des psychologischen Status der Kunden erhöht. Die Automatisierung aktueller Aufgaben wie die Suche nach Tickets, die Bestellung von Waren und die Auswahl von Wegpunkten ist Teil der Funktionen virtueller Operatoren. Aus diesem Grund hängt die Wahl von ML oder VCA von den zu lösenden Problemen ab.
Logistik, Kundenbewertung und Rekrutierung
KI-koordinierte Lieferketten und Logistik vereinfachen das Geschäft, indem sie die Lagerverfügbarkeit von Artikeln anzeigen, Reserven angeben, Effizienz und Amortisationszeiten prognostizieren. Dies ist die Arbeit von hochrangigen KI-Anwendungen und -Diensten, deren Preise bei 100.000 US-Dollar beginnen. Die Prüfung von Einnahmen- und Ausgabenpositionen sowie die Identifizierung von Trends bei der Gewinnsegmentierung ist ein Beispiel für die Anwendung von KI in der Finanzbranche. Die Anwendung funktioniert auf ähnliche Weise, indem sie jeden Kunden personalisiert und die Verkaufseffizienz analysiert: Medienwerbestrategien verbessern die Marketingpositionen.Die NLP-Funktionen der KI ermöglichen die anfängliche Suche nach Mitarbeitern und identifizieren ihre beruflichen Fähigkeiten. Dabei empfiehlt die KI-HR Änderungen an den Stellenbeschreibungen der Mitarbeiter, wenn sie eine fortschreitende Assimilation und Automatisierung der Fähigkeiten feststellt, was das Karrierewachstum fördert.
Grundlage: die richtigen Aufgaben und genaue Daten
Die ersten beiden Phasen der Planung organisatorischer und technologischer Abläufe für die Entwicklung einer KI-Anwendung sind ein grundsätzlich solides Programm mit mehreren Schritten. Das Diagramm zeigt deutlich, dass der erste Teil die Problemformulierung, die Werkzeugauswahl, die erforderlichen Ressourcen, die erwarteten Kosten und Gewinne umfasst. Der zweite Schritt ist für die Bildung validierter und genauer Datenbanken verantwortlich, die für das Modelltraining bereit sind.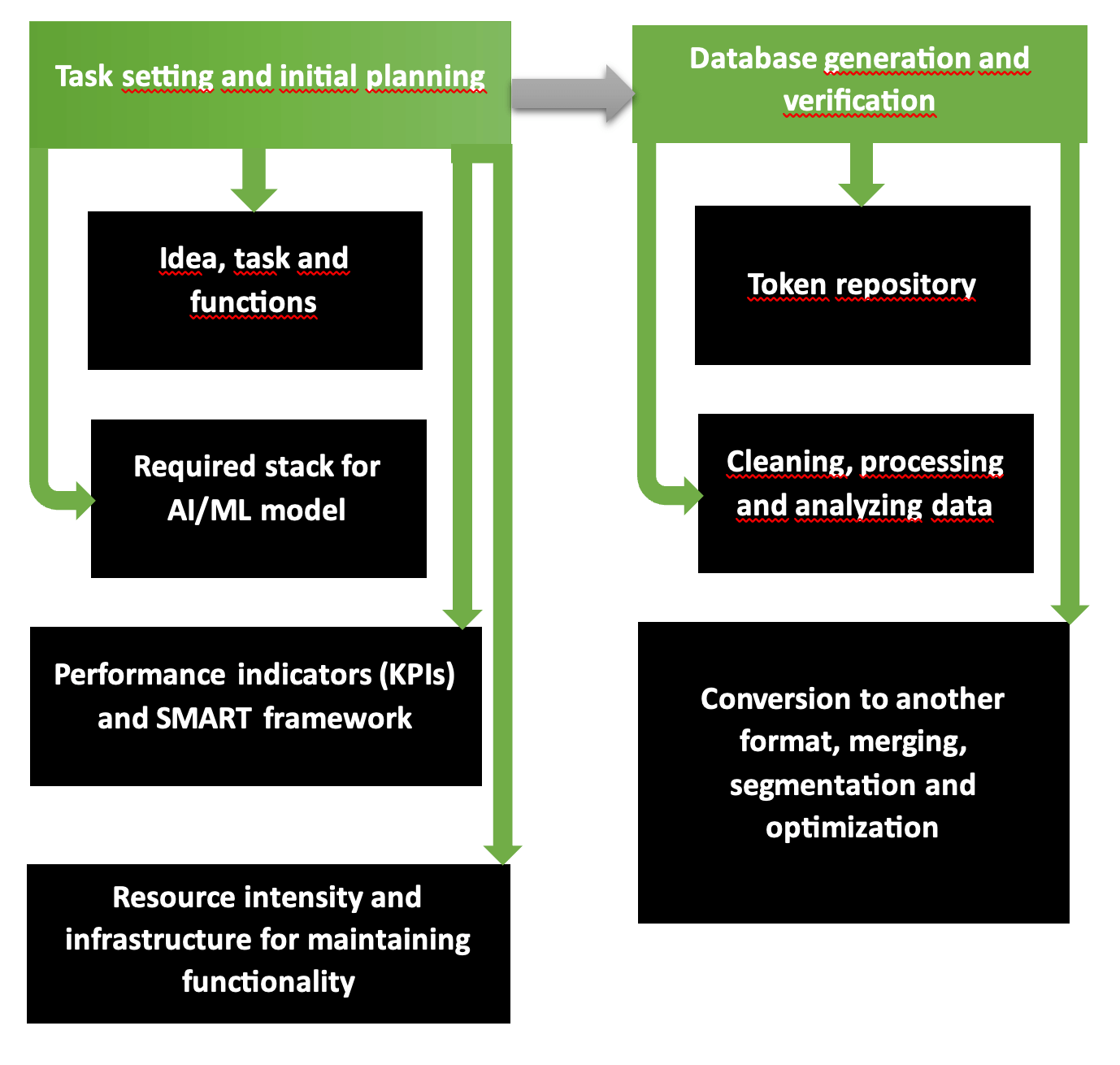
So beginnt das KI-Entwicklungsunternehmen für plattformübergreifende Anwendungen zu arbeiten. Die Kette „Anforderungen – Ziele – Visionsausrichtung – einheitlicher Stil“ wird gemäß der SMART-Struktur durchdacht und schrittweise in Scrum oder Agile kategorisiert. Ziele und Ressourcenverfügbarkeit bestimmen, welcher Umfang an Dienstleistungen und Waren im geplanten Modus bereitgestellt und bei Knappheit oder Mittelüberfluss reduziert oder erweitert werden kann.
Common Crawl, Plattformen wie Kaggle oder AWS bieten Datenbanken, die im Falle einer digitalen und grafischen Knappheit des Quellmaterials auf Genauigkeit, Informationsgehalt, Wiederholung und fehlerfreien Inhalt überprüft wurden. Um Ihre eigene Datenbank zu überprüfen, führen Sie das Dienstprogramm Tibco Clarity (eingeführt 1997) oder die Software OpenRefine aus.
Ständige Verbesserung und multimodale Lösungen
Python ist eine beliebte Programmiersprache, die aufgrund der Einfachheit der Befehle gleichzeitig die Grundlage für die Erstellung von KI-Anwendungen darstellt. Die Fälle der Produktentwickler sind voll von KI-Lösungen für Google und Netflix, Videohosting und streaming plattform. KI-Anwendungen müssen ständig verbessert werden:- Sie müssen darin geschult werden, sensible und vertrauliche Informationen zu analysieren;
- Sie müssen unangemessene und gruselige Elemente aus den erstellten Fotos und Videos entfernen;
- Sie müssen Algorithmen mit Verschlüsselung der Datenbanken von Kunden und Unternehmen erstellen, mit denen Kooperationsvereinbarungen geschlossen wurden;
- Sie müssen Anomalien bei vorgeschlagenen Lösungen erkennen, die von KI entwickelt wurden.
Die modale Datenverarbeitung des Aktionsmodells Chameleon bringt die KI näher an das paradoxe Format der menschlichen Reflexion. Die Autoregression mithilfe des 34B-Protokolls wurde an 10T-Datentoken trainiert, sodass das Multimodalitätsmodell die Generierung von Inhalten und Bildern mit realistischen Parametern gewährleistet.
4D im PSG4DFormer-Modell und Entwicklung im Zeitbereich
Lernen nach 4D-Regeln – zeitbasiertes Lernen – interpretiert Informationen (Daten, audiovisuelle Inhalte, Videos) auf einer Zeitachse. Dynamismus 4D ist das Verständnis von laufenden Prozessen in der Zeit. Das PSD-4D-Modell bildet volumetrische Knoten, an deren Rändern sich die zu untersuchenden Objekte befinden.Anschließend führt das Modell durch Anwenden der annotierten Datenbank mit 4D-Masken eine Segmentierung durch und arbeitet Situationen innerhalb eines bestimmten Zeitbereichs detailliert aus. Dies ähnelt dem Storyboarding eines Films, bei dem der Regisseur Szenen und Ereignisse Minute für Minute verteilt. Das PSG4DFormer-Modell sagt die Erstellung von Masken und die anschließende Entwicklung auf einer Zeitachse voraus. Solche Komponenten sind die Grundlage für die Generierung zukünftiger Szenen und Ereignisse.
Testen vor dem Start
Das Testen von Anwendungen wird durch die Integration des Python-Pakets in das Django-Framework beschleunigt. Python- und Webentwickler sowie DevOps-Ingenieure verwenden zu diesem Zweck integrierte Django-Tools, schreiben Testfälle für Unit-Tests und betten das Paket dann in das Framework ein.In der Featuretools-Bibliothek werden Features für ML-Modelle automatisch entwickelt: Zu diesem Zweck werden die Variablen aus einer Datenbank ausgewählt, um die Grundlage für die Trainingsmatrix zu bilden. Daten im Zeitformat und aus relationalen Datenbanken werden während des Generierungsprozesses zu Trainingspanels.
Bibliotheken, Plattformen und Sprachen sind Stapelelemente
Die Liste der Frameworks, die die Leistung von KI-Modellen verbessern, umfasst die Open-Source-Bibliothek TensorFlow und die TFX-Plattform, die die Bereitstellung eines fertigen Projekts beschleunigt. Diese sind für Bilder optimiert. Das PyTorch-Modul ist in mehreren Sprachen geschrieben, darunter Python, eine Basisversion von C++ und die CUDA-Architektur, die für NVIDIA-Prozessoren und -Grafikkarten entwickelt wurde.Wenn physischer Speicher und Bereitstellungsumgebungen knapp sind, werden SageMaker-, Azure- und Google-Cloud-Lösungen verwendet. Julia ist eine der beliebtesten neuen Sprachen zur Generierung von KI-Anwendungen: Bei Verwendung von in Julia geschriebenen Befehlen werden mehr als 81 % der Befehle schnell, genau und mit minimalen Fehlern ausgeführt. JavaScript und Python, R zeigen ebenfalls gute Ergebnisse mit einer Genauigkeit von über 75 %.
Im Anwendungsstapel fügen wir die JupyterLab-Umgebung, die NumPy-Bibliothek für mehrdimensionale Arrays oder eine einfachere Variante Pandas hinzu. Die Dask-Bibliothek ist für die Analyse großer Datenbanken mit Clustern, Visualisierung und Parallelisierung sowie die Integration mit Umgebungen und Systemen zur Reduzierung der Hardware-Wartungskosten konzipiert.
Funktionen XGBoost, TensorFlow, FastAPI
XGBoost 2.0 arbeitet nach dem Prinzip der multivariaten und Quantilregression und umfasst viele Funktionen im Operationsbaum. Die neue Funktionalität umfasst ein verbessertes Ranking und optimierte Histogrammgrößen, und die PySpark-Schnittstelle ist übersichtlicher geworden. Wenn Sie MXNet und TensorFlow vergleichen, ist es aufgrund der besseren Lernbarkeit, des Debuggens und der Datenladegeschwindigkeit besser, die letztere Plattform zu wählen.Asynchrone und schnelle FastAPI-Operationen machen das Framework Django vorzuziehen, wo auf Servern der WSGI-Standard auf das neue asynchrone ASGI konfiguriert werden muss. Da die Schnittstelle 6 Jahre alt ist, verfügt sie über eine begrenzte Datenkapazität für JWT-Token und S3-Speicher. Wir berücksichtigen, dass asynchrone Bibliotheken häufig Probleme mit nicht lesbaren Informationen haben und wir manchmal Schreibvorgänge durchführen müssen, indem wir nach Übergabe der SQL-Abfrage und Materialien „execute()“ aufrufen. Hinweis: Das root_path-Attribut wird nicht in „/api“ geändert, was unpraktisch ist.
Containerisierung, Bereitstellung und KI-Modellarchitektur
Der Containerisierungsprozess wird gestartet, wenn die Komponenten zum Erstellen einer KI-Anwendung zusammengeführt werden (Code und Bibliotheken mit Frameworks). Ein eigenständiger Container wird vom Host abstrahiert und ohne Neukompilierung in eine andere Umgebung portiert. Docker Engine und Kubernetes sind die Pioniere dieses Segments, das gefragte Betriebssystem ist Linux (Cloud oder lokal), OCIs arbeiten im Lesemodus, ohne Änderungen. VMware und LXC sind auf dieser Liste. Container werden manchmal auf der GitHub-Plattform gespeichert: insbesondere, wenn an einem Projekt gemeinsam gearbeitet wird.Zu den Bereitstellungstools gehören die proprietäre PaaS-Plattform Heroku, das ausgefeiltere Elastic Beanstalk und Qovery, das das Beste aus beiden Ressourcen nutzt. Zum Testen verwenden sie:
- Selenium mit drei Arten von Diensten: WebDriver, IDE und Grid;
- PyTest-Plattform mit skalierbaren Tests auf Python 3.8+ oder PyPy3-Versionen;
- Locust mit Belastungstests.
| Modellarchitektur | Aufgabe | Besonderheiten |
| Convolutional (CNN) | Video und Bilder | Genaue Identifikation, Eliminierung von Rauschen und Fehlern |
| Recurrent (RNN) | Digitale Daten und Sprache | Sequenzverarbeitung |
| General Adversarial (GAN) | Generierung neuer Daten und Bilder | Simulation mit Generierung neuer Daten als Grundlage für das Training |
Anschließend wird die Das Training von KI-Modellen wird filigran fein abgestimmt. Wenn das Szenario hohe Anforderungen mit präzisen Parametern umfasst, wird das Training mit Beobachtung fortgesetzt – solche Bedingungen sind teurer. Um Artefakte und Muster in Clustern zu finden, ist es vorzuziehen, sich für Selbsttraining zu entscheiden. Für Projekte in der Robotik und einfache spiel im Telegram wird Verstärkung (Ermutigung oder Bestrafung – die „Zuckerbrot und Peitsche“-Methode) verwendet.
Entwicklungszeitpunkt, Fehlerprüfung
Der Zeitaufwand für die Entwicklung, das Testen und den Betrieb eines KI-Modells sieht ungefähr so aus wie im Diagramm. Der Algorithmus erfordert eine genaue Beschreibung der Aufgabenausführung – damit das Ergebnis eine neue Lösung für die Mustererkennung ist. Die Kette „Iterationen-Vorhersagen-Korrektur“ wird durch Hyperparameter vervollständigt, die manuell eingegeben werden, bevor mit der Kreuzvalidierung in Teilmengen begonnen wird.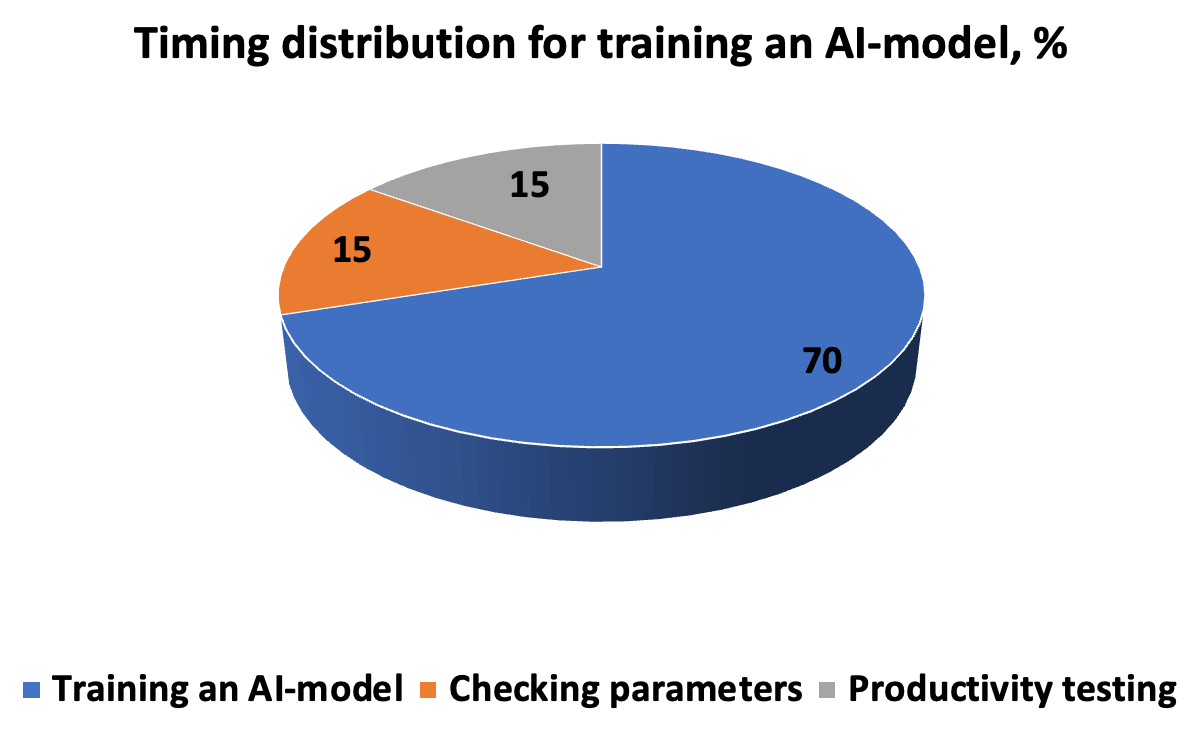
Damit das Modell in realen Szenarien produktiv funktioniert, müssen wir die Richtigkeit und Reaktionsgeschwindigkeit bewerten. Daher umfassen die Messparameter Präzision und Wiederholbarkeit, ROC-AUC-Metriken, bei denen es nicht notwendig ist, den Schwellenwert abzuschneiden (für eine unausgeglichene Datenbank), F-Score, der den Anteil positiver Lösungen angibt, MSE-mittlerer quadratischer Fehler und R-Quadrat-Bestimmtheitskoeffizient. Ein Fehler innerhalb von 5 % wird als akzeptabel angesehen; wenn er auf 1 und 0,1 % reduziert wird, gilt das Ergebnis als sehr genau.
RAG und Anpassung, Backend- oder Frontend-Integration, Testen
Die RAG-Methode wird verwendet, um generative Modelle zu entwickeln, bei denen Vektoren und Semantiken Segment für Segment basierend auf Kontext und Relevanz angenähert werden. Die Grundlage von RAG besteht darin, Informationen aus umfangreichen Datenbanken zu extrahieren und sie dann in ein Modell zu generieren, um eine genaue Antwort zu erhalten. Die Feinabstimmung für spezialisierte Experimente umfasst die Normalisierung (Reduktion auf gemeinsame Parameter) und nach der Anpassung die Tokenisierung. Um das KI-Modell produktiv zu machen, erfolgt die Integration je nach Aufgabe im Backend oder Frontend. Es ist besser, das Sprachmodell in den Serverteil zu integrieren und mit Clients zu arbeiten - in die Schnittstelle.Im IoT wird der Peripheriebetrieb auf dem Gerät bevorzugt, da er die Privatsphäre schützt und eine schnelle Leistung bietet. Der Kern des IoT ist die Datengenerierung, deren Essenz die Konvergenz von KI mit IoT ist. Diese Synergie baut die Funktionalität der beiden Teile auf und bringt AIoT hervor. Um jedoch die Leistung und Skalierbarkeit der Funktionalität zu verbessern, ist es besser, Cloud-basierte Technologien mit eingebetteten API-Protokollen anzuwenden. Wenn es wichtig ist, Kundenfeedback zu hören (Bequemlichkeit, Klarheit, Geschwindigkeit), bauen wir eine Feedback-Funktion ein.
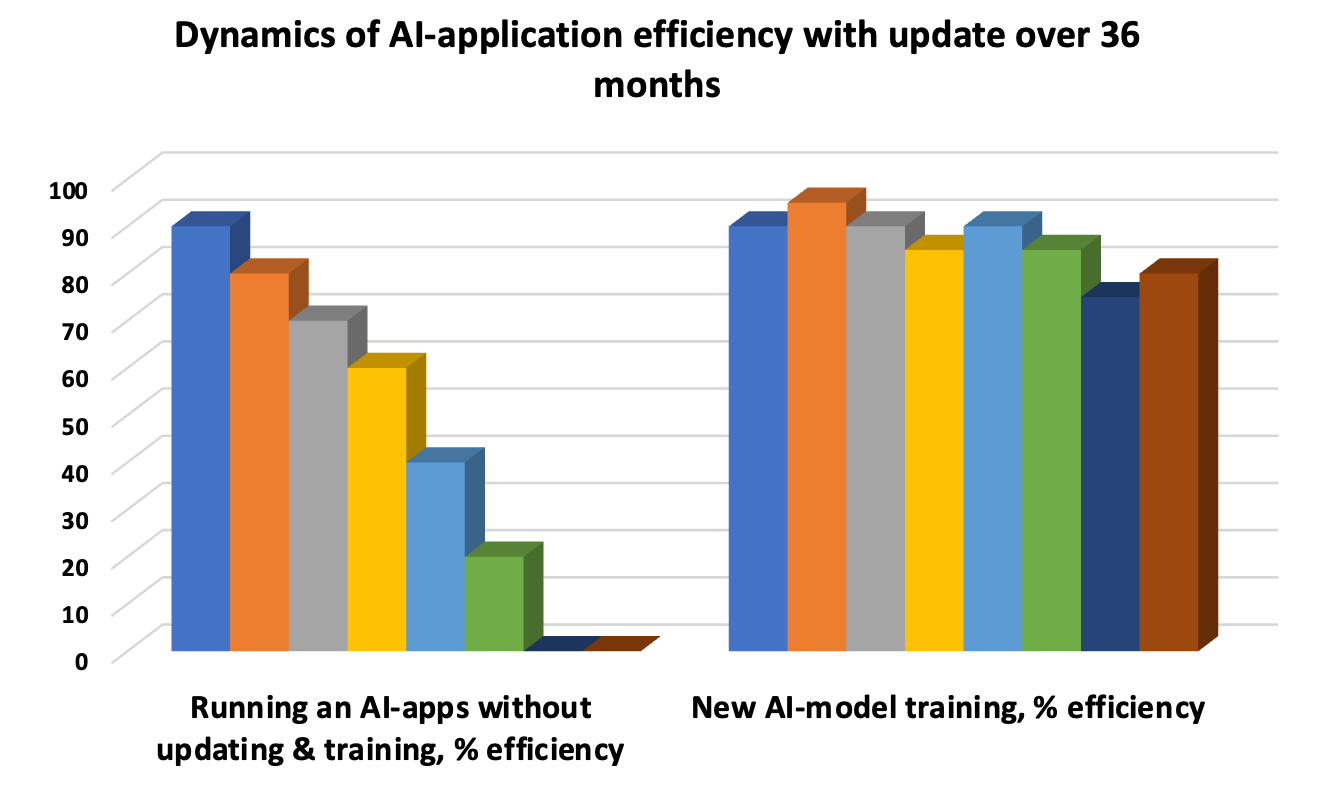
Die Aktualisierung des KI-Modells ist eine Notwendigkeit, um ein „Abdriften“ zu vermeiden, wenn die zugrunde liegenden Muster veraltet sind und die Genauigkeit der Antwort abnimmt. Daher verlängert iteratives Testen den Lebenszyklus des Modells. Automatisierte Unit-Tests, regelmäßige Integrationstests zur Bewertung der Gesamtleistung einzelner Funktionen und UAT-Abnahmetests sind die drei obligatorischen „Wale“ der Leistungsbewertung und des Testens.
ZBrain – Open Source und nahtlose Integration
ZBrain ist ein Beispiel für eine ausgefeilte Plattform für die Symbiose von Unternehmensprozessen und -informationen mit eingebetteter KI-Funktionalität. Open-Source-Code mit Vorlagen und speicherintegrierten LLMs bieten:- Speicherung und Austausch von Fiat- und Kryptowährungen in Paaren, mit blockchainbasierter Transaktionsregistrierung;
- produktives Arbeiten auf einem klaren und detaillierten Infopanel;
- Verwaltung von plattformübergreifenden und plattformübergreifenden Anwendungen auf Mikro- und Makroebene;
- Implementierung kognitiver Technologien und projektorientierter Lösungen.
Die Transformation von Geschäftsprozessen wird deutlich demokratisiert und vereinfacht, wenn Benutzer selbst KI-Modelle für Marketing- und Produktionslogik und -abläufe entwickeln und bereitstellen, ohne Code schreiben zu müssen. Beispielsweise wählt die nahtlose Integration von Flow dynamisch die richtigen Daten aus und bereitet darauf basierend KI-Lösungen vor.
Quantencomputing: Neumann-Engpässe loswerden und Energiekosten senken
Quantencomputing wird zur Verarbeitung großer Datensätze eingesetzt. Algorithmen, die in Quantentechnologien verwendet werden, beschleunigen KI-Lernprozesse in der Medizin, bei Materialien, bei biologischen und chemischen Prozessen und reduzieren CO2- und Treibhausgasemissionen. Um das Lernen auf Milliarden von Parametern zu ermöglichen, werden ultra-leistungsstarke Grafikprozessoren oder TPUs benötigt, die für die Ausführung mehrerer paralleler Operationen ausgelegt sind.Gleichzeitig muss das Neumann-Engpassproblem (VNB) überwunden werden, damit der Prozessor nicht auf den RAM warten kann, um Zugriff auf den Prozess zu gewähren. Ziel ist es, die Geschwindigkeit des Datenabrufs und der Datenübertragung aus der Datenbank oder dem Speicher zu erhöhen. Selbst die hohe Geschwindigkeit von Mehrkernprozessoren mit 32-64 GB oder mehr RAM rechtfertigt möglicherweise nicht die Investition in Kapazität, wenn die Übertragung von Informationen aus der Cloud begrenzt ist. Um das VNB-Problem zu lösen, erweitern sie den Cache, führen Multithread-Verarbeitung ein, ändern die Buskonfiguration, ergänzen den PC mit diskreten Variablen, verwenden Memristoren und rechnen in einer optischen Umgebung. Darüber hinaus gibt es auch die Modellierung biologischer Prozesse nach dem Prinzip der Quantisierung.
Das digitale KI-Paradigma in der Parallelverarbeitung erhöht den Energieverbrauch und die Zeit der Lernprozesse. Aus diesem Grund sind Qubits in Superpositionen (mehrere Positionen in einem Zeitraum) und Verschränkungspositionen klassischen Bits vorzuziehen, vorausgesetzt, die Stabilität bleibt erhalten. Für die KI sind Quantentechnologien aufgrund der geringeren Kosten für Entwicklung und Datenanalyse in mehreren Konfigurationen besser geeignet. Die „Tensorisierung“ komprimiert KI-Modelle und ermöglicht die Bereitstellung auf einfachen Geräten bei gleichzeitiger Verbesserung der Qualität der Rohdaten.
Regeln der Cyberabwehr
Achten Sie auf die Cyberabwehr – KI-Algorithmen erkennen Muster in bedrohlichen Aktivitäten, prognostizieren potenzielle Cyberbedrohungen und schützen die Privatsphäre, was ein rechtliches und ethisches Gebot ist. Die Vorschriften der DSGVO und des CCPA müssen wie andere Schutzprotokolle eingehalten werden, indem Folgendes garantiert wird:- Kunden anonymisieren und sicherstellen, dass es keine Schlupflöcher gibt, durch die Dritte sie identifizieren können;
- sensible Punkte in Passdaten, E-Mails, Telefonnummern und anderen Dokumenten unterscheiden, die nicht offengelegt werden können;
- gemeinsame Analyse von Informationssegmenten in zwei oder drei getrennten Systemen, ohne die gesamte Basis offenzulegen.
Pattern Poisoning (Einführung bösartiger Elemente) in KI, das Vorhandensein von Schwachstellen des Gegners führt zu Fehlklassifizierungen. Aus diesem Grund sollte ein ganzheitlicher Ansatz Schutzprinzipien von der Entwicklungsphase bis hin zu Tests und Bereitstellung umfassen, um Herausforderungen und Risiken zu minimieren.
KI-Arbeit: Experten und NLP, durch genetische Algorithmen und Kreativität
Identifizierte Schlüsselmerkmale des KI-Trainings in dem Fall, in dem das Ziel darin besteht, Aufgaben auf Expertenebene zu lösen, geleitet durch Argumentation und Analyse einer empirischen Datenbank mit mehreren Millionen Daten unter visueller Berücksichtigung spezifischer Situationen. Beispielsweise wird der Vegetationsindex NDVI verwendet, um das Niveau des Vegetationswachstums zu bestimmen. Aber es gibt Nuancen – es ist eine Sache, wenn die Vegetation Getreide oder Ölsaaten anbaut, und eine andere, wenn es sich um Unkraut handelt. Die KI in der App sollte anhand der Farbe unterscheiden können, was besser wächst, und eine Antwort geben können. Ebenso – den Gesichtstyp erkennen, lineare Parameter der Figur für Empfehlungen zur Wahl von Kosmetika oder Kleidung für Outfits.Das NLP-Prinzip wird in die Algorithmen eingeführt, wenn die Arbeit der KI als Psychologe geplant wird – die natürliche Sprache wird analysiert und die psycho-emotionale Stimmung des Patienten wird geklärt. Dann werden die Fragen mit einer generierten Antwort beantwortet, die dem menschlichen Klang und der Intonation nahe kommt. Es gibt auch genetische Algorithmen, wenn Bots erstellt werden, um Millionen von Problemen zu lösen, und dann die schlechtesten abgeschnitten werden, sodass die besten übrig bleiben. Die Kombination aus erfolgreichen Entwicklungen und der anschließenden Generierung neuer angepasster und getesteter Modelle, basierend auf den Vorgängern und einer Reihe von Iterationen, führt zu einer vollständigen Lösung des Problems.
Die Entwicklung von KI-Programmen sollte ein kreativer Ansatz sein. Sie können beispielsweise einen Chatbot in Form eines lustigen Tiers oder Vogels, eines lustigen Elfs oder einer temperamentvollen Pflanze oder etwas Pragmatischem wie einem Arbitrage-Bot für den Handel erstellen. Wer Kurt Vonnegut gelesen hat, erinnert sich an die Geschichte über einen Supercomputer, der menschliches Denken erlangte. Wenn die Figur also Zeilen spricht, vorherige Kommunikation nutzt, Tipps und kurze Pressemitteilungen über neue Produkte gibt, werden die Kunden KI lieben und sich an sie gewöhnen und ihr vertrauen. Das Umsatzwachstum wird mindestens 10-20 % betragen.
MVP, CRISP-DM und Preise
Der erste Schritt nach der Entwicklung und Implementierung von KI in einer Anwendung ist die Einführung eines MVP mit Analyse und Support, Funktionsverbesserung und permanenten Tests. Wenn das Unternehmen plant, eine KI-Anwendung 10 bis 20 Jahre lang aufrechtzuerhalten, sind regelmäßige vierteljährliche Aktualisierungen der Datenbanken und Tests verschiedener Art gemäß der CRISP-DM-Methodik erforderlich.Um die finanziellen und zeitlichen Kosten zu ermitteln, wenden Sie sich mit Ihrer Aufgabe und Ihren Fragen an Merehead: Die Kosten für die KI-Entwicklung beginnen bei 20.000 USD und dauern bis zu einem Viertel der Zeit. Die Anwendungsentwicklungszeit für Anwendungen mittlerer Komplexität mit Logikketten auf drei bis fünf Ebenen ist doppelt so lang und der Preis erreicht 100.000 USD. Für komplizierte mathematische Projekte mit Expertenanalyse und 99,9 % Genauigkeit der Antworten - bis zu 500.000 USD. Lassen Sie uns einen Projekt-Fahrplan entwickeln und die erwarteten Rentabilitätsergebnisse planen, bevor wir mit der Arbeit beginnen.


