The emergence of new technologies is driving growth in all areas of IT, including machine learning. Developers are doing a lot of work to create a rough forecast of deep learning and neural network
trends for 2024.
Those who understand the trends of neural networks and deep learning in 2024 are several steps ahead of their competitors. This provides an opportunity to create a project with
the future of machine learning in mind to meet the standards of this field.
The Merehead team has also analyzed and provided the most accurate results. Keep reading this article to prepare for new narratives and make 2024 the best year of your career.
What is Deep Learning?
Deep learning is a field of machine learning in which neural networks and algorithms based on the human brain are trained using large amounts of data.
Just as we learn from experience, a deep learning algorithm repeatedly performs a task, each time tweaking it slightly to improve the result.
Deep learning models successfully solve tasks such as:
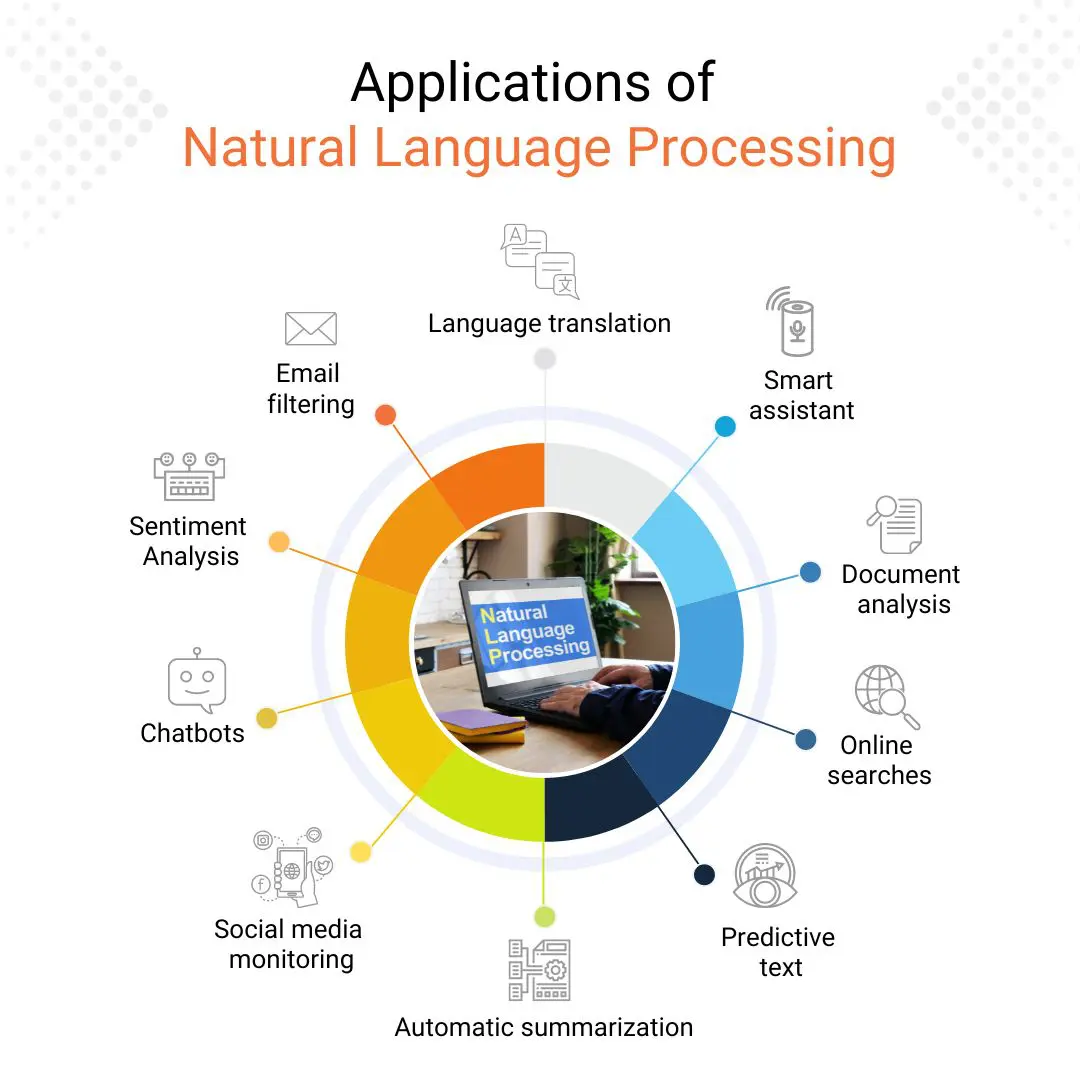
- Image and speech recognition
- Natural language processing
- Recommendation systems
Among the well-known deep learning architectures are convolutional neural networks (CNNs) for image analysis, recurrent neural networks (RNNs) for sequential data processing, and transformer models for natural language understanding.
Deep learning trends in 2024 may increase the number of significant advances and breakthroughs due to the availability of big data, computational resources, and advanced algorithms.
How have deep learning trends shaped?
Understanding how deep learning trends have formed in the past can give us a better idea of what we can expect from this field in the future. Especially for this purpose, our team conducted a detailed analysis to predict the situation in 2024 as accurately as possible.
Essential deep learning trends in 2023.
Trends in the development of deep learning have been shaped by several factors, including:
- The availability of large data sets. The availability of large-scale labeled datasets, such as ImageNet for computer vision or Common Crawl for natural language processing, has become crucial for training deep learning models.
- Increased computational power. The availability of high-performance graphics processing units (GPUs) and specialized hardware such as TPUs (Tensor Processing Units) has enabled researchers and practitioners to train deep learning models on a larger scale and faster.
- Finding a neural architecture. NAS algorithms combined with computational resources have enabled researchers to automatically find novel and optimized network architectures to solve relevant problems.
These factors have contributed to deep learning areas' rapid growth and development. This has led to breakthroughs in image and speech recognition, natural language understanding, generative modeling, and reinforcement learning.
Deep Learning and Neural Network Trends in 2024
In this section, you will find the most likely trends of deep learning and neural networks in 2024, following which you can improve machine learning. Read this article till the end to build a
development vector in AI shortly.
Advances in architecture design
2024 we can expect the search for new neural network architectures to continue. Researchers will focus on designing architectures that solve specific problems, such as:
- Improving memory efficiency
- Improved handling of sequential data
- Increased interpretability
This research may lead to discovery of new architectures that outperform existing models in various domains and tasks.
Basic deep learning models architecture.
Source.
As the complexity of deep learning models grows, an increasing focus will be on developing more efficient and scalable architectures. Researchers will seek to reduce models' computational requirements and memory footprint without sacrificing performance.
This will enable deep learning models to be deployed on resource-constrained devices, edge computing environments, and large-scale distributed systems.
Improved interpretability and explainability
Understanding and interpreting their processes becomes critical as deep learning models become more complex. In 2024, efforts will be made to develop methods such as:
- Visualizing and explaining the internal representations of deep learning
- The importance of features and decision boundaries
These methods will increase the interpretability of deep learning models and provide better ways for developers to interact with the technology.
Model explainability compared to performance. Source.
Ethical considerations and regulatory requirements will drive the integration of explainability into deep learning. Researchers will work to develop frameworks and methodologies that allow models to provide explanations or justifications for their predictions.
This will help increase the trust and transparency of deep learning systems, especially in critical areas such as healthcare, finance, and autonomous systems.
Integrating Deep Learning with other technologies
Deep learning models will increasingly be combined with AR and VR technologies to create immersive experiences and intelligent virtual environments. This integration will enable applications such as:
- Real-time object recognition and tracking
- Understanding what is happening and context-aware interaction in AR and VR
The integration of deep learning and blockchain will also gain momentum in 2024. This is supported by the active process of blockchain regulation in the traditional sector of finance, medicine, supply chain, etc.
The advantages of integrating deep learning and blockchain.
Source.
- Decentralization
- Secure data exchange and storage
- Transparency and privacy
The integration will enable collaborative deep learning models, federated learning approaches, and incentivized data sharing while maintaining privacy and ownership.
Extended Natural Language Processing Capabilities
Natural language processing will continue to evolve in 2024, focusing on improving language understanding and generation models. This includes:
- Improved understanding of the context
- Capturing the nuances and subtleties of language more accurately
- Developing models that can generate more coherent and contextually relevant text
Deep learning models will be refined to improve sentiment analysis capabilities, enabling a more accurate understanding of emotions, opinions, and intentions expressed in text.
Natural Language Processing Applications.
Source.
In addition, efforts will be made to improve the ability of models to understand context in conversation, which will enable the creation of better chatbots, dialog systems, and language assistants.
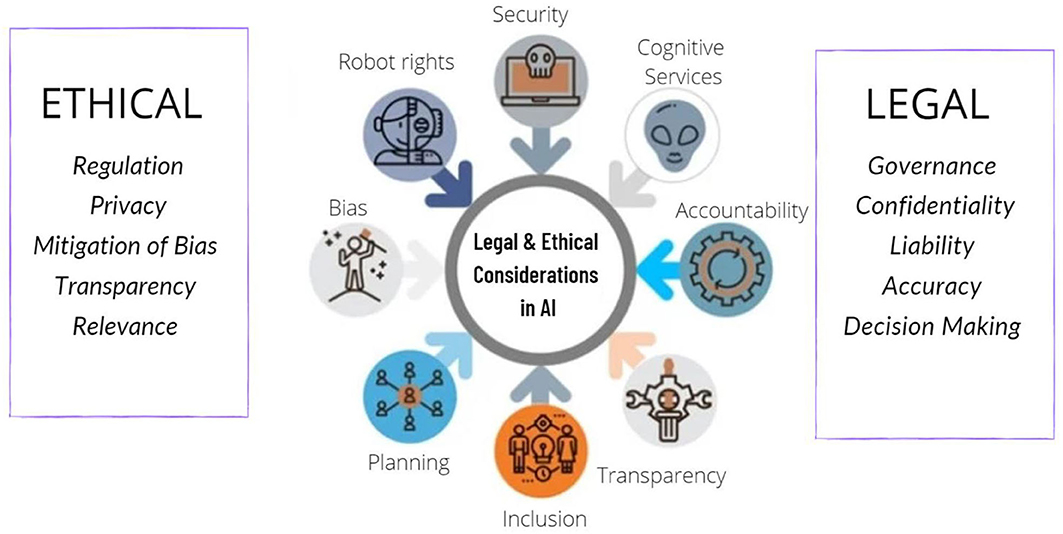
Increased Attention to Ethical Considerations
As deep learning technologies become more widespread, there will be an increasing focus on developing and implementing ethical principles and rules. This will include:
- Fairness considerations
- Transparency
- Regulation
- Reducing bias in deep learning models and applications
Researchers and practitioners will strive to reduce bias and ensure fairness in deep learning models. Efforts will be made to develop methods to identify and eliminate bias in training data, interpret model decisions, and ensure fair results for different demographic groups.
Ethical considerations in the application of artificial intelligence in healthcare.
Source.
- Finance
- Criminal justice
- Health care
And in all areas where biased decisions can have significant consequences for society.
Integration of Hybrid Models
Hybrid model integration combines different types, models, and deep learning architectures to leverage their strengths and improve overall performance.
Such deep learning
trends in 2024 will drive the scalability, popularity, and creation of more effective approaches in the field. Hybrid models complement each other to solve complex problems and achieve better results.
The architecture of a multimodal hybrid deep neural network.
Source.
- Model stacking. This approach involves training multiple deep learning models independently and combining their results to form a cluster. Each model may have a different architecture or be trained on different subsets of data.
- Pre-trained models and fine-tuning. These models share common visual characteristics that can be transferred to a new task. Fine-tuning or adapting them allows efficient use of learned representations and faster convergence.
- Combining architectures. Different deep-learning architectures can be combined to leverage their unique characteristics. For example, combining a recurrent neural network (RNN) and a convolutional neural network (CNN) allows the model to capture spatial and temporal dependencies in sequential data.
Integrating hybrid models in deep learning requires careful consideration of the task, the available models' characteristics, and the system's resources and constraints.
Experimentation and fine-tuning are often necessary to find the optimal combination of models and methods to solve a particular problem and improve performance efficiently.
Neuroscience-based Deep Learning
Neuroscience-based deep learning is a type of ML that uses data from neuroscience experiments to train artificial neural networks. It allows researchers to develop models based on the workings of the human brain.
It involves using principles and concepts based on studying the brain and neural systems to improve the architecture, algorithms, and overall performance of deep learning models.
Let's look at a few key aspects of deep learning based on neuroscience:
- Neural network architecture. The technology aims to develop neural network architectures that reflect the different connectivity structures observed in the brain. For example, convolutional neural networks are inspired by hierarchical data processing in the visual cortex, and recurrent connections inspire recurrent neural networks in the brain.
- Learning algorithms. Neuroscience provides insight into how the brain learns and processes information. By incorporating these principles into deep learning algorithms, researchers aim to improve its effectiveness.
- Cognitive and behavioral aspects. Understanding how the brain perceives, processes, and interacts with the environment can help develop deep learning models for tasks such as pattern recognition, natural language comprehension, or reinforcement learning.
Neuroscience-based deep learning is an interdisciplinary field that bridges the gap between neuroscience and deep learning.
By utilizing advances in neuroscience, researchers aim to develop more biologically based, practical, interpretable, and human-like models of deep learning.
ViT
Vision Transformer (ViT) is a deep learning architecture that applies the Transformer model created for natural language processing tasks. It represents a departure from traditional convolutional neural networks, as it utilizes self-monitoring mechanisms to capture long-range dependencies and contextual information in images.
The basic idea of this architecture is to treat an image as a sequence of patches and apply the Transformer model to process them.
Vision Transformer explained.
Source.
- Patch embedding. The input image is partitioned into a grid of fixed-sized non-overlapping patches. Each patch is then linearly projected onto an embedding vector with lower dimensionality. This allows the model to treat the image as a sequence of embeddings.
- Position coding. Position coding represents the relative or absolute position of each fragment in the image, which allows the model to understand the spatial relationships between them.
- Transform coder. The patch embeddings and positional coding are fed into the layer stack of the transformer coder. Each of its layers comprises multi-headed self-dual mechanisms and feedforward neural networks. This allows visiting different parts of the image and capturing dependencies across the space.
Vision Transformer has shown excellent performance on several computer vision tasks, including image classification, segmentation, and object detection.
Like neural network trends in 2024, such deep learning architectures can significantly accelerate the development of new IT solutions. If you want to build a technology product using deep learning, Merehead is your best choice!
Self-supervised Learning
Self-supervised learning is a paradigm in which a model learns to extract meaningful representations or features from unlabeled data without the need for explicit labels provided by humans.
Unlike supervised learning, in which models are trained on labeled data containing "true" annotations, self-supervised learning uses an internal structure. With unlabeled data, the model learns to capture high-level semantic information and valuable representations that can be carried over to subsequent tasks.
An example of how self-supervised learning works.
Source.
- Pre-learning. During pre-training, the model learns to extract meaningful representations or features from the input data to solve an auxiliary problem.
- Fine-tuning. Fine-tuning allows the model to adapt and specialize the learned representations to a specific task. This stage helps to transfer the knowledge gained from self-supervised learning to the solution of a specific task.
Self-controlled learning has attracted considerable attention and success in a variety of deep learning domains, including:
- Computer vision
- Natural language processing
- Speech recognition
The main advantages of self-supervised learning include using large amounts of unlabeled data, which reduces dependence on costly and time-consuming labeling efforts.
In addition, self-supervised learning facilitates the formation of robust representations that capture relevant information from the data distribution. This leads to improved performance on subsequent tasks.
High-performance NLP models
High-Performance NLP models are advanced models designed to achieve state-of-the-art performance on various natural language processing tasks.
The Merehead team has prepared a list of the best high-performance NLP models to set deep learning trends in 2024.
Among them:
- Transformer-based models. Transformer-based models such as "Transformer" and their variants like BERT, GPT, and RoBERTa have made significant strides in NLP.
- Pre-trained language models. Models such as GPT, BERT, and XLNet are pre-trained on vast amounts of textual data using unsupervised or self-supervised learning approaches. They provide deep language understanding and can be fine-tuned for specific NLP tasks.
- Convolutional Neural Networks (CNNs). Models such as Kim's CNN and Yoon Kim's CNN use convolutional operations to capture local and compositional features of text, achieving competitive performance on tasks such as text classification and sentiment analysis.
Training deep learning models in 2024 in this domain requires significant computational resources, including powerful GPUs or specialized hardware such as TPUs.
They are typically trained on large, labeled, and unlabeled datasets to capture various language patterns and achieve better generalization.
Deep Learning System 2
At the 2019 Neural Information Processing Systems Conference (NeurIPS 2019), Yoshua Bengio, one of the three pioneers of deep learning, gave a keynote speech that shed light on the possible transition of System 1 deep learning to System 2.
Two systems of thinking. Source.
The terms "System 1" and "System 2" were popularized by psychologist Daniel Kahneman in his 2011 book “Thinking, Fast and Slow”. They are used to refer to two different modes of thinking in human cognition, namely:
- System 1. Fast, intuitive, and automatic decision-making, often relying on heuristics and experience.
- System 2. Slow, deliberative, and analytical decision-making requires conscious effort and reasoning.
System 2 involves more deliberate decision-making in the design and implementation of deep learning models, which includes:
- manual fine-tuning
- extensive analysis of model behavior
- more human intervention in the learning process
System 2 deep learning is still in its early stages. Still, if it becomes a reality, it could solve some critical problems of neural networks, including generalization beyond distribution, causal inference, robust transfer learning, and symbol manipulation.
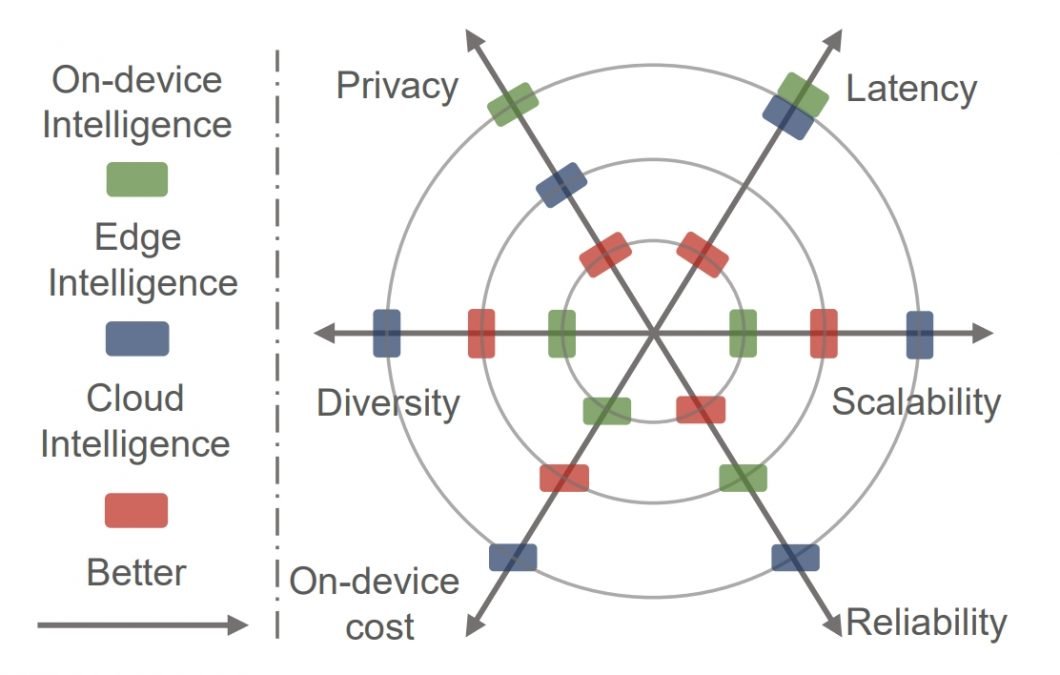
Comparing the capabilities of cloud-based, appliance-based, and edge-based intelligent systems. Source.
The advantages of deploying deep learning at the edge are as follows:
- Low latency. Deep learning services are deployed close to the users requesting them. This significantly reduces the latency and cost of sending data to the cloud for processing.
- Privacy preservation. Privacy is enhanced because the raw data required to run deep learning services is stored locally on edge or user devices, not in the cloud.
- Offline functionality. Offshore deployment allows edge devices to operate autonomously even when disconnected from the cloud. This ensures business continuity and prevents service interruptions during network outages.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}